

ElasticSearch概述
ElasticSearch 是一个分布式、高扩展、高实时的搜索与数据分析引擎,使用 Java 开发,基于 Lucene ,对 Lucene 封装,隐藏了 Lucene 的复杂性,取而代之的提供一套简单一致的 RESTful API。
基本概念
集群(cluster)
一个集群是由一个或多个节点组织在一起,它们共同持有你整个的数据,并一起提供索引和搜索功能。一个集群由一个唯一的名字标识,这个名字默认就是“elasticsearch”
节点(node)
一个节点是你集群中的一个ES实例,本质上一个节点就是一个java进程,一台服务器上是允许运行多个ES进程
###Master Node:主节点
一个集群只有一个master节点
master节点处理索引维护的请求、数据分片的分配、维护Cluster State , 控制整个集群的元数据。只有Master Node节点可以修改节点状态信息及元数据(metadata)的处理,比如索引的新增、删除、分片路由分配、所有索引和相关 Mapping 、Setting 配置等等。
从资源占用的角度来说:master节点不占用磁盘IO和CPU,内存使用量一般, 没有data 节点高
###Master eligible nodes:合格主节点
合格节点,每个节点部署后不修改配置信息,默认就是一个 eligible 节点。有资格成为Master节点但暂时并不是Master的节点被称为 eligible 节点,该节点可以参加选主流程,成为Mastere节点.该节点只是与集群保持心跳,判断Master是否存活,如果Master故障则参加新一轮的Master选举。
从资源占用的角度来说:eligible节点比Master节点更节省资源,因为它还未成为 Master 节点,只是有资格成功Master节点
###Data Node:数据节点
数据节点,改节点用于建立文档索引, 接收 应用创建连接、接收索引请求,接收用户的搜索请求
数据节点真正存储数据,ES集群的性能取决于该节点的个数(每个节点最优配置的情况下),
数据节点的分片执行查询语句获得查询结果后将结果反馈给Coordinating节点,在查询的过程中非常消耗硬件资源,如果在分片配置及优化没做好的情况下,进行一次查询非常缓慢(硬件配置也要跟上数据量)。
保存包含索引文档的分片数据,执行CRUD、搜索、聚合相关的操作, 属于:内存、CPU、IO密集型,对硬件资源要求高。
从资源占用的角度来说:数据节点会占用大量的CPU、IO和内存
###Coordinating Node:协调节点
协调节点,该节点专用与接收应用的查询连接、接受搜索请求,但其本身不负责存储数据
接受客户端搜索请求后将请求转发到与查询条件相关的多个data节点的分片上,然后多个data节点的分片执行查询语句或者查询结果再返回给协调节点,协调节点把各个data节点的返回结果进行整合、排序等一系列操作后再将最终结果返回给用户请求。
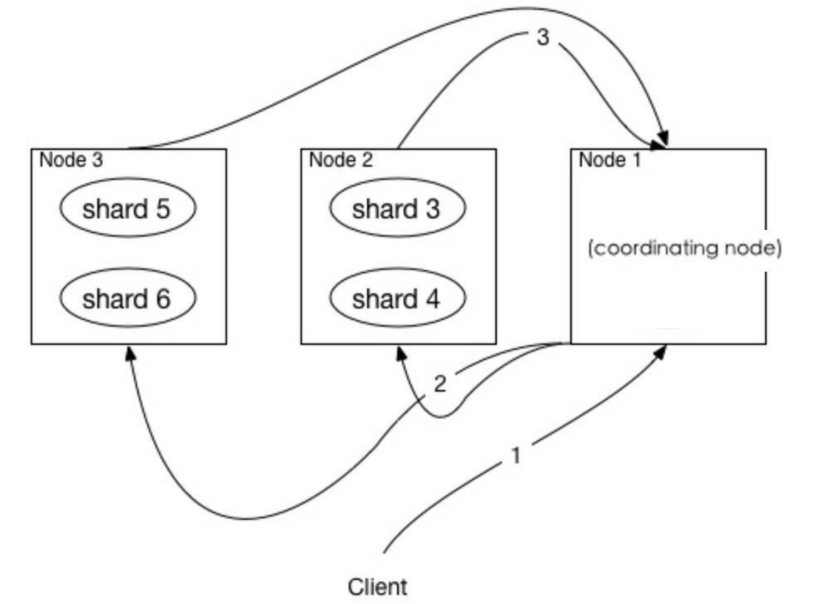
从资源占用的角度来说:协调节点,可当负责均衡节点,该节点不占用io、cpu和内存
###Ingest Node:提取节点
ingest 节点可以看作是数据前置处理转换的节点,支持 pipeline管道 设置,可以使用 ingest 对数据进行过滤、转换等操作,类似于 logstash 中 filter 的作用,功能相当强大。
Ingest节点处理时机——在数据被索引之前,通过预定义好的处理管道对数据进行预处理。默认情况下,所有节点都启用Ingest,因此任何节点都可以处理Ingest任务。
如:修改字段名、添加特定字段
索引(index)
一个索引就是一个拥有几分相似特征的文档的集合
一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。索引类似于关系型数据库中Database的概念
每个索引都有自己的mapping,用于定义文档的字段和类型,每个索引所有自己的setting,用于定义分片数、副本数
PUT index1
{
"settings" : {
"number_of_shards": 2, // 主分片
"number_of_replicas" : 1 // 副本分片
},
"mappings" : {
"properties": {
"p1": {
"type": "date"
},
"p2": {
"type": "text" // 未指定analyzer使用ES预设
},
"p3": {
"type": "keyword"
},
"p4": {
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word",
"type": "text"
}
}
}
}
}
Mapping
mapping非常类似于语言中的数据类型:声明一个变量为int类型的变量, 以后这个变量都只能存储int类型的数据这样。
同语言的数据类型相比,mapping还有一些其他的含义,mapping不仅告诉ES一个field中是什么类型的值, 它还告诉ES如何索引数据以及数据是否能被搜索到
动态Mapping: 文档在写入时如果index不存在,会自动创建一个索引,动态mapping机制最大的好处是无需手动定义mapping,ES会根据文档信息自动进行类似的推算
数据类型
简单类型:text/keyword、date、integer、floating、Boolean、IPv4、IPv6
复杂类型:对象、嵌套Nested
特殊类型:geo_point、geo_shape、percolator
数组:ES中数组不是个数据类型,但任何字段都允许包含多个相同类型的数据
分片
代表索引分片,es可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上,构成分布式搜索。
分片的数量只能在索引创建前指定,并且索引创建后不能更改
主分片:可以将⼀份索引的数据,分散在多个 Data Node 上,实现存储的⽔平扩展;主分⽚数在索引创建时候指定,后续默认不能修改,如要修改,需重建索引
副本分片:提⾼数据的可⽤性。⼀旦主分⽚丢失,副本分⽚可以提升成主分⽚。副本分⽚数可以动态调整。每个节点上都有完备的数据。⼀定程度可以提⾼读取的吞吐量
如何规划⼀个索引的主分⽚数和副本分⽚数
● 主分⽚数过⼩:如果该索引增⻓很快,集群⽆法通过增加节点实现对这个索引的数据扩展
● 主分⽚数设置过⼤:导致单个 Shard 容量很⼩,引发⼀个节点上有过多分⽚,影响性能
● 副本分⽚数设置过多,会降低集群整体的写⼊性能
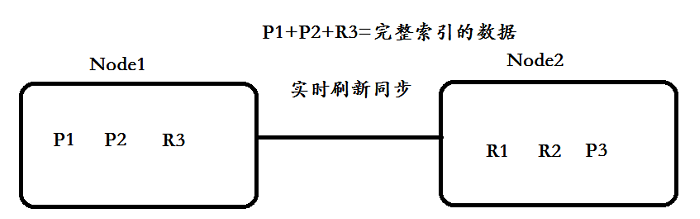
文档会根据一些算法,均匀的分布在分片上;shard = hash(_routing) % number_of_primary_shards默认的_routing是文档Id,主分片数会参与路由计算,这也是为什么主分片数不能修改原因
类型(type)
在一个索引中,你可以定义一种或多种类型。一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定。类型类似于关系型数据库中Table的概念。这个概念在ES 7.0之后就没有了,彻底迎来无类型时代。即便是老版本,也是建议一个索引只含有一个文档,默认是“_doc”
文档(document)
一个文档是一个可被索引的基础信息单元。文档以JSON格式来表示,而JSON是一个到处存在的互联网数据交互格式。 在一个index/type里面,只要你想,你可以存储任意多的文档。文档类似于关系型数据库中Record的概念。
每个字段也有对应的字段类型,如:字符串、数值、布尔、日期、二进制、范围, 每个文档也有一个唯一ID,可以自己指定、也可以有ES自助生成
倒排索引
正排索引: 由文档-》关键字
倒排索引: 由关键词-》文档
倒排表
一个文档通常由多个词组成,倒排表记录的是某个词在哪些文档里出现过以及出现的位置
词条(Term)
Term是表达语义的最小单位,对于英文来说是一个单词,对于中文来说一般指分词后的一个词
词典
是词条 Term 的集合。搜索引擎的通常索引单位是单词,单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针
分词 Analysis
对文本进行分析,转换成一系列单词的过程;它是通过Analyzer来实现的,可以灵活的指定活按需定制分词器
分词器
分词器是es中的一个组件,通俗意义上理解,就是将一段文本按照一定的逻辑,分析成多个词语,同时对这些词语进行常规化的一种工具;ES会将text格式的字段按照分词器进行分词,并编排成倒排索引
插入文档时,将text类型的字段做分词然后插入倒排索引,此时就可能用到analyzer指定的分词器
在查询时,先对要查询的text类型的输入做分词,再去倒排索引搜索,此时就可能用到search_analyzer指定的分词器, 如果不指定这使用字段mapping 时指定的分析器
内置分词器
Standard ES默认分词器,按单词分类并进行小写处理
Simple 按照非字母切分,然后去除非字母并进行小写处理
Stop 按照停用词过滤并进行小写处理,停用词包括the、a、is
Whitespace 按照空格切分
Language 据说提供了30多种常见语言的分词器
Patter 按照正则表达式进行分词,默认是\W+ ,代表非字母
Keyword 不进行分词,作为一个整体输出
POST /_analyze
{
"analyzer": "standard",
"text": "张三老铁学习java!"
}
搜索
搜索可以分为2大类,精确值(Exact Values)搜索与全文本(Full Text)搜索
精确值(Exact Values)包括结构化数据:数字、日期、一个字符串, ES中的keyword,不会进行分词处理
Full Text包括非结构化文本数据, ES中的text,会进行分词处理
精确值(Exact Values)搜索
GET /bank/_search
{
"query": {
"match": {
"age": 33
}
}
}
全文本(Full Text)搜索
GET /bank/_search
{
"query": {
"fuzzy": {
"firstname": "hol"
}
}
}
搜索的两阶段
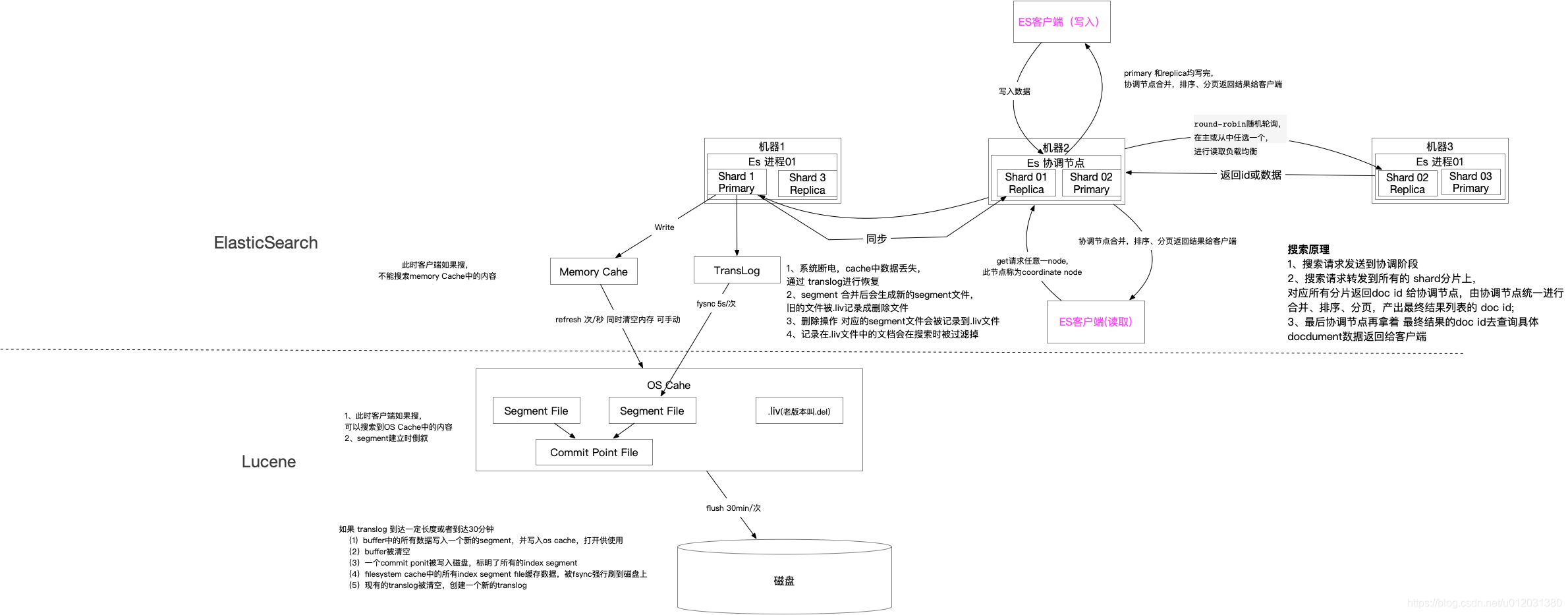
一次搜索请求在两个阶段中执行(query 和 fetch),这两个阶段由接收客户端请求的节点 (协调节点)协调。
在请求query 阶段,协调节点将请求转发到保存数据的数据节点。 每个数据节点在本地执行请求并将其结果返回给协调节点。
在收集fetch阶段,协调节点将每个数据节点的结果汇集为单个全局结果集。
### query 查询阶段
假定我们的ES集群有三个node,number_of_primary_shards为3,replica shard为1,我们执行一个这样的查询请求
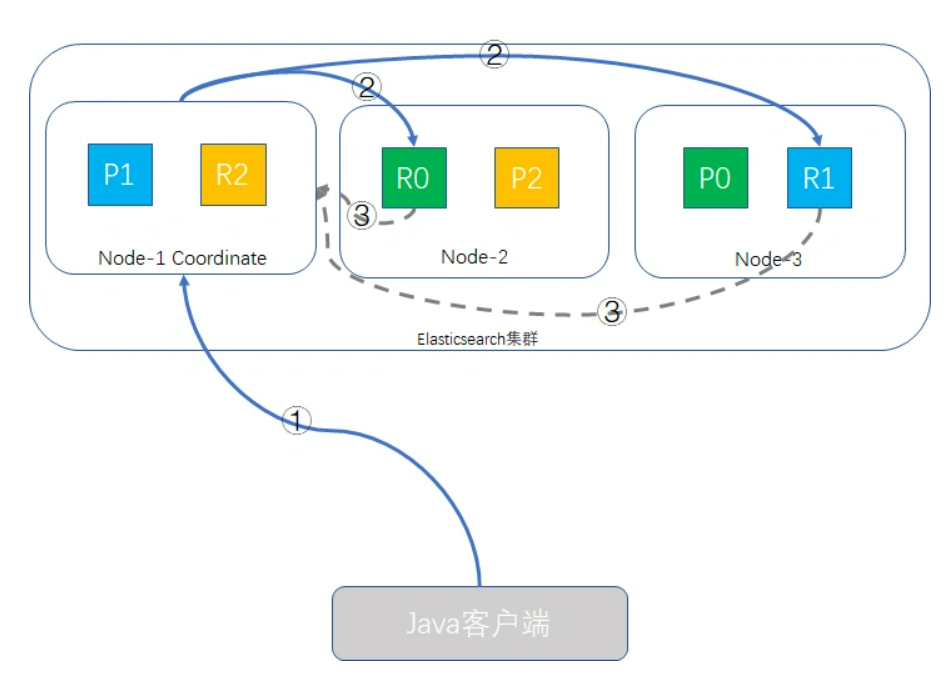
Java客户端发起查询请求,接受请求的node-1成为Coordinate Node(协调者),该node会创建一个priority queue
Coordinate Node将请求分发到所有的primary shard或replica shard中,每个shard在本地创建一个同样大小的priority queue,长度也为from + size,用于存储该shard执行查询的结果。
每个shard将各自priority queue的元素返回给Coordinate Node,元素内只包含文档的ID和排序值,Coordinate Node将合并所有的元素到自己的priority queue中,并完成排序动作,最终根据from、size值对结果进行截取
哪个node接收客户端的请求,该node就会成为Coordinate Node。
Coordinate Node转发请求时,会根据负载均衡算法分配到同一分片的primary shard或replica shard上
### fetch取回阶段
在完成了查询阶段后,此时Coordinate Node已经得到查询的列表,但列表内的元素只有文档ID和_score信息,并无实际的_source内容,取回阶段就是根据文档ID,取到完整的文档对象的过程。
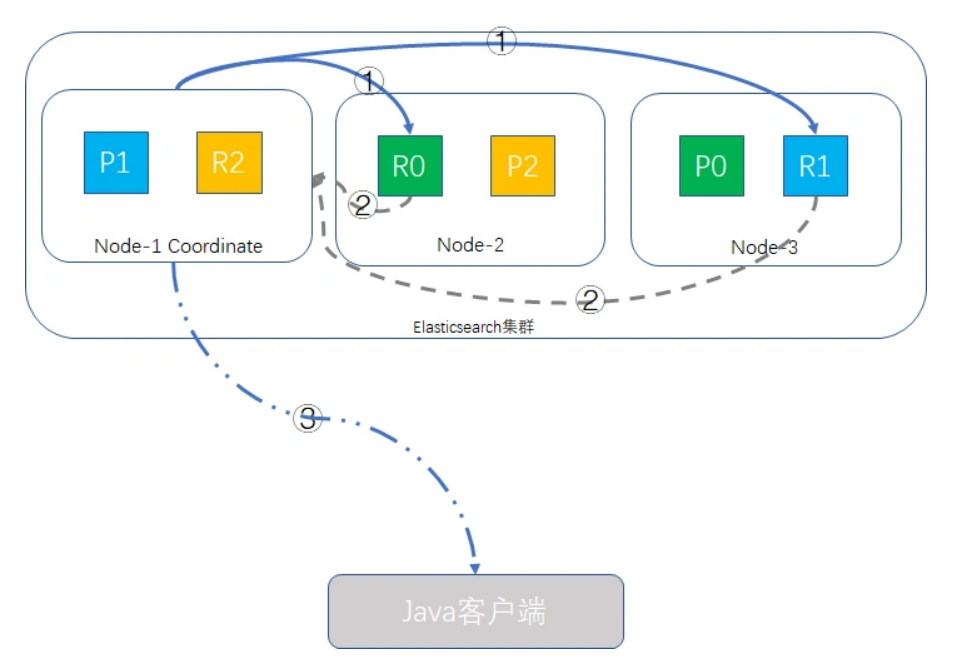
fetch取回阶段的过程示意图如下:
Coordinate Node根据from、size信息截取要取回文档的ID,如{“from”: 980, “size”: 20},则取第981到第1000这20条数据,其余丢弃,from/size为空则默认取前10条,向其他shard发出mget请求。
shard接收到请求后,根据_source参数(可选)加载文档信息,返回给Coordinate Node。
一旦所有的shard都返回了结果,Coordinate Node将结果返回给客户端。
注意:
使用from和size进行分页时,传递信息给Coordinate Node的每个shard,都创建了一个from + size长度的队列,并且Coordinate Node需要对所有传过来的数据进行排序,工作量为number_of_shards * (from + size),然后从里面挑出size数量的文档,如果from值特别大,那么会带来极大的硬件资源浪费,鉴于此原因,强烈建议不要使用深分页。
分页查询
### page+size
默认采用的分页方式
ES有个限制只接受一定数量的文档搜索,默认是10000
GET /student/student/_search
{
"query":{
"match_all": {}
},
"from":5000,
"size":10
}
### 滚动查询
scroll搜索会在第一次搜索的时候,保存一个当时的视图快照,之后只会基于该旧的视图快照提供数据搜索,如果这个期间数据变更,是不会让用户看到的
一个滚屏搜索允许我们做一个初始阶段搜索并且持续批量从ES里拉取结果直到没有结果剩下。这有点像传统数据库里的cursors
#### ### 首次请求
点击查看代码
GET /student/student/_search?scroll=5m
{
"query": {
"match_all": {}
},
"size": 2
}
#### ### 返回
点击查看代码
{
"_scroll_id" : "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAC0YFmllUjV1QTIyU25XMHBTck1XNHpFWUEAAAAAAAAtGRZpZVI1dUEyMlNuVzBwU3JNVzR6RVlBAAAAAAAALRsWaWVSNXVBMjJTblcwcFNyTVc0ekVZQQAAAAAAAC0aFmllUjV1QTIyU25XMHBTck1XNHpFWUEAAAAAAAAtHBZpZVI1dUEyMlNuVzBwU3JNVzR6RVlB",
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 6,
"max_score" : 1.0,
"hits" : [
{
"_index" : "student",
"_type" : "student",
"_id" : "5",
"_score" : 1.0,
"_source" : {
"name" : "fucheng",
"age" : 23,
"class" : "2-3"
}
},
{
"_index" : "student",
"_type" : "student",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"name" : "xiaoming",
"age" : 25,
"class" : "2-1"
}
}
]
}
}
#### ### 第二次请求
点击查看代码
GET /_search/scroll
{
"scroll":"5m",
"scroll_id":"DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAC0YFmllUjV1QTIyU25XMHBTck1XNHpFWUEAAAAAAAAtGRZpZVI1dUEyMlNuVzBwU3JNVzR6RVlBAAAAAAAALRsWaWVSNXVBMjJTblcwcFNyTVc0ekVZQQAAAAAAAC0aFmllUjV1QTIyU25XMHBTck1XNHpFWUEAAAAAAAAtHBZpZVI1dUEyMlNuVzBwU3JNVzR6RVlB"
}
### search_after
search_after 是一种假分页方式,根据上一页的最后一条数据来确定下一页的位置。
在分页请求的过程中,如果有索引数据的增删改查,这些变更也会实时的反映到游标上。
为了找到每一页最后一条数据,每个文档必须有一个全局唯一值,官方推荐使用 _uid 作为全局唯一值,但是只要能表示其唯一性就可以。
不支持指定页数和向前翻页
#### ### 首次请求
点击查看代码
GET /student/student/_search
{
"query":{
"match_all": {}
},
"size":2,
"sort":[
{
"uid": "desc"
}
]
}
#### ### 返回
点击查看代码
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 6,
"max_score" : null,
"hits" : [
{
"_index" : "student",
"_type" : "student",
"_id" : "6",
"_score" : null,
"_source" : {
"uid" : 1006,
"name" : "dehua",
"age" : 27
},
"sort" : [
1006
]
},
{
"_index" : "student",
"_type" : "student",
"_id" : "5",
"_score" : null,
"_source" : {
"uid" : 1005,
"name" : "fucheng",
"age" : 23
},
"sort" : [
1005
]
}
]
}
}
#### ### 第二次请求
点击查看代码
GET /student/student/_search
{
"query":{
"match_all": {}
},
"size":2,
"search_after":[1005],
"sort":[
{
"uid": "desc"
}
]
}
分页方式比较
| 分页方式 | 性能 | 优点 | 缺点 | 场景 |
|---|---|---|---|---|
| from + size | 低 | 灵活性好,实现简单 | 深度分页问题 | 数据量比较小,能容忍深度分页问题 |
| scroll | 中 | 解决了深度分页问题 | 无法反应数据的实时性(快照版本),维护成本高,需要维护一个 scroll_id | 海量数据的导出(比如笔者刚遇到的将es中20w的数据导入到excel),需要查询海量结果集的数据 |
| search_after | 高 | 性能最好 | 不存在深度分页问题,能够反映数据的实时变更,能够反映数据的实时变更,实现复杂,需要有一个全局唯一的字段,连续分页的实现会比较复杂,因为每一次查询都需要上次查询的结果 | 海量数据的分页 |
mysql可以通过索引进行较快的跳页查询
es的倒排索引在深分页时跳页很低效!!!
需要有分页需求时,一般只开放前几十页的结果,页数过大时直接在业务层面报错。若需要显示命中的总条数,则设置track_total_hits=true。
数据路由
当客户端发起创建document的时候,es需要确定这个document放在该index哪个shard上。这个过程就是数据路由。
路由算法:shard = hash(routing) % number_of_primary_shards
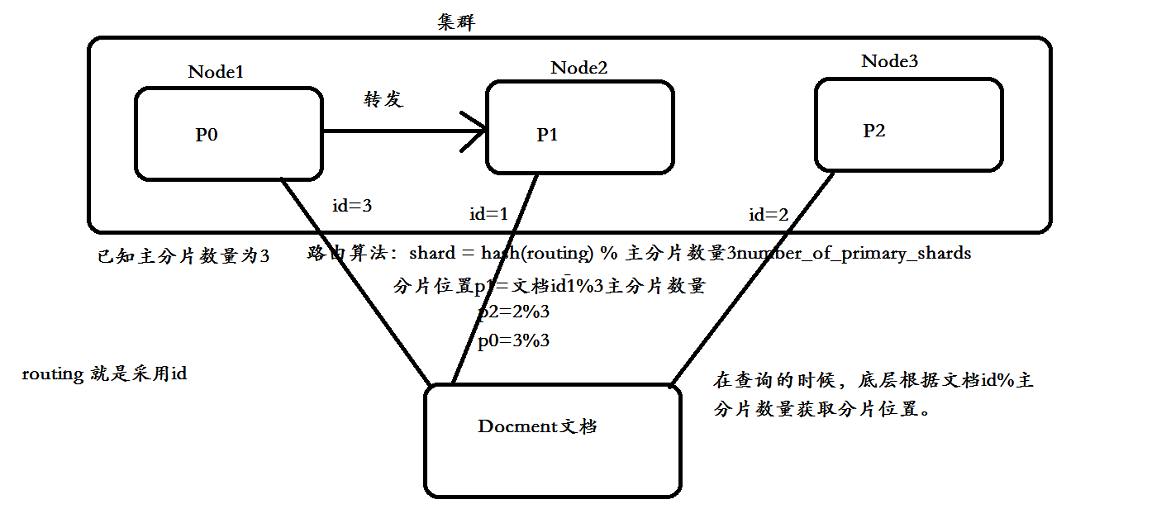
``


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 25岁的心里话
· 按钮权限的设计及实现