request模块
request模块
- urllib模块
- requests模块
requests模块:
python中原生的一款基于网络请求的模块,功能非常强大,简单便捷,效率极高.
作用:
模拟浏览器发请求
如何使用:
- 指定url
- 发起请求
- 获取响应数据
- 持久化存储
第一章: request模块
1. 爬取搜狗指定词条对应的搜索结果页面(简易网页采集器) get请求 text文本
- UA检测
- UA伪装


import requests if __name__ == '__main__': # 1. 指定URL url = 'https://www.sogou.com/web' # UA伪装 headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36' } # 搜索关键字 kw = input('enter a word:') param = { 'query': kw, } # 2. 发起请求 response = requests.get(url=url, params=param, headers=headers) # 3. 获取响应数据 page_text = response.text # 4. 持久化存储 fileName = kw + '.html' with open(fileName, 'w', encoding='utf-8') as fp: fp.write(page_text) print(fileName, '保存成功!')
2. 破解百度翻译 post请求 json()对象数据
- post请求(携带了参数)
- 响应数据是一组json数据
import requests import json if __name__ == '__main__': # 1. 指定url post_url = "https://fanyi.baidu.com/sug" # 2. 进行UA伪装 headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36" } # 3. post请求参数处理(同get请求一致) kw = input('enter a word:') data = { 'kw': kw } # 4. 请求发送 response = requests.post(url=post_url, data=data, headers=headers) # 5. 获取响应数据: json()方法返回的是obj, 如果确认响应数据是json类型的,才可以使用json() dic_obj = response.json() # 6. 持久化存储 fileName = kw + '.json' fp = open(fileName, 'w', encoding='utf-8') json.dump(dic_obj, fp=fp, ensure_ascii=False) # 数据中包含中文,但中文不能用ascii码编码,所以这里增加参数ensure_ascii=False print('over!')
3. 爬取豆瓣电影分类排行榜 get请求 json()对象数据
import requests import json if __name__ == '__main__': url = 'https://movie.douban.com/j/chart/top_list' headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36" } param = { "type": "24", "interval_id": "100:90", "action": "", "start": "0", # 从库中第几部开始取 "limit": "20" # 一次取出的个数 } response = requests.get(url=url, params=param, headers=headers) list_data = response.json() fp = open('./douban.json', 'w', encoding='utf-8') json.dump(list_data, fp=fp, ensure_ascii=False) print('over!!!')
4. 爬取肯德基餐厅信息 post请求 text文本
- post请求url要写完整
import requests if __name__ == '__main__': # 1. url post_url = "http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword" # 2. UA伪装 headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36" } # 3. 携带数据 city = input('enter a city:') data = { "cname": "", "pid": "", "keyword": city, "pageIndex": "1", "pageSize": "10" } # 4. 发起请求 response = requests.post(url=post_url, data=data, headers=headers) # 5. 获取数据 restaurants = response.text # 6. 持久化 print(restaurants) fileName = city + '.html' with open(fileName, 'w', encoding='utf-8') as fp: fp.write(restaurants)
5. 爬取药监总局化妆品登记信息 post请求 json()对象
import requests if __name__ == '__main__': url = 'http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList' headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36" } data = { 'on': 'true', 'page': '1', 'pageSize': '15', 'productName': '', 'conditionType': '1', 'applyname': "", 'applysn': '' } res_json = requests.post(url=url, headers=headers, data=data).json() print(res_json['list']) # [{'ID': 'ed59438f34ae47e794f4c7ee5137c1f7', 'EPS_NAME': '海南京润珍珠生物技术股份有限公司', 'PRODUCT_SN': '琼妆20160001', 'CITY_CODE': '311', 'XK_COMPLETE_DATE': {'date': 25, 'day': 0, 'hours': 0, 'minutes': 0, 'month': 3, 'nanos': 0, 'seconds': 0, 'time': 1619280000000, 'timezoneOffset': -480, 'year': 121}, 'XK_DATE': '2026-04-25', 'QF_MANAGER_NAME': '海南省药品监督管理局', 'BUSINESS_LICENSE_NUMBER': '91460000294121210Y', 'XC_DATE': '2021-04-25', 'NUM_': 1}, {'ID': '9fc761a8ec9c4d98ae1c8fa8889d23a4', 'EPS_NAME': '云南世纪华宝医药产业开发有限公司', 'PRODUCT_SN': '云妆20190003', 'CITY_CODE': '206', 'XK_COMPLETE_DATE': {'date': 21, 'day': 3, 'hours': 0, 'minutes': 0, 'month': 3, 'nanos': 0, 'seconds': 0, 'time': 1618934400000, 'timezoneOffset': -480, 'year': 121}, 'XK_DATE': '2024-09-30', 'QF_MANAGER_NAME': '云南省食品药品监督管理局', 'BUSINESS_LICENSE_NUMBER': '915323000804056728', 'XC_DATE': '2021-04-21', 'NUM_': 2}, {'ID': '5eb10afc74a2462c8e86652ec8d90a48', 'EPS_NAME': '无锡邦士立生物科技有限公司', 'PRODUCT_SN': '苏妆20160013', 'CITY_CODE': '82', 'XK_COMPLETE_DATE': {'date': 20, 'day': 2, 'hours': 0, 'minutes': 0, 'month': 3, 'nanos': 0, 'seconds': 0, 'time': 1618848000000, 'timezoneOffset': -480, 'year': 121}, 'XK_DATE': '2026-04-20', 'QF_MANAGER_NAME': '江苏省药品监督管理局', 'BUSINESS_LICENSE_NUMBER': '91320213355032183D', 'XC_DATE': '2021-04-20', 'NUM_': 3}, {'ID': 'a2cf9eca47f742a6ba59c945a9c1ce50', 'EPS_NAME': '惠州市新俊雅礼品有限公司', 'PRODUCT_SN': '粤妆20210116', 'CITY_CODE': None, 'XK_COMPLETE_DATE': {'date': 19, 'day': 1, 'hours': 0, 'minutes': 0, 'month': 3, 'nanos': 0, 'seconds': 0, 'time': 1618761600000, 'timezoneOffset': -480, 'year': 121}, 'XK_DATE': '2026-04-18', 'QF_MANAGER_NAME': '广东省药品监督管理局', 'BUSINESS_LICENSE_NUMBER': '91441302MA4UKKYU7H', 'XC_DATE': '2021-04-19', 'NUM_': 4}, {'ID': 'bc36d30f81da4130bd2696c691f44893', 'EPS_NAME': '广州启迪生物科技有限公司', 'PRODUCT_SN': '粤妆20210115', 'CITY_CODE': None, 'XK_COMPLETE_DATE': {'date': 19, 'day': 1, 'hours': 0, 'minutes': 0, 'month': 3, 'nanos': 0, 'seconds': 0, 'time': 1618761600000, 'timezoneOffset': -480, 'year': 121}, 'XK_DATE': '2026-04-18', 'QF_MANAGER_NAME': '广东省药品监督管理局', 'BUSINESS_LICENSE_NUMBER': '91440101MA9W1FJQ2Y', 'XC_DATE': '2021-04-19', 'NUM_': 5}, {'ID': '80c32a082b3d400da55afe838ded7e31', 'EPS_NAME': '广东同仁堂科技有限公司', 'PRODUCT_SN': '粤妆20210114', 'CITY_CODE': None, 'XK_COMPLETE_DATE': {'date': 19, 'day': 1, 'hours': 0, 'minutes': 0, 'month': 3, 'nanos': 0, 'seconds': 0, 'time': 1618761600000, 'timezoneOffset': -480, 'year': 121}, 'XK_DATE': '2026-04-18', 'QF_MANAGER_NAME': '广东省药品监督管理局', 'BUSINESS_LICENSE_NUMBER': '91440101MA9UT56R1F', 'XC_DATE': '2021-04-19', 'NUM_': 6}, {'ID': '369682cefc0942e9a820e09ad8223b4c', 'EPS_NAME': '广州常青藤化妆品有限公司', 'PRODUCT_SN': '粤妆20210113', 'CITY_CODE': None, 'XK_COMPLETE_DATE': {'date': 19, 'day': 1, 'hours': 0, 'minutes': 0, 'month': 3, 'nanos': 0, 'seconds': 0, 'time': 1618761600000, 'timezoneOffset': -480, 'year': 121}, 'XK_DATE': '2026-04-18', 'QF_MANAGER_NAME': '广东省药品监督管理局', 'BUSINESS_LICENSE_NUMBER': '9144011179940374XH', 'XC_DATE': '2021-04-19', 'NUM_': 7}, {'ID': '31014906fe134a36b9a34006d816371e', 'EPS_NAME': '汕头市正美日化有限公司', 'PRODUCT_SN': '粤妆20210110', 'CITY_CODE': None, 'XK_COMPLETE_DATE': {'date': 19, 'day': 1, 'hours': 0, 'minutes': 0, 'month': 3, 'nanos': 0, 'seconds': 0, 'time': 1618761600000, 'timezoneOffset': -480, 'year': 121}, 'XK_DATE': '2026-04-18', 'QF_MANAGER_NAME': '广东省药品监督管理局', 'BUSINESS_LICENSE_NUMBER': '91440514MA54Y20M0T', 'XC_DATE': '2021-04-19', 'NUM_': 8}, {'ID': '091cdb11f4734b5fbad59bcabdef8a41', 'EPS_NAME': '广州茗莎生物科技有限公司', 'PRODUCT_SN': '粤妆20210077', 'CITY_CODE': None, 'XK_COMPLETE_DATE': {'date': 19, 'day': 1, 'hours': 0, 'minutes': 0, 'month': 3, 'nanos': 0, 'seconds': 0, 'time': 1618761600000, 'timezoneOffset': -480, 'year': 121}, 'XK_DATE': '2026-03-17', 'QF_MANAGER_NAME': '广东省药品监督管理局', 'BUSINESS_LICENSE_NUMBER': '91440101MA9W1QY64P', 'XC_DATE': '2021-04-19', 'NUM_': 9}, {'ID': '5ed3142f85f945efad6404f236c00ab6', 'EPS_NAME': '广州智创智美生物科技有限公司', 'PRODUCT_SN': '粤妆20200103', 'CITY_CODE': None, 'XK_COMPLETE_DATE': {'date': 19, 'day': 1, 'hours': 0, 'minutes': 0, 'month': 3, 'nanos': 0, 'seconds': 0, 'time': 1618761600000, 'timezoneOffset': -480, 'year': 121}, 'XK_DATE': '2025-07-01', 'QF_MANAGER_NAME': '广东省药品监督管理局', 'BUSINESS_LICENSE_NUMBER': '91440101MA5D4JRC1L', 'XC_DATE': '2021-04-19', 'NUM_': 10}, {'ID': 'b6d6dd68a6964915991994e91dc6a462', 'EPS_NAME': '广州市华业化妆品有限公司', 'PRODUCT_SN': '粤妆20170589', 'CITY_CODE': None, 'XK_COMPLETE_DATE': {'date': 19, 'day': 1, 'hours': 0, 'minutes': 0, 'month': 3, 'nanos': 0, 'seconds': 0, 'time': 1618761600000, 'timezoneOffset': -480, 'year': 121}, 'XK_DATE': '2022-11-16', 'QF_MANAGER_NAME': '广东省药品监督管理局', 'BUSINESS_LICENSE_NUMBER': '91440101MA59QLU8XH', 'XC_DATE': '2021-04-19', 'NUM_': 11}, {'ID': '0cc1168d9951479b989fe2639754fd57', 'EPS_NAME': '广州市御象实业有限公司', 'PRODUCT_SN': '粤妆20170374', 'CITY_CODE': None, 'XK_COMPLETE_DATE': {'date': 19, 'day': 1, 'hours': 0, 'minutes': 0, 'month': 3, 'nanos': 0, 'seconds': 0, 'time': 1618761600000, 'timezoneOffset': -480, 'year': 121}, 'XK_DATE': '2022-04-12', 'QF_MANAGER_NAME': '广东省药品监督管理局', 'BUSINESS_LICENSE_NUMBER': '91440101MA59EB967N', 'XC_DATE': '2021-04-19', 'NUM_': 12}, {'ID': '58bc161b2f5e4bcd9d4722e90b1a61e9', 'EPS_NAME': '广州市媚黛生物科技有限公司', 'PRODUCT_SN': '粤妆20170307', 'CITY_CODE': None, 'XK_COMPLETE_DATE': {'date': 19, 'day': 1, 'hours': 0, 'minutes': 0, 'month': 3, 'nanos': 0, 'seconds': 0, 'time': 1618761600000, 'timezoneOffset': -480, 'year': 121}, 'XK_DATE': '2022-03-02', 'QF_MANAGER_NAME': '广东省药品监督管理局', 'BUSINESS_LICENSE_NUMBER': '91440101MA59GR6E8M', 'XC_DATE': '2021-04-19', 'NUM_': 13}, {'ID': '41f6cde894294002ae587193d69796ae', 'EPS_NAME': '广州柏灡化妆品有限公司', 'PRODUCT_SN': '粤妆20170211', 'CITY_CODE': None, 'XK_COMPLETE_DATE': {'date': 19, 'day': 1, 'hours': 0, 'minutes': 0, 'month': 3, 'nanos': 0, 'seconds': 0, 'time': 1618761600000, 'timezoneOffset': -480, 'year': 121}, 'XK_DATE': '2024-09-02', 'QF_MANAGER_NAME': '广东省药品监督管理局', 'BUSINESS_LICENSE_NUMBER': '91440111675650669X', 'XC_DATE': '2021-04-19', 'NUM_': 14}, {'ID': 'e645b1730d3c4fce946f80c87c77a9ee', 'EPS_NAME': '广州合众无纺化妆品集团有限公司', 'PRODUCT_SN': '粤妆20170086', 'CITY_CODE': None, 'XK_COMPLETE_DATE': {'date': 19, 'day': 1, 'hours': 0, 'minutes': 0, 'month': 3, 'nanos': 0, 'seconds': 0, 'time': 1618761600000, 'timezoneOffset': -480, 'year': 121}, 'XK_DATE': '2022-01-15', 'QF_MANAGER_NAME': '广东省药品监督管理局', 'BUSINESS_LICENSE_NUMBER': '91440101MA59EXE93U', 'XC_DATE': '2021-04-19', 'NUM_': 15}]
第二章:数据解析
- 数据解析原理:
- 1. 标签定位
- 2. 提取标签、标签属性中存储的数据值
1. 爬取单张图片 get请求 content二进制类型数据
import requests if __name__ == '__main__': url = 'https://ss3.bdstatic.com/70cFv8Sh_Q1YnxGkpoWK1HF6hhy/it/u=1106416652,146193367&fm=26&gp=0.jpg' response = requests.get(url=url).content with open('./qiutu.jpg', 'wb') as fp: fp.write(response) print('over!!')
2. 正则解析案例:爬取糗图百科的热图栏目所有分页中的所有图片 get请求 text, content数据
- 使用正则表达式,匹配页面(text文本)中的图片(src属性)地址
import requests import re import os if __name__ == '__main__': # 创建一个文件夹,用于存放所有图片 if not os.path.exists('./qiutu'): os.mkdir('./qiutu') headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36" } # 循环页码,进行多页爬取 for pageNum in range(1, 3): # 这里只演示爬取前两页 if not os.path.exists(f'./qiutu/{pageNum}'): os.mkdir(f'./qiutu/{pageNum}') page_url = f'https://www.qiushibaike.com/imgrank/page/{pageNum}/' print(page_url) # 爬取一页的源代码 page_text = requests.get(url=page_url, headers=headers).text # 提取图片地址的正则表达式,注意()内的就将是提取到的地址 ex = '<div class="thumb">.*?<img src="(.*?)" alt.*?</div>' # re.S表示单行匹配, 在数据解析中都是用单行匹配的。 src_list = re.findall(ex, page_text, re.S) # 提取出页码中所有的图片地址 for src in src_list: img_name = src.split('/')[-1] # 取出图片的文件名称 src = 'https:' + src img_path = f'./qiutu/{pageNum}/{img_name}' img_data = requests.get(url=src, headers=headers).content with open(img_path, 'wb') as fp: fp.write(img_data) print(img_name, '下载成功!') print('over!!')
3. bs4进行数据解析
- bs4数据解析原理: - 1. 实例化一个BeautifulSoup对象,并且将页面源码数据加载到该对象中 - 2. 通过调用BeautifulSoup对象中相关的属性或者方法进行标签定位和数据提取 - 环境安装: - pip install bs4 - pip install lxml 解析器 - 如何实例化BeautifulSoup对象: - from bs4 import BeautifulSoup - 对象的实例化: - 1. 将本地的htl文档中的数据加载到该对象中 fp = open('./test.html', 'r', encoding='utf-8') soup = BeautifulSoup(fp, 'lxml') - 2. 将互联网上获取的页面源码加载到该对象中 page_text = response.text soup = BeautifulSoup(page_text, 'lxml') - 提供的用于数据解析的方法和属性: - soup.tagName(标签名称): 返回的是html中第一次出现的tagName标签 如: print(soup.div) print(soup.a) - soup.find(): - soup.find('tagName'): 等同与soup.tagName 如:soup.find('div') - 属性定位: - soup.find('div', class_='song): 定位到class属性是song的div标签(class属性需要加下划线,其他属性不需要id/attr) - soup.find_all('tagName'): 返回符合要求的所有标签(返回值为列表), 和soup.find()一样也可以使用属性进行筛选(定位) - soup.select: - soup.select('某种选择器(id, class, 标签...选择器)')返回值是列表 如:soup.select('.tang')定位到类属性为class='tang'的所有标签 - 层级选择器的使用: - soup.select('.tang > ul > li > a')[0] : >表示的是一个层级 - soup.select('.tang > ul a')[0] : 空格表示的是夸多个层级 - 获取标签之间的文本数据: - soup.a.text soup.a.string soup.a.get_text() soup.a.text/string/get_text() - text/get_text(): 可以获取标签中的所有文本内容(包含该标签的所有下级标签中的文本) - string: 只可以获取该标签下面直系的文本内容(无法获取该标签的子(孙)标签中的文本) - 获取标签中属性值: - soup.a['href'] 如:获取a标签的href值,soup.select('.tang > ul a')[0]['href']
- bs4实例:爬取三国演义全部内容
import requests from bs4 import BeautifulSoup import time if __name__ == '__main__': headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36", } # 三国演义目录页面url title_url = 'https://www.shicimingju.com/book/sanguoyanyi.html' title_page_text = requests.get(url=title_url, headers=headers).content # 这里使用.content而不是用.text,可以防止中文乱码 soup = BeautifulSoup(title_page_text, 'lxml') li_list = soup.select('.book-mulu > ul > li') # 每一章标题的li标签 fp = open('./sanguo.txt', 'w', encoding='utf-8') for li in li_list: time.sleep(2) title = li.a.string # 三国演义每一个章节详细内容页面url detail_url = 'https://www.shicimingju.com' + li.a['href'] detail_text = requests.get(url=detail_url, headers=headers).content detail_soup = BeautifulSoup(detail_text, 'lxml') detail_text = detail_soup.find('div', class_='chapter_content').text fp.write(title + ':' + detail_text + '\n') print(title, '爬取成功!')
4. xpath解析: 最常用且最便捷高效的一种解析方式。通用性。
- xpath解析原理:
- 1. 实例化一个etree的对象,且需要将被解析的页面源码数据加载到该对象中.
- 2. 调用etree对象中的xpath方法结合着xpath表达式实现标签的定位和内容的捕获.
- 环境安装:
- pip install lxml
- 如何实例化一个etree对象: from lxml iport etree
- 1. 将本地的html文档中的源码数据加载到etree对象中:
etree.parse(filePath)
- 2. 可以将从互联网上获取的源码数据加载到该对象中
etree.HTML('page_text')
- xpath('xpath表达式') 学习重点
- xpath表达式:
- /:表示的是从根节点开始定位.表示的是一个层级.
- tree = etree.parse('test.thml') r = tree.xpath('/html/body/div') 返回值是列表,元素时element对象(标签对象)
- //:表示的是多个层级.可以表示从任意位置开始定位.
- r = tree.xpath('/thml//div')
- r = tree.xpath('//div')
- ./:表示从当前定位到的标签开始
- r = li.xpath('./div[2]/h2/a') 表示从当前的li标签开始,向其内部层级深入
- |: 连接xpath内的两个表达式,表示或者关系
- r = tree.xpath('//div/ul/li | //div/div/p')
- 属性定位: tagName[@attrName='attrValue']
- r = tree.xpath('//div[@class="song"]')
- 索引定位:
- r = tree.xpath('//div[@class="song"]/p[3]') 索引是从1开始的,定位到第3个p标签
- 取文本
- /text() 只能获取直系的文本(无法获取其子孙标签中的文本), 返回值是列表
- r = tree.xpath('//div[@class="tang"]//li[5]/a/text()')[0] 获取第5个li标签下的a标签中的文本
- //text() 获取标签中全部文本内容(包含子孙标签中的文本)
- r = tree.xpath('//li[7]//text()') 获取第7个li标签下的全部文本
- 取属性值
- /@attrName ===>img/@src
- r = tree.xpath('//div[@class="song"]/img/@src') 获取src的值, 返回值是列表
- xpath实例,爬取58同城二手房信息
import requests from lxml import etree if __name__ == '__main__': headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36", } # 爬取到页面源码数据 url = 'https://siyang.58.com/ershoufang/' page_text = requests.get(url=url, headers=headers).text # 数据解析 tree = etree.HTML(page_text) # 使用xpath定位出房源标题文本的位置标签 div_list = tree.xpath('//section[@class="list"]/div[@class="property"]') fp = open('58.txt', 'w', encoding='utf-8') # 数据持久化 for div in div_list: # 提取出标题文本 title = div.xpath('./a//h3[@class="property-content-title-name"]/text()')[0] print(title) fp.write(title + '\n')
- xpath实例,爬取4K图片
import requests import os from lxml import etree if __name__ == '__main__': if not os.path.exists('./美女图片'): os.mkdir('./美女图片') headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36", } url = 'https://pic.netbian.com/4kmeinv/' response = requests.get(url=url, headers=headers) # 第一种解中文乱码的方法, 如果不行使用第二种 # response.encoding = 'utf-8' page_text = response.text # print(page_text) tree = etree.HTML(page_text) # 解析定位出图片的位置,在li标签中 li_list = tree.xpath('//div[@class="slist"]/ul/li') for li in li_list: # 获取图片的真实地址,获取src属性的值 img_src = 'https://pic.netbian.com' + li.xpath('./a/img/@src')[0] # 获取图片的alt属性值,作为图片的名称 img_name = li.xpath('./a/img/@alt')[0] + '.jpg' # 第二种解中文乱码的方法 img_name = img_name.encode('iso-8859-1').decode('gbk') # 数据持久化 img_path = '美女图片/' + img_name img_data = requests.get(url=img_src, headers=headers).content with open(img_path, 'wb') as fp: fp.write(img_data) print(img_name, '下载成功!')
- xpath实例,爬取全国城市名称
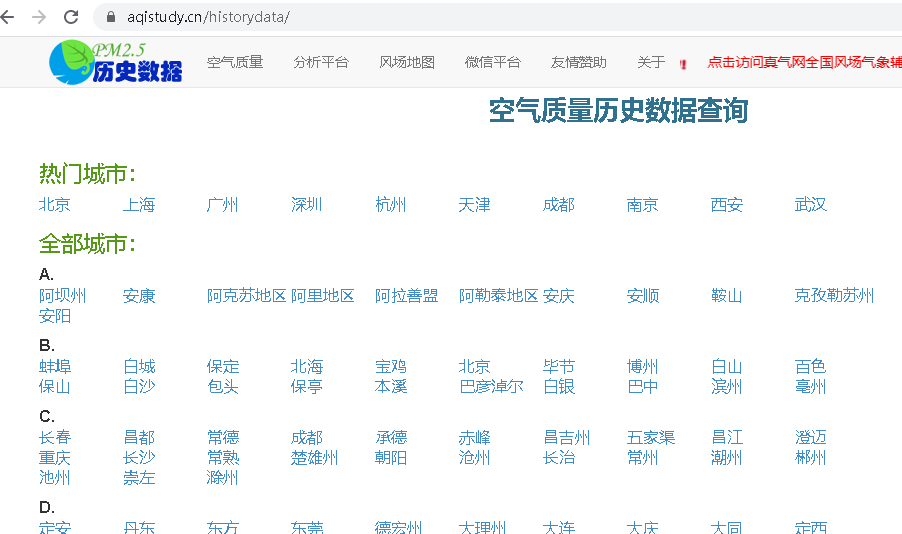
- 第一处li标签中有热门城市名称

- 第二处li标签中有其他所有城市的名称
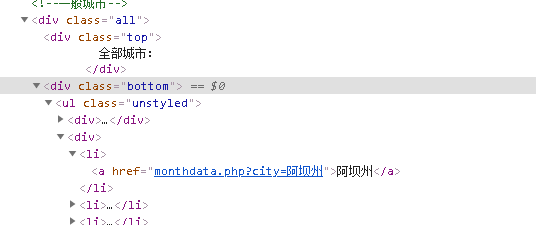
import requests from lxml import etree if __name__ == '__main__': url = 'https://www.aqistudy.cn/historydata/' headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36" } page_text = requests.get(url=url, headers=headers).text tree = etree.HTML(page_text) city_name_list = [] # 获取热点城市的城市名称 hot_li_list = tree.xpath('//div[@class="bottom"]/ul/li') for hot in hot_li_list: hot_city_name = hot.xpath('./a/text()')[0] city_name_list.append(hot_city_name) # 获取其它全部城市名称 other_li_list = tree.xpath('//div[@class="bottom"]/ul/div[2]/li') for other in other_li_list: other_city_name = other.xpath('./a/text()')[0] city_name_list.append(other_city_name) print(city_name_list, len(city_name_list))
import requests from lxml import etree if __name__ == '__main__': url = 'https://www.aqistudy.cn/historydata/' headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36" } page_text = requests.get(url=url, headers=headers).text tree = etree.HTML(page_text) city_name_list = [] # xpath表达式中采用|或者关系符号连接两个标签定位式子 li_list = tree.xpath('//div[@class="bottom"]/ul/li | //div[@class="bottom"]/ul/div[2]/li') for li in li_list: city_name = li.xpath('./a/text()')[0] city_name_list.append(city_name) print(city_name_list, len(city_name_list))
-xpath爬取实例: 爬取站长素材中的免费简历模板
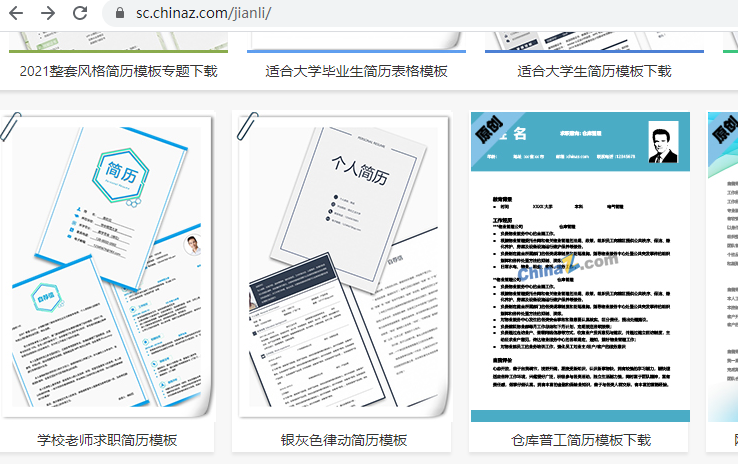
- 简历列表Div标签位置(简历详情页面的URL)
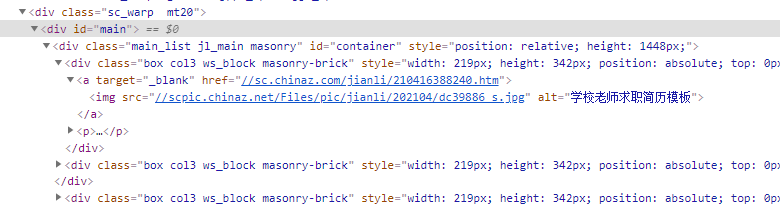
- 简历rar下载地址
import requests import os from lxml import etree import time import re if __name__ == '__main__': if not os.path.exists('./简历模板'): os.mkdir('./简历模板') headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36", } list_url = 'https://sc.chinaz.com/jianli/index.html' page_list_text = requests.get(url=list_url, headers=headers).text tree = etree.HTML(page_list_text) # 模板详情页面的div标签列表 div_list = tree.xpath('//div[@id="main"]/div/div') for div in div_list: time.sleep(2) # 获取模板详情页面url download_page_url = 'https:' + div.xpath('./a/@href')[0] response = requests.get(url=download_page_url, headers=headers) response.encoding = 'utf-8' # 解决乱码问题 download_page_text = response.text # print(download_page_text) ex = '模板原价' is_in = re.findall(ex, download_page_text, re.S) # print(is_in) if is_in: print('付费模块,不爬取!') continue download_tree = etree.HTML(download_page_text) # 模板文件下载地址 download_file_url = download_tree.xpath('//div[@id="down"]/div[2]/ul/li[4]/a/@href')[0] file_name = download_file_url.split('/')[-1] # 获取模板文件二进制数据 file_data = requests.get(url=download_file_url, headers=headers).content # 数据持久化 file_path = '简历模板/' + file_name with open(file_path, 'wb') as fp: fp.write(file_data) print(file_name, '下载完毕!')
第三章:验证码识别
1.打码网站:验证码识别网站http://www.chaojiying.com/price.html
超级鹰验证码识别功能的类源代码:
# chaojiying.py #!/usr/bin/env python # coding:utf-8 import requests from hashlib import md5 class Chaojiying_Client(object): def __init__(self, username, password, soft_id): self.username = username password = password.encode('utf8') self.password = md5(password).hexdigest() self.soft_id = soft_id self.base_params = { 'user': self.username, 'pass2': self.password, 'softid': self.soft_id, } self.headers = { 'Connection': 'Keep-Alive', 'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)', } def PostPic(self, im, codetype): """ im: 图片字节 codetype: 题目类型 参考 http://www.chaojiying.com/price.html """ params = { 'codetype': codetype, } params.update(self.base_params) files = {'userfile': ('ccc.jpg', im)} r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers) return r.json() def ReportError(self, im_id): """ im_id:报错题目的图片ID """ params = { 'id': im_id, } params.update(self.base_params) r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers) return r.json() if __name__ == '__main__': chaojiying = Chaojiying_Client('lldbty', 's666888999', '915545') # 用户中心>>软件ID 生成一个替换 96001 im = open('a.jpg', 'rb').read() # 本地图片文件路径 来替换 a.jpg 有时WIN系统须要// print(chaojiying.PostPic(im, 1902)) # 1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加()
2. 古诗文网站登录的验证码识别代码
import requests from lxml import etree from Chaojiying_Python.chaojiying import Chaojiying_Client # 调用验证码识别模块 超级鹰 if __name__ == '__main__': headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36", } login_page_url = 'https://so.gushiwen.org/user/login.aspx?from=http://so.gushiwen.org/user/collect.aspx' # 获取登录页面中的验证码图片,下载到本地 login_page_text = requests.get(url=login_page_url, headers=headers).text tree = etree.HTML(login_page_text) code_img_url = 'https://so.gushiwen.org/' + tree.xpath('//*[@id="imgCode"]/@src')[0] code_img_data = requests.get(url=code_img_url, headers=headers).content with open('code.jpg', 'wb') as fp: fp.write(code_img_data) # 使用超级鹰验证码识别模块识别验证码 chaojiying = Chaojiying_Client('lldbty', 's666888999', '915545') # 用户中心>>软件ID 生成一个替换 96001 im = open('code.jpg', 'rb').read() # 本地图片文件路径 来替换 a.jpg 有时WIN系统须要// print(chaojiying.PostPic(im, 1902)) # 1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加() # return {'err_no': 0, 'err_str': 'OK', 'pic_id': '1138514226096700002', 'pic_str': 'aes4', 'md5': '80ba2eaeffb49252bcfa29e813e88af6'}
第四章:requests模块高级操作 模拟登录 cookie session
模拟登录:
- 爬取基于某些用户的用户信息
需求: 对人人网进行模拟登录
- 点击登录按钮之后会发起一个post请求
- post请求中会携带登录之前录入的相关的登录信息(用户名,密码, 验证码......)
- 验证码:每次请求都会变化
需求:爬取当前用户的相关的用户信息(个人主页中显示的用户信息)
http/https协议特性:无状态
没有请求到对应页面数据的原因:
发起的第二次基于个人主页页面请求的时候,服务器端并不制定该请求是基于登录状态下的请求。
cookie:用来让服务器端记录客户端的相关状态。
- 手动处理:通过抓包工具获取cookie值,将该值封装到hearders中。(不建议)
- 自动处理:
- cookie值的来源是哪里?
- 模拟登录post请求后,由服务器端创建。
session回话对象:
- 作用:
1. 可以进行请求的发送
2. 如果请求过程中产生了cookie,则该cookie会被自动存储/携带在该session对像中。
- 创建一个session对象: session = requests.Session()
- 使用session对象进行模拟登录post请求的发送(cookie就会被存储在session中)
- session对象对个人主页对应的get请求进行发送(携带了cookie)
需求:request模拟登录某管理系统,并执行查询操作。
import requests from lxml import etree from chaojiying import Chaojiying_Client if __name__ == '__main__': headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36", } # 获取验证码字符串 login_page_url = 'https://xjgl.jse.edu.cn/uids/index.jsp' login_page_text = requests.get(url=login_page_url, headers=headers).text tree = etree.HTML(login_page_text) code_src = 'https://xjgl.jse.edu.cn/uids/' + tree.xpath('//*[@id="imgCode"]/@src')[0] code_data = requests.get(url=code_src, headers=headers).content with open('./xjcode.jpg', 'wb') as fp: fp.write(code_data) chaojiying = Chaojiying_Client('lldbty', 's666888999', '915545') # 用户中心>>软件ID 生成一个替换 96001 im = open('./xjcode.jpg', 'rb').read() # 本地图片文件路径 来替换 a.jpg 有时WIN系统须要// # print(chaojiying.PostPic(im, 1902)) # 1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加() code_str = chaojiying.PostPic(im, 1902)['pic_str'] print(code_str) # 携带验证码数据进行第一次模拟登录(302重定向) session = requests.Session() login_post_url = 'https://xjgl.jse.edu.cn/uids/login.jsp' data = { "randomCode": code_str, "returnURL": "", "appId": "uids", "encrypt": "1", "reqId": "1618915650544", "req": "932AAC3E2807596F23E3DA6CC63FDFF649C5F34433A4153F0B4E3FEE71072865CD2D22E33035370D505F516906C0B20024E68C51013390C22424F7DB26B1EC2F", } response = session.post(url=login_post_url, headers=headers, data=data) print('login第一次', response.status_code) # 获取状态码302 # 携带用户名密码第二次登录 index_page_url = 'https://xjgl.jse.edu.cn/studman3/index.jsp' data = { 'ssoLoginName': 'x32132221015', 'timeStamp': '1618915653187', 'requestToken': 'baf4a7492956a6aa7ff12c560cf3f625', 'requestToken2': 'c1e916121580a6dd3cb0bad8dd9b073c' } response2 = session.post(url=index_page_url, headers=headers, data=data) print('login第二次', response2.status_code) # 获取学生列表数据 stu_page_url = 'https://xjgl.jse.edu.cn/studman3/studman/student/studentBrowseAct!list.action?statusCheckBox=0&statusCheckBox=-2&statusCheckBox=1&statusCheckBox=2&statusCheckBox=4&statusCheckBox=5&statusCheckBox=7&statusCheckBox=9&statusCheckBox=10' # stu_page_response = session.get(url=stu_page_url, headers=headers) # stu_page_response.encoding = 'GBK' # stu_page_text = stu_page_response.text # # with open('./stu_list.html', 'w', encoding='GBK') as fp: # fp.write(stu_page_text) # 用姓名检索制定的学生s stu_name = input('请输入需要检索的学生姓名:').encode('GBK') param = { "studentForm.name": stu_name, # 'statusCheckBox': '0', # 'statusCheckBox': '-2', # 'statusCheckBox': '1', # 'statusCheckBox': '2', # 'statusCheckBox': '4', # 'statusCheckBox': '5', # 'statusCheckBox': '7', # 'statusCheckBox': '9', # 'statusCheckBox': '10' } stu_page_response = session.get(url=stu_page_url, headers=headers, params=param) stu_page_response.encoding = 'GBK' stu_page_text = stu_page_response.text with open('./stu_list.html', 'w', encoding='GBK') as fp: fp.write(stu_page_text)
代理: 破解封IP这种反扒机制
什么是代理:
- 代理服务器
代理的作用:
- 突破自身IP访问的限制
- 隐藏自身真实IP
代理相关的网站:
- 快代理
- 西祠代理
- www.goubanjia.com
代理IP的匿名度:
- 透明: 服务器知道该次请求使用了代理,也知道请求对应的真实ip
- 匿名: 知道使用了代理,不知道真实ip
- 高匿: 不知道使用了代理,更不知道真实的ip
代理ip使用范例:
import requests from lxml import etree if __name__ == '__main__': url = 'https://www.baidu.com/s?ie=UTF-8&wd=ip' headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36" } proxies = { "https": "171.35.167.75:9999" } page_text = requests.get(url=url, headers=headers, proxies=proxies).text with open('./ip.html', 'w', encoding='utf-8') as fp: fp.write(page_text)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号