
集合框架
集合的概念
什么是集合
- 概念:对象的容器,实现了对对象常用的操作,类似数组功能。
- 和数组的区别:
* 1.数组长度固定,集合长度不固定。
* 数组可以存储基本类型和引用类型,集合只能存储引用类型 - 位置:java.util.*
一、Collection接口
体系集合:
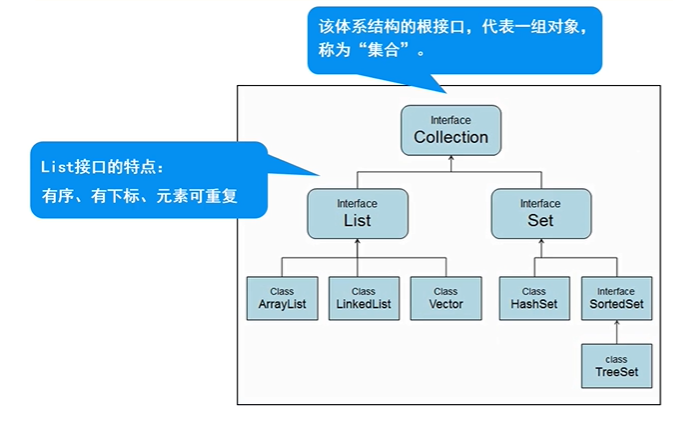
- 特点:代表一组任意类型的对象,无序、无下标、不能重复。
- 方法:
* boolean add(Object obj) //添加一个对象
* boolean addAll(Collection c) //将一个集合中的所有对象添加到此集合中
* void clear() //清空此集合中的所有对象
* boolean contains(Object o) //检查此集合中是否包含o对象
* boolean equals(Object o) //比较此集合是否与指定对象相等
* boolean isEmpty() //判断此集合是否为空
* boolean remove(Object o) //在此集合中移除o对象
* int size() //返回此集合中的元素个数
* Object[] toArray() //将此集合转换成数组 - 使用:


二、List接口与实现类
1-1 List接口
* 特点:有序、有下标、元素可以重复。 * 方法: * void add (int index,Object o) //在index位置插入对象 * boolean add(int index,Collection c) //将一个集合中的元素添加到此集合中的index位置 * Object get(int index) //返回集合中指定位置元素 * List subList(int fromIndex,int toIndex) //返回fromIndex和toIndex之间的集合元素- 使用 :
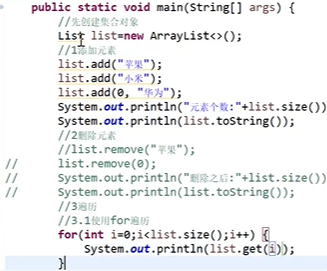

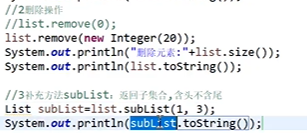
1-2 List实现类:
-
ArrayList
* 数组结构实现 、查询快,增删慢
* 运行效率快,线程不安全 -
Vector
* 数组结构实现,线程安全 -
LinkedList
* 链表结构实现,增删快,查询慢 -
ArrayList源码分析:



-
Vector中的方法:
-
使用:

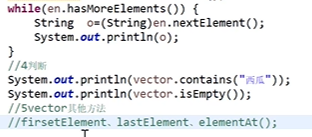
-
LinkedList的使用:
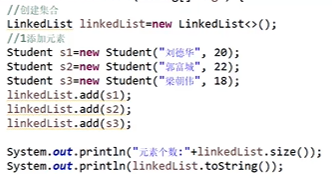
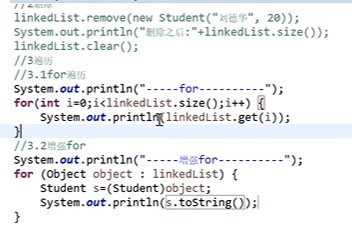

三、泛型和工具类
泛型:
-
Java泛型的本质是参数化类型,把类型作为参数传递。
-
常见形式有:泛型类、泛型接口、泛型方法
-
语法:
* <T....>T被称为类型占位符,表示一种引用类型 -
好处:
* 提高代码重用性
* 防止类型转换异常,提高代码安全性。 -
泛型类的创建与使用
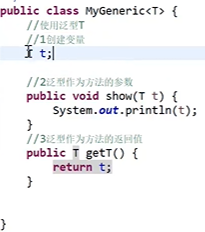
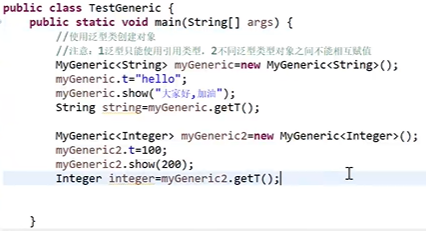
-
泛型接口的创建与使用
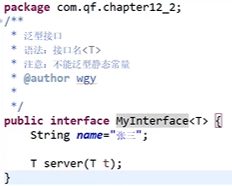
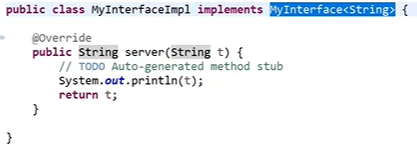

-
泛型方法:


-
泛型集合:

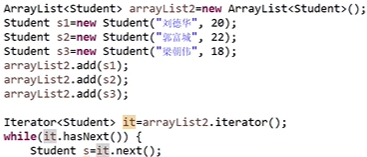
四、Set接口与实现类
-
Set接口的使用
-
实现类

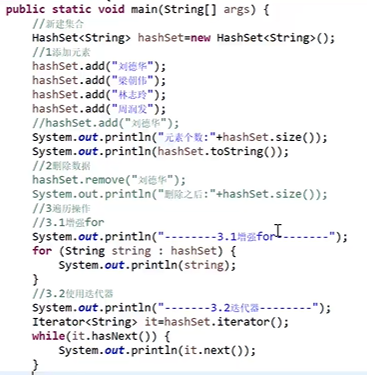
* HashSet集合的使用:
* 存储结构:哈希表【数组+链表+红黑树】;
* 存储过程:
1. 根据hashcode计算保存的位置,若位置为空,则直接保存;若不为空,进行第二步;
2. 再执行equals方法,若equals方法为true,则认为是重复;否则生成链表;
* 改进:
1. 重写hashcode和equals方法改进写入、删除;
2. 快速重写hashcode和equals方法:在开发工具中提供的<Generate hashCode() and equals()...>
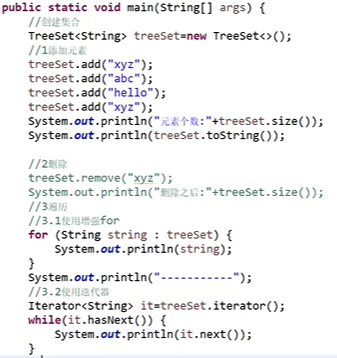
* TreeSet集合的使用
* 存储结构:红黑树;
* 要求:元素必须要实现Comparable接口,compareTo方法返回值为0,认为是重复元素;
由于红黑树的比较特性,需进行如下代码:
public int compareTo(Person o){ //先比较姓名再比较年龄
int n1 = this.getName().compareTo(o.getName());
int n2 = this.age.o.getAge();
return n1 == 0?n2:n1;
}
* Comparable接口:实现定制比较
//创建集合,并制定比较规则
TreeSet<Person> person = new TreeSet<>(
new Comparator<person>(){
public int compareTo(Person o1,Person o2){ //先比较年龄再比较姓名
int n1 = o1.getAge()-o2.getAge();
int n2 = o1.getName().compareTo(o2.getName());
return n1 == 0?n2:n1;
}
* 使用TreeSet集合实现字符串按照长度进行排序
//创建集合,并制定比较规则
TreeSet<String> treeSet = new TreeSet<>(
new Comparator<String>(){
public int compareTo(String o1,String o2){ //先比较年龄再比较姓名
int n1 = o1.length()-o2.length();
int n2 = o1.compareTo(o2);
return n1 == 0?n2:n1;
}
});
//添加数据
TreeSet.add("hello");
TreeSet.add("bello");
TreeSet.add("zello");``
TreeSet.add("lello");
TreeSet.add("aello");
TreeSet.add("xello");
System.out.println(treeSet.toString());
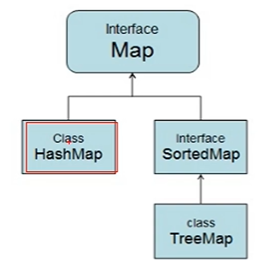
五、Map接口与实现类
1-1 Map接口的特点:
1. 用于存储任意键值对;
2. 键:无序、无下标、不允许重复;
3. 值:无序、无下标、允许重复;
1-2 Map接口的方法:
* V put(K key,V value) //将对象存入到集合中,关联键值。key重复则覆盖原值。
* Object get(Object key) //根据键获取对应的值
* Set<K> //返回所有key
* Collection<V> values() //返回包含所有值的Collection集合
* Set<Map,Entry<K,V>> //键值匹配的Set集合
1-3 Map接口的使用:
public static void main(String[] args){
//创建Map集合
Map<String,String> map = new HashMap<>();
//1.添加元素
map.put("cn","中国");
map.put("uk","英国");
map.out("usa","美国");
//2.显示
System.out.println("元素个数:"+map.size());
System.out.println(map.toString());
//3.遍历:
//3.1 利用keySet()
System.out.println("---------keySet()------------");
for(String key : map.keySet()){
System.out.println(key.toString()+"----"+map.get(key));
}
//3.2 使用entrySet()
System.out.println("---------entrySet()------------");
for(Map.Entry<String,String> entry : map.entrySet()){
System.out.println(entry.getKey()+"----"+entry.getValue());
}
}
2 Map接口的实现类
2-1 HashMap集合
存储结构:哈希表【链表+红黑树+栈】
//添加学生类
public class Student{
private String name;
private int stuNo;
public Student(){
}
public Student(String name,int stuNo){
super();
this.name = name;
this.stuNo = stuNo;
}
public String getName(){
return name;
}
public void setName(String name){
this.name = name;
}
public String getStuNo(){
return StuNo;
}
public void setStuNo(String stuNo){
this.stuNo = stuNo;
}
public String toString(){
return "Student [name="+name+",stuNo="+stuNo+"]";
}
}
//结合Student类使用HashMap集合
public static void main(String[] args){
//创建集合
HashMap<Student,String> students = new HashMap<Student,String>();
//1.添加元素
Student s1 = new Student("悟空",100);
Student s2 = new Student("悟能",101);
Student s3 = new Student("悟净",102);
students.put(s1,"北京");
students.put(s2,"南京");
students.put(s3,"上海");
//2.显示
System.out.println("元素个数:"+students.size());
System.out.println(students.toString());
//3.遍历
//3.1 利用keySet()
System.out.println("---------keySet()------------");
for(Student key : students.keySet()){
System.out.println(key.toString()+"----"+students.get(key));
}
//3.2 使用entrySet()
System.out.println("---------entrySet()------------");
for(Map.Entry<Student,String> entry : students.entrySet()){
System.out.println(entry.getKey()+"----"+entry.getValue());
}
//4.判断
System.out.println(students.containsKey(s1));
System.out.println(students.containsValue("上海"));
}
HashMap源码分析总结:
* HashMap刚创建时,table【初始创建的数组】是null,为了节省空间,当添加第一个元素时,table容量调整为16。
* 当元素个数大于阈值【16*0.75=12】时,会进行扩容,每次扩展后为原来大小的2倍,目的是减少调整元素的个数。
* jdk1.8中当每个链表长度大于8并且数组元素个数大于等于64时,会调整红黑树,目的是提高执行效率。
* jdk1.8中当链表长度小于6时调整成链表。
* jdk1.8以前,链表采用头插法,之后使用尾插法。

