理解CAP理论
1. 理论什么是CAP?
cap定理,它的提出是对于一个分布式系统得出的一个观点,是不能同时满足下面三点
- 一致性
- 可用性
- 分区容忍性
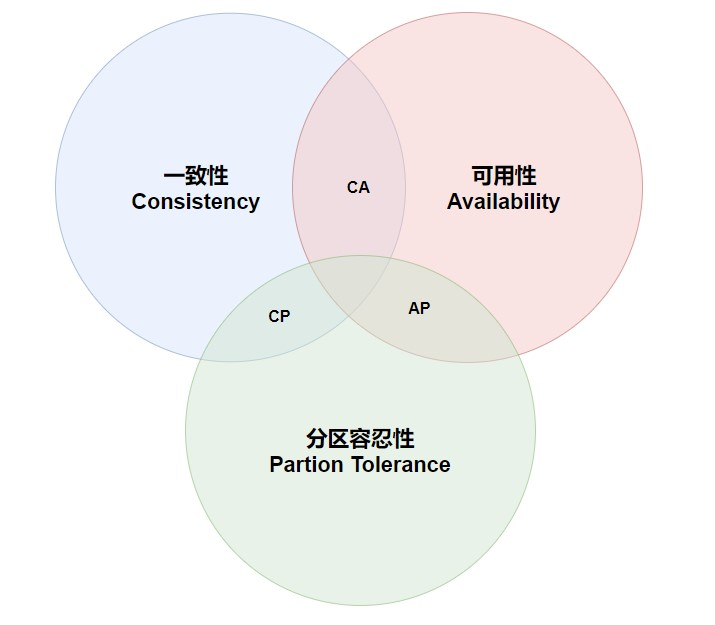
CAP理论认为,分布式系统最多只能同时满足其中的两个特性,而无法同时满足全部三个特性。这是因为在分布式系统中,网络分区和节点故障是不可避免的,而保证一致性和可用性需要跨节点协调,这会增加网络延迟和系统复杂度。
2. 怎么会不可兼得?
一致性(Consistency):在分布式系统中,所有节点看到的数据都是相同的,即系统的数据在任何时刻都是一致的(就是所有的节点访问同样的数据)。
可用性(Availability):在集群中一部分节点故障后,仍然保持集群整体对客户端的响应(对数据更新具备高可用)。
分区容错性(Partition tolerance):大部分的分布式系统都分布在多个子网络里,每个子网络都分为一个区。而分区容错的意思是,每个分区的之间的通信可能会失败。
一个分布式系统里面,节点组成的网络本来应该是连通的。然而可能因为一些故障,使得有些节点之间不连通了,整个网络就分成了几块区域。数据就散布在了这些不连通的区域中。这就叫分区。
当你一个数据项只在一个节点中保存,那么分区出现后,和这个节点不连通的部分就访问不到这个数据了。这时分区就是无法容忍的。
提高分区容忍性的办法就是一个数据项复制到多个节点上,那么出现分区之后,这一数据项就可能分布到各个区里。容忍性就提高了。
然而,要把数据复制到多个节点,就会带来一致性的问题,就是多个节点上面的数据可能是不一致的。要保证一致,每次写操作就都要等待全部节点写成功,而这等待又会带来可用性的问题。
总的来说就是,数据存在的节点越多,分区容忍性越高,但要复制更新的数据就越多,一致性就越难保证。为了保证一致性,更新所有节点数据所需要的时间就越长,可用性就会降低。
3. 那我们怎么选
上述,既然三者不可兼得,那我们在设计分布式系统时要根据实际情况进行权衡和取舍,并在一致性、可用性和分区容错性之间做出适当的平衡。
- 选择CA:放弃分区容错性,保证一致性和可用性。这种策略适用于小规模的集中式系统,如传统的关系型数据库系统。假设不考虑分区(P)的情况下,只有一个分区(副本),副本的一致性自不必说,自然是一致的;可用性方面,一个节点的写入不需要同步到其他节点,可以高效完成。如果增加多个分区(提高分区容错性),数据的写入需要同步到多个节点(强一致性,所有节点同步成功后再返回用户),增加了同步时间和同步失败的可能性,降低了可用性;如果采用弱一致性,即写入操作在主节点成功后即返回用户结果,再通过异步方式同步到多个分区,那么会增加同步失败和数据丢失的几率,降低了一致性。
- 选择CP:放弃可用性,保证一致性和分区容错性。这种策略适用于对数据一致性要求比较高的系统,如金融交易系统。假设不考虑可用性(A)的情况下,多个分区之间可以采用强一致性的机制,保证数据的高度一致性(要么都成功要么都失败)。比如某个分区出现了故障或者分隔,分区没有了响应,由于放弃了可用性,所以可以无限等待并不断重试直到网络恢复,分区可用后将副本数据同步到所有节点。
- 选择AP:放弃一致性,保证可用性和分区容错性。这种策略适用于对数据实时性要求比较高的系统,如社交网络等。假设不考虑一致性(C)的情况下,多个分区和副本可以提供高可用性。分区越多,用户越能就近访问,提供响应速度;放弃了一致性后,副本的写入操作可以写入主节点成功后即可返回成功,获得搞可用性,然后通过异步的方式将副本同步到多个分区节点上。
4. 补充
CAP理论提出就是针对分布式数据库环境的,所以,P这个属性是必须具备的。(即CAP实际上只有AP和CP两种选项)
在分布式环境下,为了保证系统可用性,通常都采取了复制的方式,避免一个节点损坏,导致系统不可用。那么就出现了每个节点上的数据出现了很多个副本的情况,而数据从一个节点复制到另外的节点时需要时间和要求网络畅通的,所以,当P发生时,也就是无法向某个节点复制数据时,这时候你有两个选择:
- 选择可用性 A(Availability),此时,那个失去联系的节点依然可以向系统提供服务,不过它的数据就不能保证是同步的了(失去了C属性)。
- 选择一致性C(Consistency),为了保证数据库的一致性,我们必须等待失去联系的节点恢复过来,在这个过程中,那个节点是不允许对外提供服务的,这时候系统处于不可用状态(失去了A属性)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号