

1 与Github链接与作业摘要
Github网址: Github链接
| 这个作业属于哪个课程 | 所属课程链接 |
|---|---|
| 这个作业要求在哪里 | 作业要求链接 |
| 这个作业的目标 | <熟悉软件工程流程,把握PSP流程框架,精进测试代码和性能改进的能力> |
2 PSP表格时间估计
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 25 | |
| Estimate | 估计这个任务需要多少时间 | 15 | |
| Development | 开发 | 25 | |
| Analysis | 需求分析 (包括学习新技术) | 45 | |
| Design Spec | 生成设计文档 | 30 | |
| Design Review | 设计复审 | 20 | |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | |
| Design | 具体设计 | 25 | |
| Coding | 具体编码 | 30 | |
| Code Review | 代码复审 | 15 | |
| Test | 测试(自我测试,修改代码,提交修改) | 25 | |
| Reporting | 报告 | 45 | |
| Test Report | 测试报告 | 30 | |
| Size Measurement | 计算工作量 | 25 | |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 20 | |
| 合计 | 405 |
3 计算模块接口的设计与实现过程
3.1 函数类型
本次作业采用了三个函数,一个是read_file的读文件函数,一个是calculate_similarity的文本相似性检验函数,最好一个是main函数调用前两个来实现论文查重。因此,read_file和calculate_similarity是两个相互独立的函数,而main函数调用了read_file和calculate_similarity函数。
calculate_similarity的文本相似性检验函数
设计思路:该函数的设计思路是使用difflib模块来比较两个文本之间的差异,通过计算差异字符数和原文字符数的比例来确定相似度。这个相似度值表示抄袭版文本与原文的相似度,可以用于检测文本的重复率。
函数流程图:
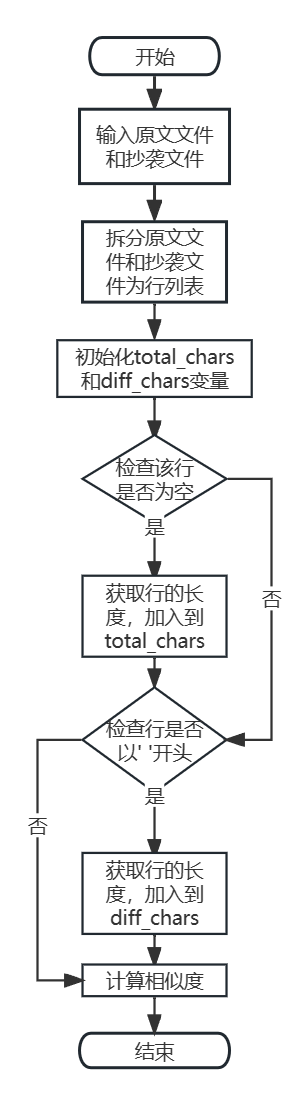
3.2 算法关键
该函数的设计思路是使用difflib模块来比较两个文本之间的差异,通过计算差异字符数和原文字符数的比例来确定相似度。这个相似度值表示抄袭版文本与原文的相似度,可以用于检测文本的重复率。
4 计算模块接口部分的性能改进
4.1 经过Code Quality Analysis并消除警告

其中存在一个因为PE8 编码样式违规造成的弱警告,对代码运行无影响,忽略不计。
4.2 使用pycharm的cProfile来分析代码性能,分析结果如下图所示:
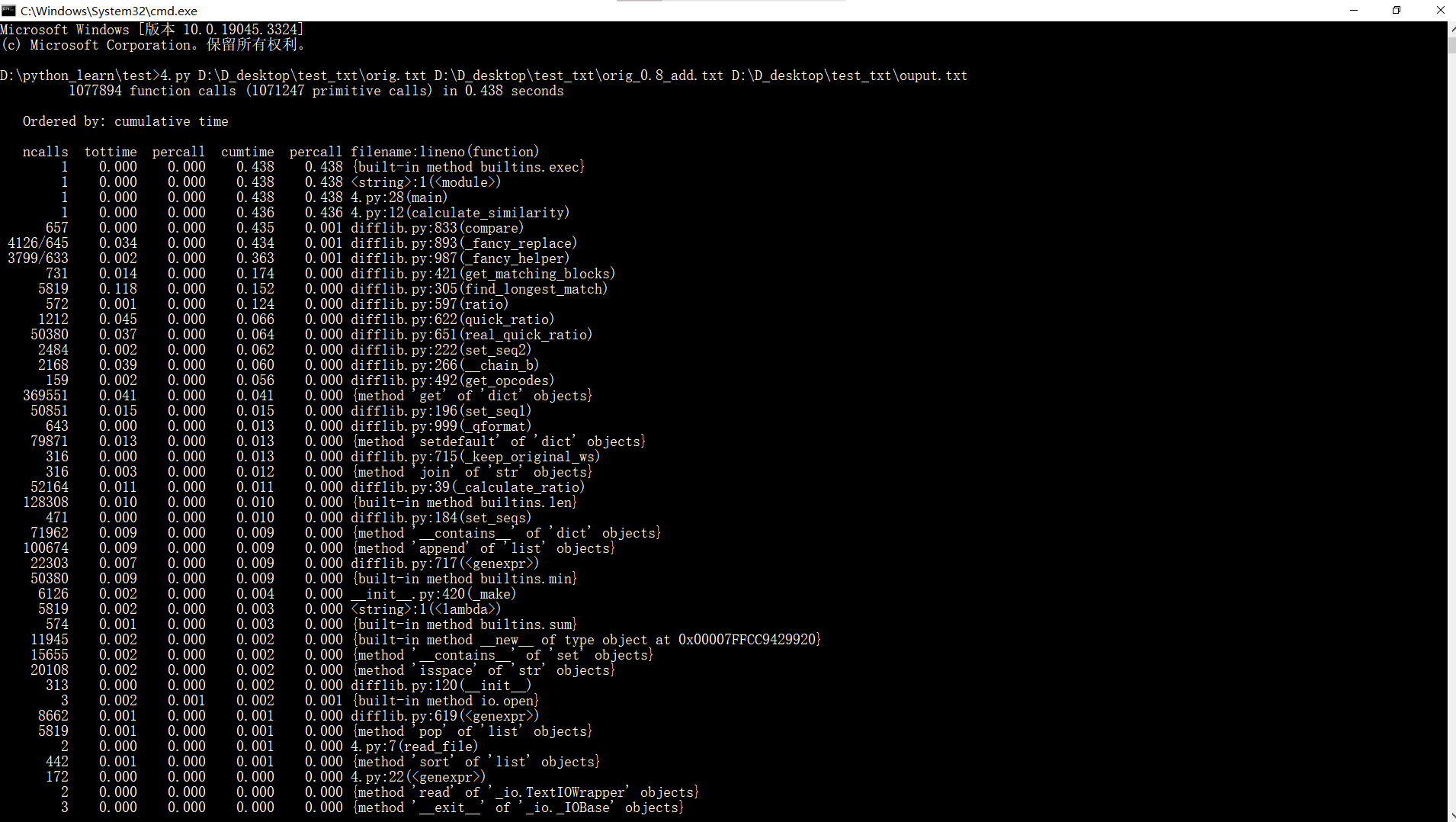
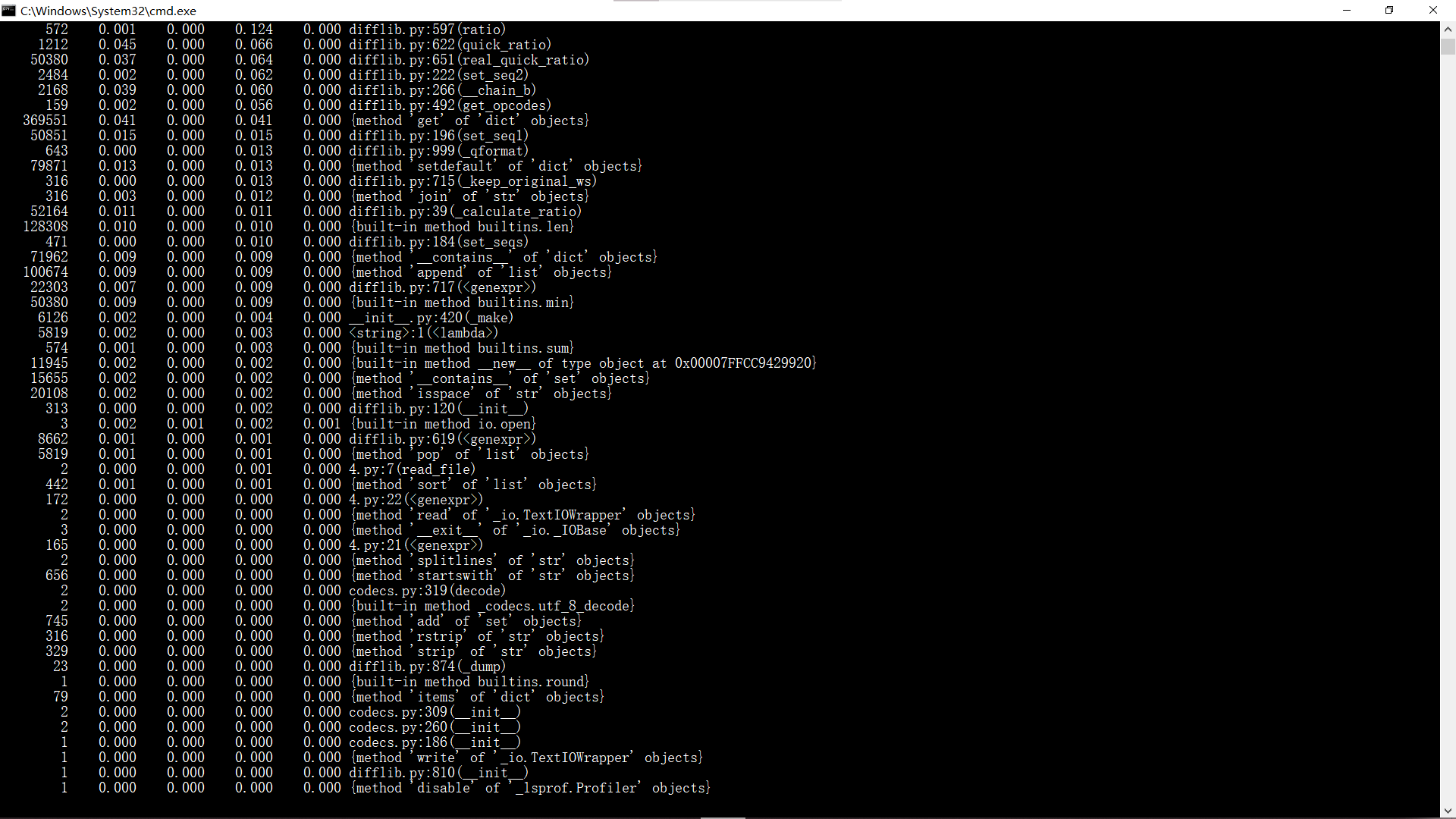
从中可以看出耗时最多的是原文文件和盗版文件的读取和python库的调用。然而,python库的调用快慢无法通过代码优化,文件读取也比较难有较大的速度提升,因此暂无法改进性能。
5 计算模块部分单元测试展示
主函数的测试

6 计算模块部分异常处理说明
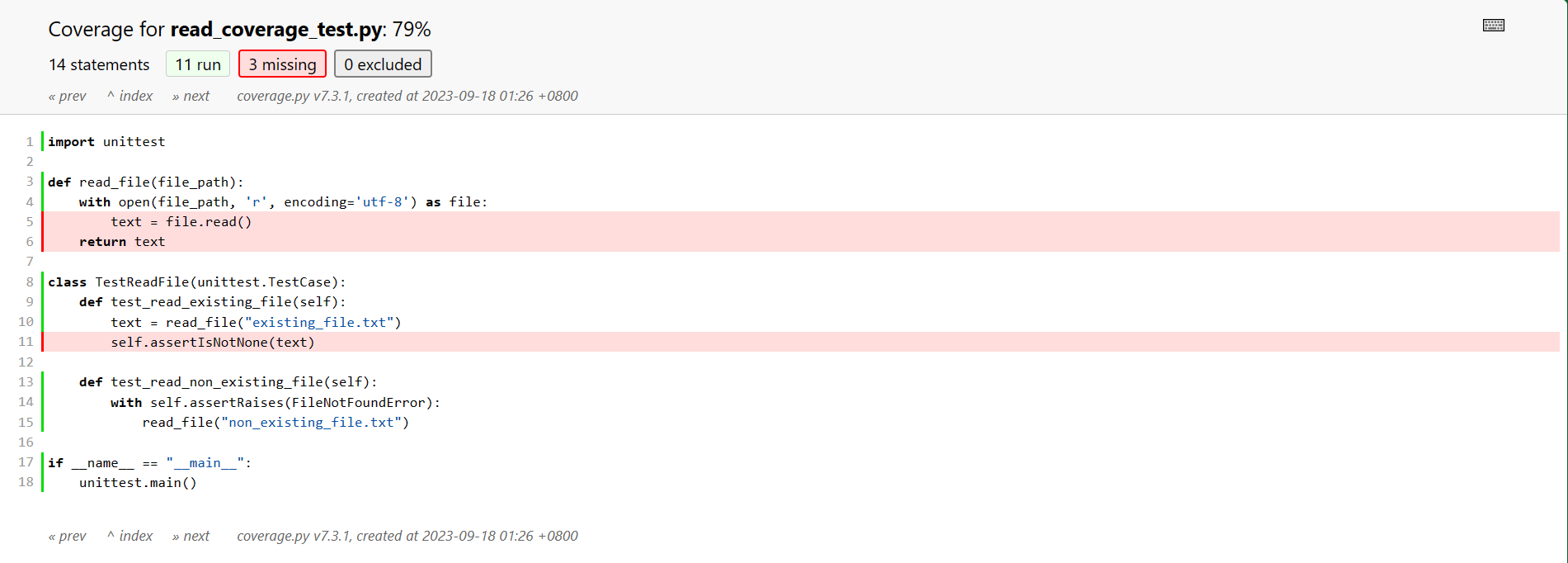
在尝试进行读文件覆盖率计算的时候,发现其覆盖率很低。
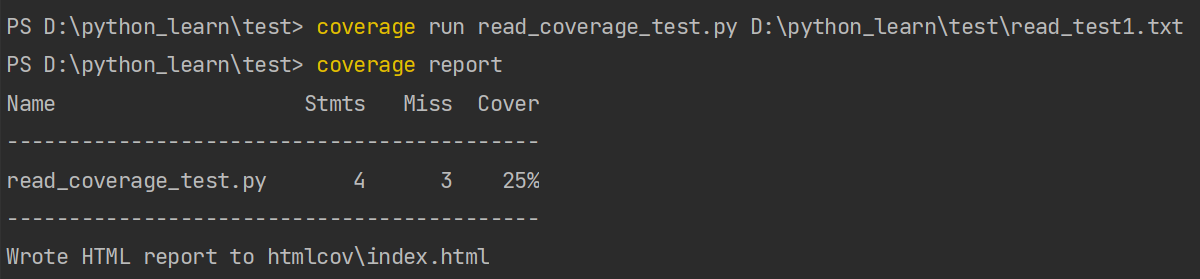
代码从两方面出发,一方面是读成功的检验,另一方面是读失败的检验。而覆盖率低究其原因是文件读取失败,更改过后,覆盖率明显从0.25提升至0.79,覆盖率未满,是因为当文件不存在时,便不会执行读成功的部分。
7 PSP表格实际花费时间
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 25 | 30 |
| Estimate | 估计这个任务需要多少时间 | 15 | 30 |
| Development | 开发 | 25 | 45 |
| Analysis | 需求分析 (包括学习新技术) | 45 | 60 |
| Design Spec | 生成设计文档 | 30 | 45 |
| Design Review | 设计复审 | 20 | 20 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 50 |
| Design | 具体设计 | 25 | 30 |
| Coding | 具体编码 | 30 | 50 |
| Code Review | 代码复审 | 15 | 20 |
| Test | 测试(自我测试,修改代码,提交修改) | 25 | 55 |
| Reporting | 报告 | 45 | 50 |
| Test Report | 测试报告 | 30 | 30 |
| Size Measurement | 计算工作量 | 25 | 30 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 20 | 15 |
| 合计 | 405 | 600 |
