



hadoop集群搭建
一、Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统( Distributed File System),其中一个组件是HDFS(Hadoop Distributed File System)。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算 [1] 。
二、hadoop下载地址(这里使用的是hadoop3.1.3的版本):
https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/hadoop-3.1.3.tar.gz
三、集群搭建步骤
1、准备3台机器,可以使用虚拟机,我这里使用的为VMware16以及centos7.6版本
2、修改3台机器IP分别为:192.168.5.101/102/103(红色为修改部分)
TYPE="Ethernet" PROXY_METHOD="none" BROWSER_ONLY="no" BOOTPROTO="static" DEFROUTE="yes" IPV4_FAILURE_FATAL="no" IPV6INIT="yes" IPV6_AUTOCONF="yes" IPV6_DEFROUTE="yes" IPV6_FAILURE_FATAL="no" IPV6_ADDR_GEN_MODE="stable-privacy" NAME="ens33" UUID="d2df14d6-3636-4460-ba08-184fda131530" DEVICE="ens33" ONBOOT="yes" IPADDR="192.168.5.101/102/103" NETMASK="255.255.255.0" GATEWAY="192.168.5.2"
3、修改hostname为hadoop101/102/103
vi /etc/hostname

4、在hosts中加入地址和hadoop101/102/103的映射

5、安装JDK
参考:https://www.cnblogs.com/ll409546297/p/6993936.html
6、hadoop环境搭建
1)将hadoop-3.1.3.tar.gz复制到/opt目录下
2)解压:
tar -zxvf hadoop-3.1.3.tar.gz
3)配置环境
vi /etc/profile
加入:
# set hadoop export HADOOP_HOME=/opt/hadoop-3.1.3 export PATH=$PATH:$HADOOP_HOME/bin
7、SSH 无密钥访问(一定要加上自己)
ssh-keygen -t rsa
ssh-copy-id hadoop101/102/103
8、集群配置
1)集群配置结果
hadoop101:nameNode,dataNode,nodeManager
hadoop102:dataNode,resourceManager,nodeManager
hadoop103:secondaryNameNode,dataNode,nodeManager
2)修改配置:core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml
默认文件地址:
$HADOOP_HOME/share/doc/hadoop/hadoop-project-dist/hadoop-common/core-default.xml
$HADOOP_HOME/share/doc/hadoop/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
$HADOOP_HOME/share/doc/hadoop/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
$HADOOP_HOME/share/doc/hadoop/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml
修改目目标地址:$HADOOP_HOME/etc/hadoop
a、core-site.xml
<configuration> <!-- nameNode地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop101:8020</value> </property> <!-- 数据存放地址 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/hadoop-3.1.3/data</value> </property> <!-- 页面可操作用户 --> <property> <name>hadoop.http.staticuser.user</name> <value>root</value> </property> </configuration>
b、hdfs-site.xml
<configuration> <!-- web访问地址 --> <property> <name>dfs.namenode.http-address</name> <value>hadoop101:9870</value> </property> <!-- 2nn web地址 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop103:9868</value> </property> </configuration>
c、yarn-site.xml
<configuration> <!-- 指定MR走shuffle --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定resourceManager --> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop102</value> </property> <!-- 环境变量继承 --> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> <!-- 日志聚集开启 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 日志聚集地址 --> <property> <name>yarn.log.server.url</name> <value>http://hadoop101:19888/jobhistory/logs</value> </property> <!-- 日志保存天数(7天) --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> </configuration>
d、mapred-site.xml
<configuration> <!-- 走yarn --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- 历史服务器地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop101:10020</value> </property> <!-- 历史WEB界面地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop101:19888</value> </property> </configuration>
e、修改works

f、同步以上文件到其他节点方式(rsync更快)
scp -r $dir/$file $user@$host:$targetDir/$targetFile
or
rsync -av $dir/$file $user@$host:$targetDir/$targetFile
9、启动集群(出现错误删除data和logs)
1)第一次启动:在hadoop101上面执行
hdfs namenode -format
2)启动和停止:脚本在$HADOOP_HOME/sbin
hadoop101:start-dfs.sh/stop-dfs.sh (HDFS)
hadoop102:start-yarn.sh/stop-yarn.sh (YARN)
hadoop101:mr-jobhistory-daemon.sh start/stop historyserver(HISTORY-SERVER)
root启动:
在start-dfs.sh/stop-dfs.sh中加入:
HDFS_DATANODE_USER=root HADOOP_SECURE_DN_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root
在start-yarn.sh/stop-yarn.sh中加入:
YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root
3)如果出现启动JAVA_HOME错误
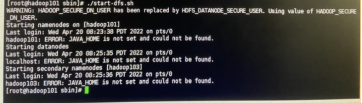
添加:$HADOOP_HOME/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_202
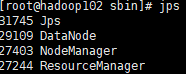
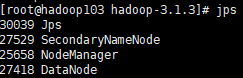
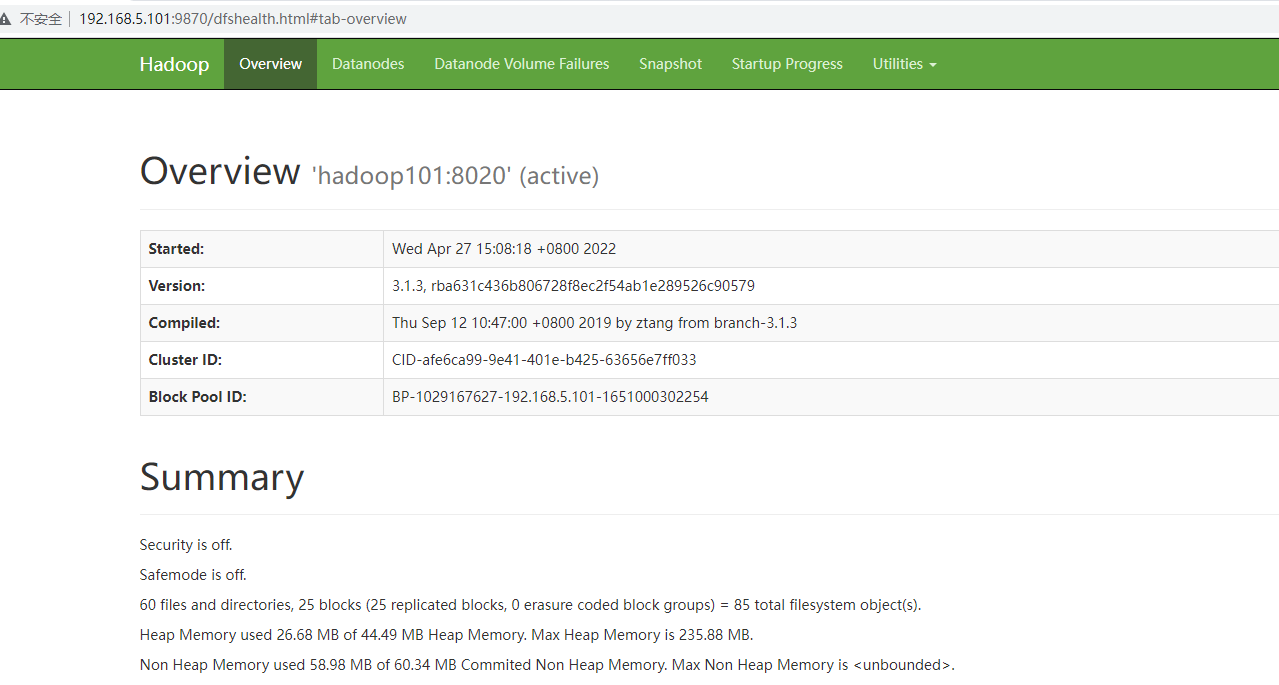
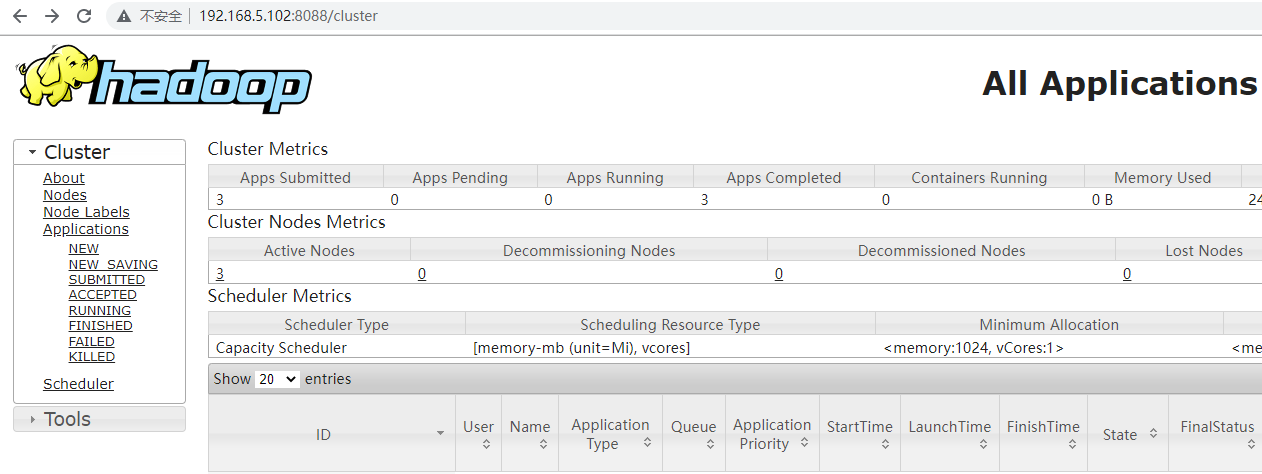
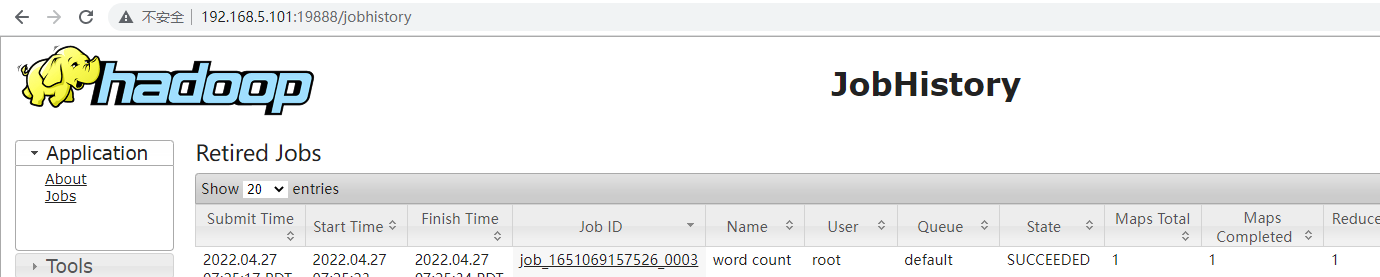
4)启动后查看页面是否正常
hadoop101:
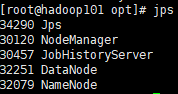
hadoop102:
hadoop103:
hdfs:http://192.168.5.101:9870/
yarn:http://192.168.5.103:8088
history:http://192.168.5.101:19888/
10、测试
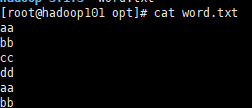
1)创建word.txt文件加入数据
2)建立和上传目录
# hadoop fs -mkdir /input
# hadoop fs -put /opt/word.txt /input
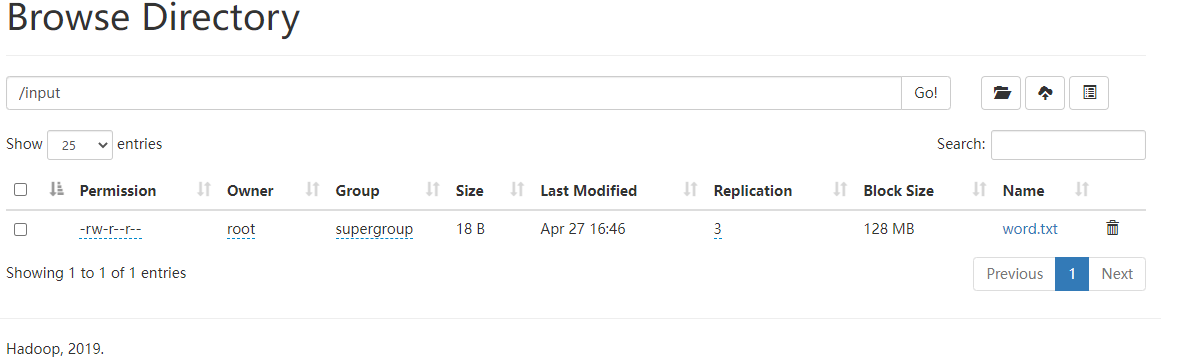
3)执行测试
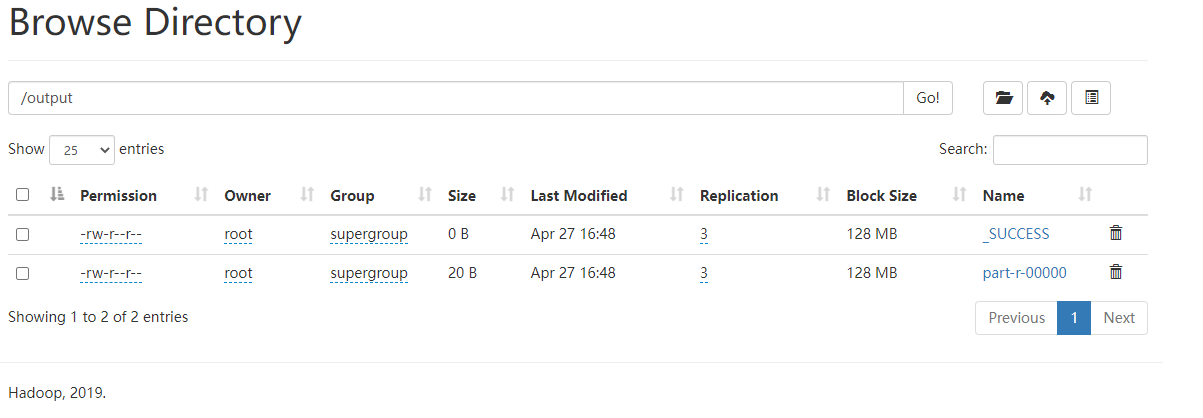
# hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
hdfs:
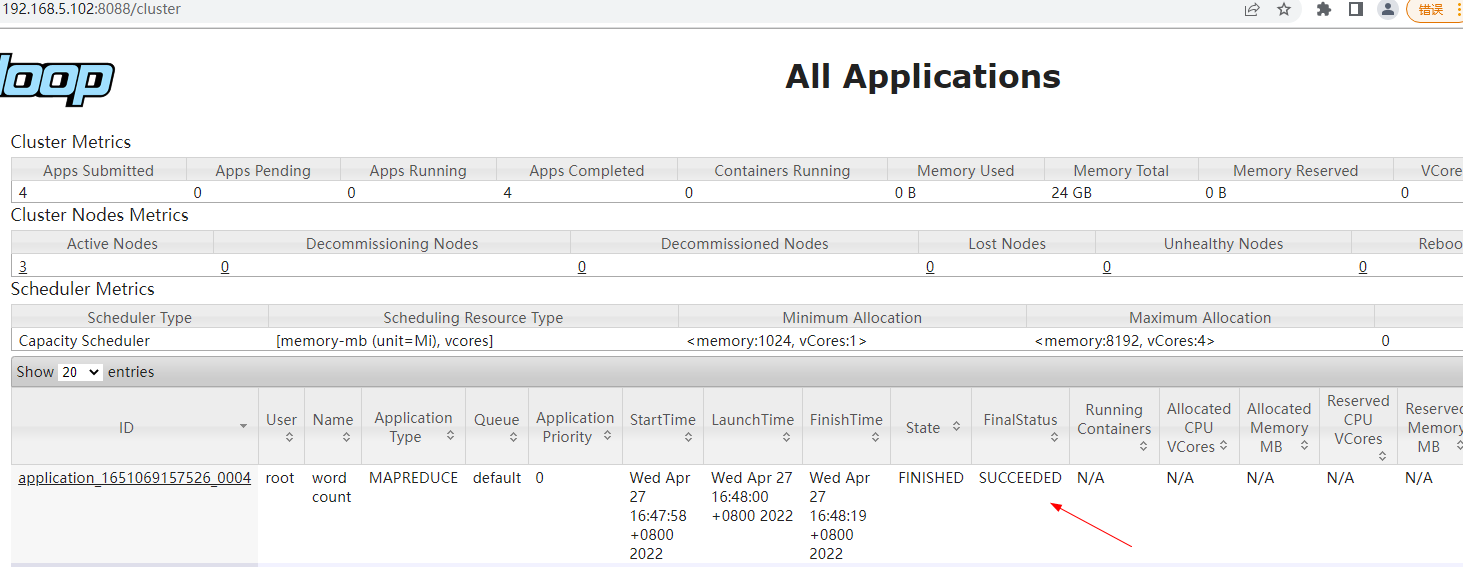
yarn:
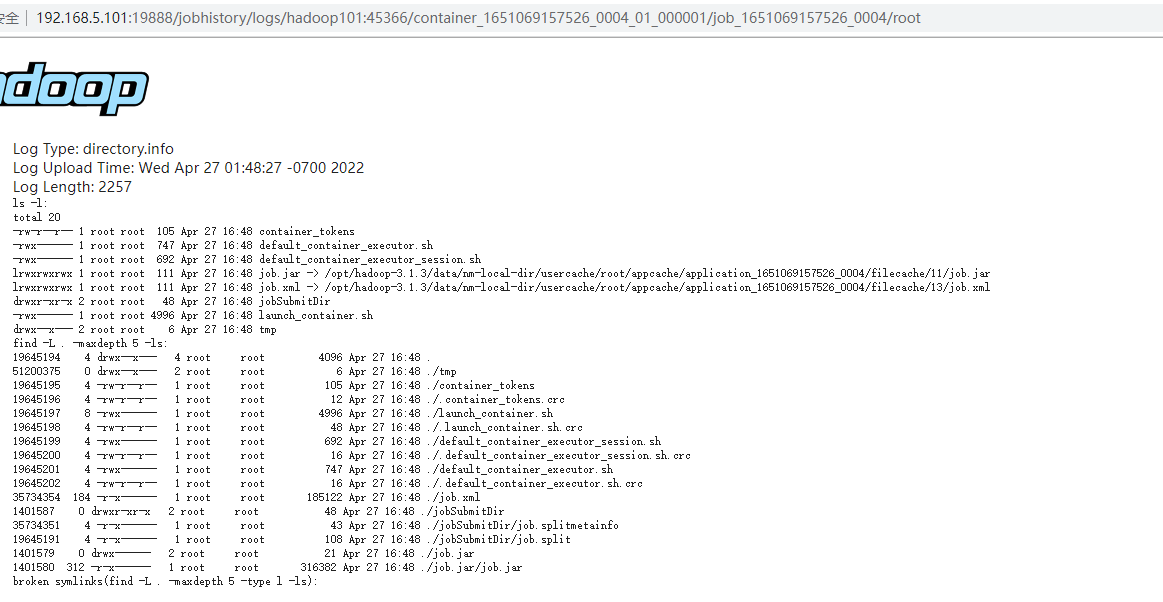
history-log:
四、总结:整个集群搭建步骤基本就如上面所示了,细节很多,需要用心体会

