

Python之TensorFlow的卷积神经网络-5
一、卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习(deep learning)的代表算法之一 [1-2] 。卷积神经网络具有表征学习(representation learning)能力,能够按其阶层结构对输入信息进行平移不变分类(shift-invariant classification),因此也被称为“平移不变人工神经网络(Shift-Invariant Artificial Neural Networks, SIANN)” [3] 。
二、上面说的感觉太专业化了,我们简单一点以图片为例。卷积神经网络就是通过平移的方式在一张图片上面,取一个1*1/3*3/5*5的方格。通过特征计算,得出下一个矩阵值(也就是提取后的特征图片)
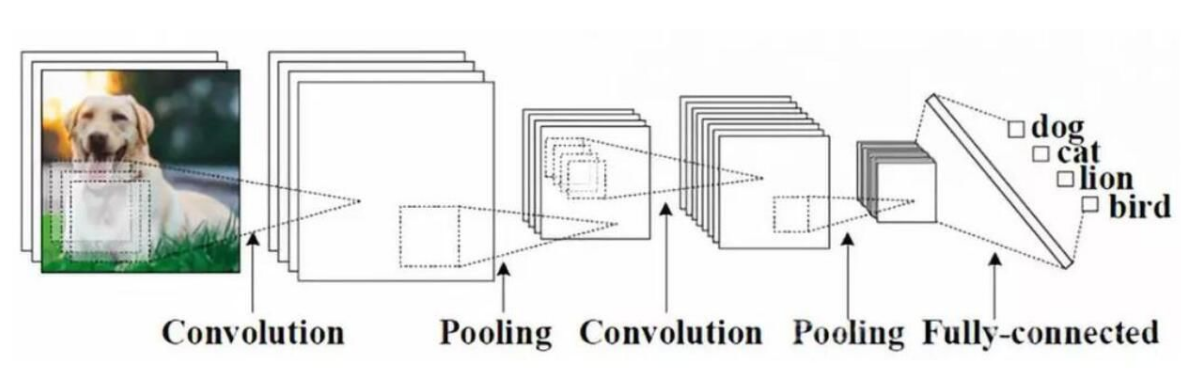
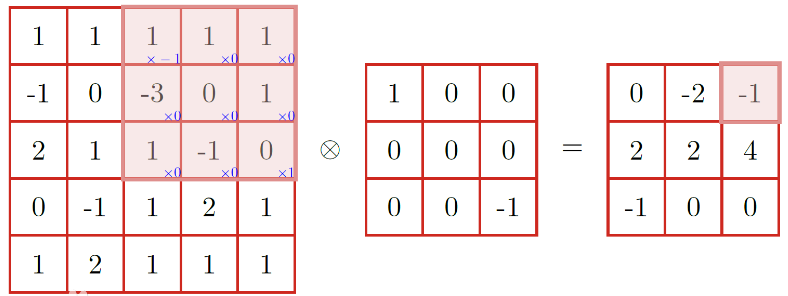
通过上面两种方式,可以看出,卷积的效果就是从一张大的图片,提取成一张小的图片。
三、认识神经网络
感知机: 有n个输入数据,通过权重与各数据的之间的计算和,比较激活函数结果,得出输出。 解决分类问题 一般采用多个感知机进行分类问题的处理 神经元: 就是感知机的别名 多个神经元组成神经网络 特点: 输入向量的维度和输入神经元的个数相同 每个连接都有权重 同一层神经元之间没有连接 由输入层、隐层、输出层组成 第N层到第N-1层所有神经元连接也叫全连接 组成: 结构、激活函数、学习规则 神经网络TensorFlow的API模块: 1、tf.nn: 提供神经网络相关操作的支持,包括卷积(conv)等 2、tf.layers: 主要提供高层的神经网络,主要和卷积相关,对tf.nn的经一步封装 3、tf.contrib: tf.contrib.layers提供能够将计算图中的网络层、正则化、摘要操作(构建计算机图的高级操作),但是tf.contrib不稳定
网站:http://playground.tensorflow.org
四、浅层人工神经网络模型
浅层人工神经网络模型: softmax回归: e^i 公式:Si = —————— ∑je^j Si:该分类的概率, e^i:e的全连接层的分类结果值的次方,∑je^j:所有e的全连接层的分类结果值的次方 损失计算api: 算法 策略 优化 线性回归 均方误差 梯度下降 逻辑回归 对数似然损失 梯度下降 神经网络 交叉熵损失 反向传播算法(梯度下降) 交叉熵损失: 公式:Hy'(y) = -∑yi'log(yi) i yi':真实结果,yi:softmax结果 衡量两者差异的一种方式 反向传播: 正向传播:输出经过一层一层计算得出结果 反向传播:从损失计算开始,梯度下降更新权重 API: 特征加权: tf.matmul(<a>, <b>, <name=None>) + bias return:全连接结果,供交叉损失计算 不需要激活函数 softmax计算、交叉熵: tf.nn.softmax_cross_entropy_with_logits(<label=None>, <logits=None>, <name=None>) labels:标签值(真实值) logits:样本加权过后的值 return:返回损失值列表 计算logits与labels之间的交叉损失熵 损失值列表平均值: tf.reduce_mean(<input_tensor>) 计算张量的尺寸的元素平均值 其他api: 损失下降(梯度下降): tf.train.GradientDescentOptimizer(<learning_rate>) learning_rate:学习率 return:梯度下降OP 准确率计算: equal_list = tf.equal(<tf.argmax(y, 1)>, <tf.argmax(y_label, 1)>) accuracy = tf.reduce_mean(<tf.cast(equal_list, tf.float32)>) Mnist数据集神经网络实现流程: 1、准备数据 2、全连接计算结果 3、损失优化 4、模型评估(计算准确性)
上面给出了一种梯度下降的方式来做损失值优化,但是实际生产中运用的是其他的优化方法比如:
tf.train.GradientDescentOptimizer()
tf.train.ProximalGradientDescentOptimizer()
tf.train.AdagradOptimizer()
tf.train.ProximalAdagradOptimizer()
tf.train.AdagradDAOptimizer()
tf.train.AdadeltaOptimizer()
tf.train.AdamOptimizer()
tf.train.RMSPropOptimizer()
tf.train.FtrlOptimizer()
tf.train.MomentumOptimizer()
这里提到了一个概念叫全连接。什么叫全连接层?全连接层的每一个结点都与上一层的所有结点相连,用来把前边提取到的特征综合起来。
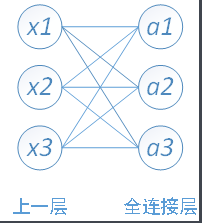
可以看出,全连接层就是每一个节点都与上一层的节点全部连接。一般出现在预测的最后一层。
我们看一个例子
# 训练,隐藏层直接是全连接层 def mnist_train(): # 1、准备数据(因为数据是实时传入的所以使用占位符) with tf.variable_scope("data"): x = tf.placeholder(dtype=tf.float32, shape=[None, 784], name="x") y_true = tf.placeholder(dtype=tf.float32, shape=[None, 10]) # 2、建立模型(全连接层的神经网络,这里只有一层) with tf.variable_scope("model"): # 随机初始化权重和偏置 w = tf.Variable(tf.random_normal([784, 10], name="weight")) b = tf.Variable(tf.constant(0.0, shape=[10]), name="bias") y_predict = tf.matmul(x, w) + b # 3、计算损失函数 with tf.variable_scope("loss"): softmax_cross = tf.nn.softmax_cross_entropy_with_logits(labels=y_true, logits=y_predict) loss = tf.reduce_mean(softmax_cross) # 4、梯度下降求出损失值 with tf.variable_scope("optimizer"): train_op = tf.train.GradientDescentOptimizer(learning_rate=0.1).minimize(loss=loss) # 5、计算准确率 with tf.variable_scope("accuracy"): equal_list = tf.equal(tf.argmax(y_true, 1), tf.argmax(y_predict, 1)) accuracy = tf.reduce_mean(tf.cast(equal_list, tf.float32)) # 收集数据 tf.summary.scalar("losses", loss) tf.summary.scalar("accuracies", accuracy) tf.summary.histogram("weight", w) tf.summary.histogram("bias", b) merged = tf.summary.merge_all() tf.add_to_collection("y_predict", y_predict) # 变量初始化 init_op = tf.global_variables_initializer() # 6、会话 with tf.Session() as sess: # 变量初始化 sess.run(init_op) # 准备真实数据 mnist = input_data.read_data_sets("data/mnist/input_data", one_hot=True) # 将收集的数据写入文件 writer = tf.summary.FileWriter("tmp/summary/mnist", graph=sess.graph) # 模型保存 saver = tf.train.Saver() # 读取端点模型 if os.path.exists("model/mnist/checkpoint"): saver.restore(sess, "model/mnist/mnist") # 训练 for i in range(4000): # 准备数据 x_train, y_train = mnist.train.next_batch(100) # 训练 sess.run(train_op, feed_dict={x: x_train, y_true: y_train}) # 收集数据写入文件 summary = sess.run(merged, feed_dict={x: x_train, y_true: y_train}) writer.add_summary(summary, i) # 保存模型 if (i + 1) % 100 == 0: saver.save(sess, "model/mnist/mnist") # 准确率 print("第%d步,准确率:%f" % ((i + 1), sess.run(accuracy, feed_dict={x: x_train, y_true: y_train})))
def mnist_predict(): with tf.Session() as sess: # 1、加载模型 saver = tf.train.import_meta_graph("model/mnist/mnist.meta") saver.restore(sess, tf.train.latest_checkpoint("model/mnist")) graph = tf.get_default_graph() # 2、获取占位符 x = graph.get_tensor_by_name("data/x:0") # 3、获取权重和偏置 y_predict = graph.get_collection("y_predict")[0] # 4、读取测试数据 mnist = input_data.read_data_sets("data/mnist/input_data", one_hot=True) # 5、预测 for i in range(100): x_test, y_test = mnist.test.next_batch(1) predict = sess.run(y_predict, feed_dict={x: x_test}) print("第%d个图片,预测值:%d, 真实值:%d" % ((i + 1), tf.argmax(predict, 1).eval(), tf.argmax(y_test, 1).eval()))
注意:这里是没有进行卷积想过的,所以隐藏层只有全连接层。
五、深层的神经网络
深层的神经网络: 深度学习网络与常见的单一隐藏层神经网络的区别在于深度 深度学习网络中,每一个节点层在前一层的输出的基础上,学习识别一组特定的特征 随着神经网络深度增加,节点所能识别的特征也越来越复杂。 卷积神经网络: 全连接层的缺点: 权重数据过多,如果图片更大,权重会个数会更大 没有利用像素之间的位置关系,对于图片来说,像素之间的关系更加紧密 层数限制 隐藏层分为: 卷积层:通常在图像上平移来提取特征 过滤器(观察窗口)大小,步长(移动的像素,一般为1) 如果不越过像素,直接停止(VALID不越过边缘,取样小于边缘宽度)。 如果越过像素,进行零填充(在其他像素位置添加0)(SAME越过边缘取样,取样和输入面积一致)。 输入:H1 * W1 * D1 超参数:Filter数量K,Filter大小F,步长S,零填充P 输出: H2 = (H1 - F + 2P)/S + 1 W2 = (W1 - F + 2P)/S + 1 D2 = K API: tf.nn.conv2d(<input>, <filter>, <strides>, <padding>, <name=None>) input: 给定的输入张量[batch, height, width, channel] filter: 指定过滤器大小[filter_height, filter_width, in_channels, out_channels] strides: 步长[1, stride, stride, 1] padding: "SAME"(越过), "VALID"(舍弃) 激活函数: 增加网络的非线性分割能力 为什么实用Relu: 1、采用sigmoid等函数,方向传播求误差梯度时,计算量相对较大,而采用Relu激活函数,整个过程计算量节省很多 2、对于深层网络,sigmoid函数方向传播时,很容易出现梯度爆炸的情况 API: tf.nn.relu(<features>, <name=None>) features: 卷积后加上偏置的结果 池化层(采样层):通过提取特征后减少学习参数,降低网络复杂度(最大化池和平均池) 主要作用就是特征提取,通过去掉Fetrue Map中不重要的样本,进一步减少参数数量。 Pooling的方法很多,最常用的是MaxPooling。2 * 2 步长2 API: tf.nn.max_pool(<value>, <ksize>, <strides>, <padding>, <name=None>) value: 4-DTensor形状[batch, height, width, channels] ksize: 池化窗口大小[1, ksize, ksiez, 1] strides: 步长大小[1, stride, stride, 1] padding: "SAME"(越过), "VALID"(舍弃) 全连接层: 前面的卷积和池化相当于做特征工程,后面的全连接层相当于特征加权。 最后的全连接层在整个卷积神经网络中起到分类器的作用。
通过例子来说明:
# 卷积神经网络 def mnist_conv_train(): # 1、读取真实数据 mnist = input_data.read_data_sets("data/mnist/input_data", one_hot=True) # 2、生成模型 x, y_true, y_predict = conv_model() tf.add_to_collection("y_predict", y_predict) # 3、计算损失函数 with tf.variable_scope("loss"): # 计算平均交叉熵损失 softmax_cross = tf.nn.softmax_cross_entropy_with_logits(labels=y_true, logits=y_predict) loss = tf.reduce_mean(softmax_cross) # 4、梯度下降求出损失值 with tf.variable_scope("optimizer"): train_op = tf.train.GradientDescentOptimizer(learning_rate=0.0001).minimize(loss=loss) # 5、计算准确率 with tf.variable_scope("accuracy"): equal_list = tf.equal(tf.argmax(y_true, 1), tf.argmax(y_predict, 1)) accuracy = tf.reduce_mean(tf.cast(equal_list, tf.float32)) # 6、会话训练 with tf.Session() as sess: # 初始化变量 sess.run(tf.global_variables_initializer()) # 模型保存 saver = tf.train.Saver() # 读取端点模型 if os.path.exists("model/mnist_conv/checkpoint"): saver.restore(sess, "model/mnist_conv/mnist") # 训练 for i in range(2000): # 准备数据 x_train, y_train = mnist.train.next_batch(100) # 训练 sess.run(train_op, feed_dict={x: x_train, y_true: y_train}) # 保存模型 if (i + 1) % 100 == 0: saver.save(sess, "model/mnist_conv/mnist") # 准确率 print("第%d步,准确率:%f" % ((i + 1), sess.run(accuracy, feed_dict={x: x_train, y_true: y_train}))) def conv_model(): # 1、建立占位符 with tf.variable_scope("data"): x = tf.placeholder(dtype=tf.float32, shape=[None, 784], name="x") y_true = tf.placeholder(dtype=tf.float32, shape=[None, 10]) # 2、第一次卷积 with tf.variable_scope("conv_1"): # 修改数据形状 x_reshape = tf.reshape(x, shape=[-1, 28, 28, 1]) # 卷积[None, 28, 28, 1] -> [None, 28, 28, 32] 32为观察者个数 w_1 = gen_weight([5, 5, 1, 32]) b_1 = gen_bias([32]) x_conv_1 = tf.nn.conv2d(x_reshape, filter=w_1, strides=[1, 1, 1, 1], padding="SAME") + b_1 # 激活 x_relu_1 = tf.nn.relu(x_conv_1) # 池化[None, 28, 28, 32] -> [[None, 14, 14, 32]] x_pool_1 = tf.nn.max_pool(x_relu_1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME") # 3、第二层卷积 with tf.variable_scope("conv_2"): # 卷积[[None, 14, 14, 32]] -> [[None, 14, 14, 64]] w_2 = gen_weight([5, 5, 32, 64]) b_2 = gen_bias([64]) x_conv_2 = tf.nn.conv2d(x_pool_1, filter=w_2, strides=[1, 1, 1, 1], padding="SAME") + b_2 # 激活 x_relu_2 = tf.nn.relu(x_conv_2) # 池化[[None, 14, 14, 64]] -> [[None, 7, 7, 64]] x_pool_2 = tf.nn.max_pool(x_relu_2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME") # 4、全连接层 with tf.variable_scope("full_connection"): # 生成权重和偏置 w_fc = gen_weight([7 * 7 * 64, 10]) b_fc = gen_bias([10]) # 修改数据形状 x_fc = tf.reshape(x_pool_2, shape=[-1, 7 * 7 * 64]) y_predict = tf.matmul(x_fc, w_fc) + b_fc return x, y_true, y_predict # 生成权重值 def gen_weight(shape): return tf.Variable(tf.random_normal(shape=shape, mean=0.0, stddev=1.0, dtype=tf.float32)) # 生成偏值 def gen_bias(shape): return tf.Variable(tf.constant(0.0, dtype=tf.float32, shape=shape))
def mnist_conv_predict(): with tf.Session() as sess: # 1、加载模型 saver = tf.train.import_meta_graph("model/mnist_conv/mnist.meta") saver.restore(sess, tf.train.latest_checkpoint("model/mnist_conv")) graph = tf.get_default_graph() # 2、获取占位符 x = graph.get_tensor_by_name("data/x:0") # 3、获取权重和偏置 y_predict = graph.get_collection("y_predict")[0] # 4、读取测试数据 mnist = input_data.read_data_sets("data/mnist/input_data", one_hot=True) # 5、预测 for i in range(100): x_test, y_test = mnist.test.next_batch(1) predict = sess.run(y_predict, feed_dict={x: x_test}) print("第%d个图片,预测值:%d, 真实值:%d" % ((i + 1), tf.argmax(predict, 1).eval(), tf.argmax(y_test, 1).eval()))
注意:上面的基本步骤基本没啥变化,主要变化的就是模型。这里则是做了2层卷积,但是运算量真的不小的哦。
六、总结一下吧,这里我们都是手动的去卷积数据,需要我们自己计算卷积后的维度,还是比较麻烦的。实际生产环境中,我们一般都是针对图片数据比较大的才会使用卷积神经网络,一般都会采用别人弄好的一些卷积模型。比如
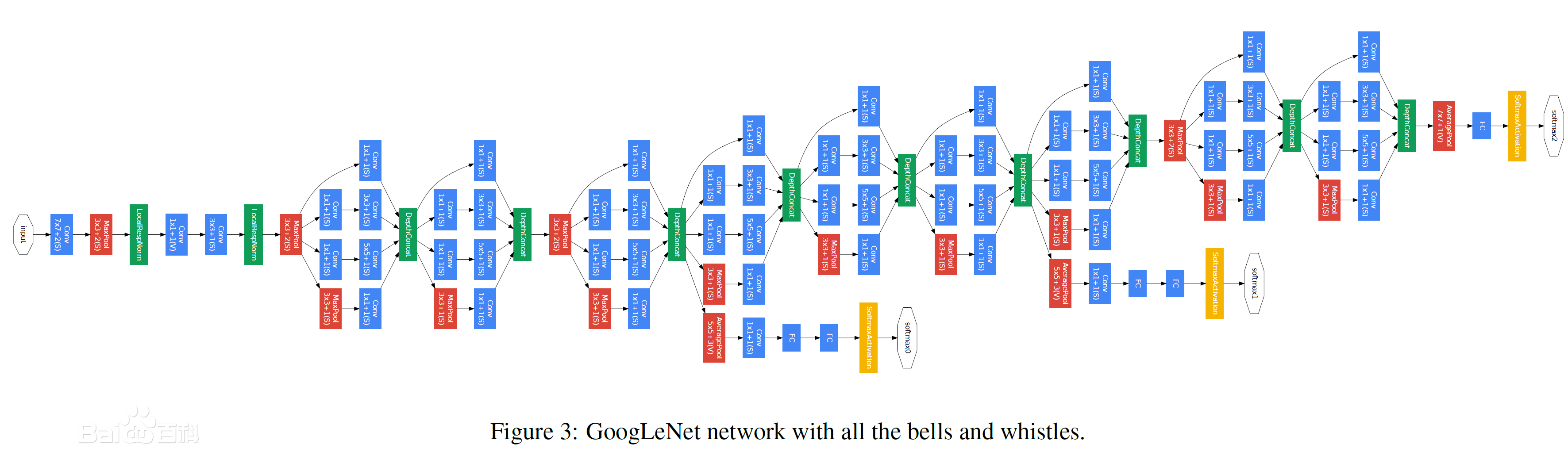
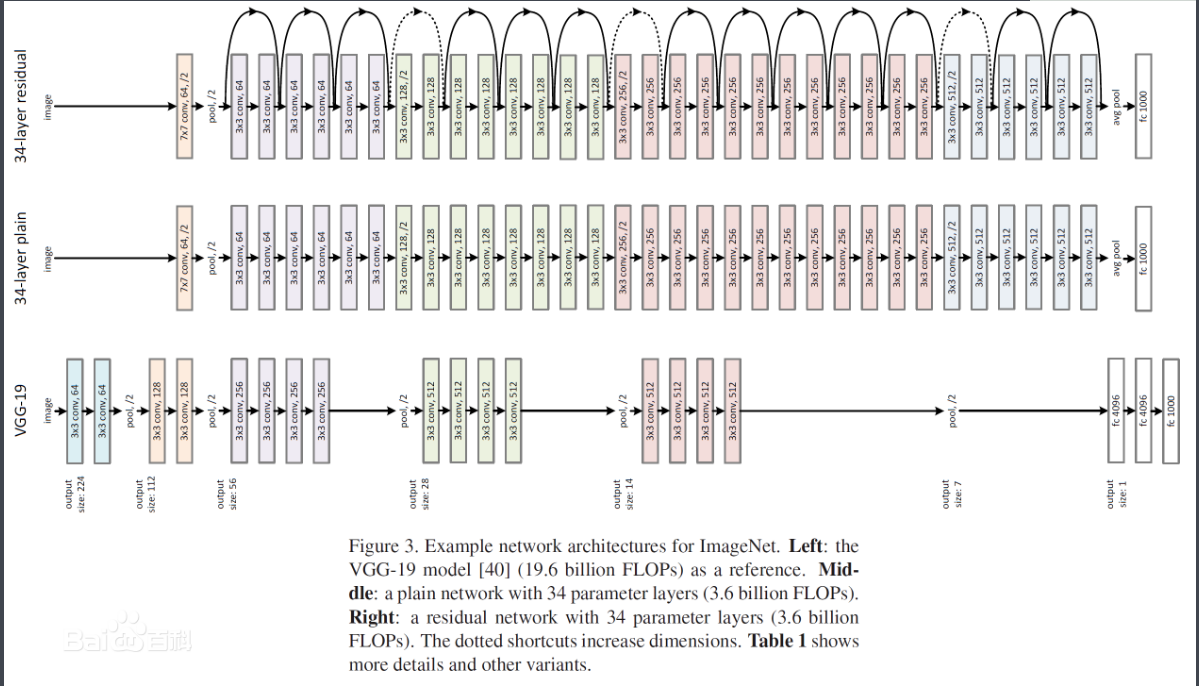
当然目前已经表成熟的卷积模型LeNet、AlexNet、VGGNet等,这里不做介绍了。

