


Python之(scrapy)爬虫
一、Scrapy是Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持。
Scrapy是一个为爬取网站数据、提取结构性数据而设计的应用程序框架,它可以应用在广泛领域:Scrapy 常应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定网站的内容或图片。
二、结构图
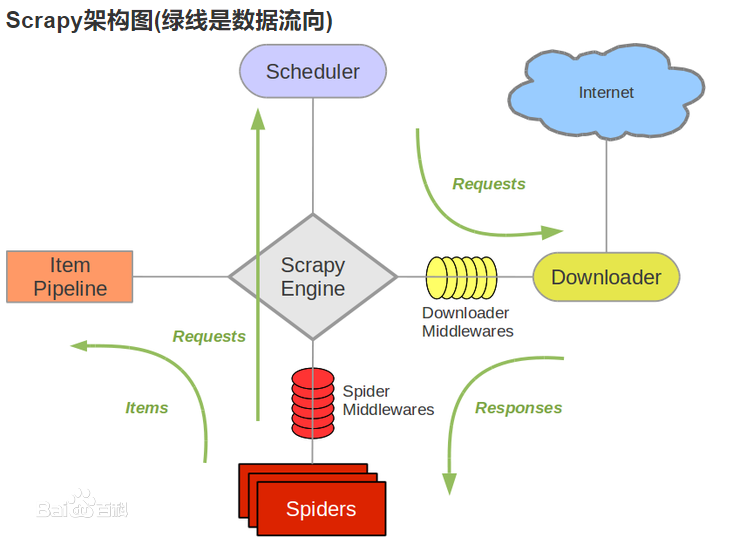
三、框架介绍(入门):
常用命令:
1)新建项目
scrapy startproject <project_name>
2)爬虫爬取
scrapy crawl <spider_name>
3)生成爬虫文件
scrapy genspider [-t template] <name> <domain>
目录结构:
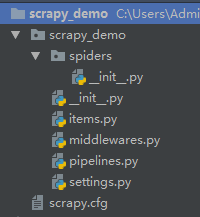
这里重点介绍文件的意义:
1)scrapy.cfg(主要用来指定配置和名称等)
# Automatically created by: scrapy startproject # # For more information about the [deploy] section see: # https://scrapyd.readthedocs.io/en/latest/deploy.html [settings] default = scrapy_demo.settings [deploy] #url = http://localhost:6800/ project = scrapy_demo
2)settings.py
# -*- coding: utf-8 -*- # Scrapy settings for scrapy_demo project # # For simplicity, this file contains only settings considered important or # commonly used. You can find more settings consulting the documentation: # # https://doc.scrapy.org/en/latest/topics/settings.html # https://doc.scrapy.org/en/latest/topics/downloader-middleware.html # https://doc.scrapy.org/en/latest/topics/spider-middleware.html BOT_NAME = 'scrapy_demo' SPIDER_MODULES = ['scrapy_demo.spiders'] NEWSPIDER_MODULE = 'scrapy_demo.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent #USER_AGENT = 'scrapy_demo (+http://www.yourdomain.com)' # Obey robots.txt rules ROBOTSTXT_OBEY = True # Configure maximum concurrent requests performed by Scrapy (default: 16) #CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0) # See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs #DOWNLOAD_DELAY = 3 # The download delay setting will honor only one of: #CONCURRENT_REQUESTS_PER_DOMAIN = 16 #CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default) #COOKIES_ENABLED = False # Disable Telnet Console (enabled by default) #TELNETCONSOLE_ENABLED = False # Override the default request headers: #DEFAULT_REQUEST_HEADERS = { # 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', # 'Accept-Language': 'en', #} # Enable or disable spider middlewares # See https://doc.scrapy.org/en/latest/topics/spider-middleware.html #SPIDER_MIDDLEWARES = { # 'scrapy_demo.middlewares.ScrapyDemoSpiderMiddleware': 543, #} # Enable or disable downloader middlewares # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html #DOWNLOADER_MIDDLEWARES = { # 'scrapy_demo.middlewares.ScrapyDemoDownloaderMiddleware': 543, #} # Enable or disable extensions # See https://doc.scrapy.org/en/latest/topics/extensions.html #EXTENSIONS = { # 'scrapy.extensions.telnet.TelnetConsole': None, #} # Configure item pipelines # See https://doc.scrapy.org/en/latest/topics/item-pipeline.html #ITEM_PIPELINES = { # 'scrapy_demo.pipelines.ScrapyDemoPipeline': 300, #} # Enable and configure the AutoThrottle extension (disabled by default) # See https://doc.scrapy.org/en/latest/topics/autothrottle.html #AUTOTHROTTLE_ENABLED = True # The initial download delay #AUTOTHROTTLE_START_DELAY = 5 # The maximum download delay to be set in case of high latencies #AUTOTHROTTLE_MAX_DELAY = 60 # The average number of requests Scrapy should be sending in parallel to # each remote server #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # Enable showing throttling stats for every response received: #AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default) # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings #HTTPCACHE_ENABLED = True #HTTPCACHE_EXPIRATION_SECS = 0 #HTTPCACHE_DIR = 'httpcache' #HTTPCACHE_IGNORE_HTTP_CODES = [] #HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
说明:a、BOT_NAME-->项目名称
b、SPIDER_MODULES,NEWSPIDER_MODULE-->爬虫目录,新爬虫目录
c、ROBOTSTXT_OBEY-->是否准守网站规则,robots.txt
d、CONCURRENT_REQUESTS-->并发数
e、DOWNLOAD_DELAY-->现在延时(秒)
f、CONCURRENT_REQUESTS_PER_DOMAIN、CONCURRENT_REQUESTS_PER_IP-->并发请求域和ip
g、COOKIES_ENABLED-->cookie开启
h、TELNETCONSOLE_ENABLED-->telnet是否开启
i、DEFAULT_REQUEST_HEADERS-->默认请求头
j、SPIDER_MIDDLEWARES-->爬虫中间件
k、DOWNLOADER_MIDDLEWARES-->下载中间件
l、EXTENSIONS-->扩展
m、ITEM_PIPELINES-->管道
3)items.py(主要用于模型的定义)
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.html import scrapy # class ScrapyDemoItem(scrapy.Item): # # define the fields for your item here like: # # name = scrapy.Field() # pass class DouYuItem(scrapy.Item): # 标题 title = scrapy.Field() # 热度 hot = scrapy.Field() # 图片url img_url = scrapy.Field()
4)pipelines.py(定义管道,同于后续的数据处理)
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html # class ScrapyDemoPipeline(object): # def process_item(self, item, spider): # return item import urllib2 class DouYuPipline(object): def __init__(self): self.csv_file = open("douyu.csv", "w") def process_item(self, item, spider): text = item["title"] + "," + str(item["hot"]) + "," + item["img_url"] + "\n" # with open("img/" + item["title"] + "_" + str(item["hot"]) + ".jpg", "wb") as f: # f.write(urllib2.urlopen(item["img_url"]).read()) self.csv_file.write(text.encode("utf-8")) return item def close_spider(self, spider): self.csv_file.close()
5)spiders(爬虫目录文件夹,核心内容都在这里)
a、基于scrapy.Spider(基础类)做的开发
# !/usr/bin/python # -*- coding: UTF-8 -*- import json import scrapy import time from scrapy_demo.items import DouYuItem class DouYuSpider(scrapy.Spider): name = "douyu" allowed_domains = ["www.douyu.com", "rpic.douyucdn.cn"] url = "https://www.douyu.com/gapi/rkc/directory/0_0/" page = 1 start_urls = [url + str(page)] def parse(self, response): data = json.loads(response.text)["data"]["rl"] for detail in data: douyu_item = DouYuItem() douyu_item["title"] = detail["rn"] douyu_item["hot"] = detail["ol"] douyu_item["img_url"] = detail["rs1"] yield scrapy.Request(detail["rs1"], callback=self.img_data_handle) yield douyu_item self.page += 1 yield scrapy.Request(self.url + str(self.page), callback=self.parse) def img_data_handle(self, response): with open("img/" + str(time.time()) + ".jpg", "wb") as f: f.write(response.body)
说明:Spider必须实现parse函数
name:爬虫名称(必填)
allowed_domains :允许的域(选填)
start_urls:需要爬虫的网址(必填)
b、基于CrawlSpider(父类为Spider)做的开发
# !/usr/bin/python # -*- coding: UTF-8 -*- # !/usr/bin/python # -*- coding: UTF-8 -*- from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule class DouYuSpider(CrawlSpider): name = "douyuCrawl" # allowed_domains = ["www.douyu.com"] url = "https://www.douyu.com/directory/all" start_urls = [url] links = LinkExtractor(allow="https") rules = [ Rule(links, callback="link_handle") ] def link_handle(self, response): print response.body
说明:rules:匹配链接规则,用来匹配html中的链接。
四、上面介绍了主要的几种文件开发方式、说明一下流程
1)首先会通过Spider目录下的爬虫文件,获取数据,如果存在item的数据返回,可以使用yield或者return
2)然后item数据会进入pipline,进行后续的处理。
3)如果使用yield的方式,回事生成器的方式来做,会一直循环的读取数据,主要退出
五、记住pipline、middleware、都需要在settings.py文件中配置,如果没有配置则说明该管道或者中间件不存在,当然可以设置优先级,数字越小优先级越高
ITEM_PIPELINES = { # 'scrapy_demo.pipelines.ScrapyDemoPipeline': 300, 'scrapy_demo.pipelines.DouYuPipline': 300, }
六、启动
使用命令的方式启动
scrapy crawl <spider-name>
但是这样存在一个问题,不好进行调试,我们一般采用pyCharm方式进行开发,所以通过脚本的方式进行启动
start.py
# !/usr/bin/python # -*- coding: UTF-8 -*- from scrapy import cmdline cmdline.execute(["scrapy", "crawl", "douyuCrawl"])
七、总结:这个和前面使用的Selenium+浏览器插件的使用方式还是存在差异的,这里针对于ajax的处理还是需要人工手动去需要数据的加载,然后在通过接口去获取数据在解析。Selenium+浏览器的方式是通过模拟浏览器的方式来实现js和其他ajax的加载,从效率上面来说,scrapy会更加高效和强大。但是只是从页面来说的话,Selenium+浏览器是一个不错的选择。
