KNN邻近算法
机器学习流程:
- 获取数据
- 数据基本处理
- 特征工程
- 机器学 习
- 模型评估
K近邻算法
简介:
K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。
kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依
据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 kNN方法在类别决策时,只与极少量的相邻样本有关。由于kNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方
法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合。
KNN的三个基本要素
- 距离向量
距离就是特征空间中两个实例点的相似程度的反映。常用的有:欧几里得距离、余弦值(cos), 相关度 (correlation), 曼哈顿距离 (Manhattan distance)等。 - k值选择
即在预测目标点时取几个临近的点来预测。
K值得选取非常重要,因为k值选择过小容易受到噪声数据的影响,k值过大会产生用较大邻域中的训练实例进行预测,学习的近似误差会增大。 - 分类决策规则
即由输出实例的k个邻近的训练实例的多数表决输出实例的类。
KNN实现简单的正负数二分类问题
#导入训练模型
from sklearn.neighbors import KNeighborsClassifier
#准备数据
x=[[1],[2],[3],[-1],[-3],[-10]]
y=[['正数'],['正数'],['正数'],['负数'],['负数'],['负数']]
#创建模型
clf = KNeighborsClassifier(n_neighbors=2)
#训练模型
clf.fit(x,y)
#预测其他值
print(clf.predict([[10]]))
print(clf.predict([[-100]]))
预测结果

n_neighbors:
- int类型参数,可选。默认为5。选择
KNN鸢尾花预测
#导入鸢尾花数据集
from sklearn.datasets import load_iris
#导入训练模型
from sklearn.neighbors import KNeighborsClassifier
#拆分数据集
from sklearn.model_selection import train_test_split
#获取数据集
iris=load_iris()
#提取数据集数据和特征
data=iris.data
target=iris.target
#拆分为 训练数据、测试数据、训练特征、测试特征
x_train,x_test,y_train,y_test=train_test_split(data,target,test_size=0.3)
#创建模型
clf = KNeighborsClassifier(n_neighbors=6)
#训练模型
clf.fit(x_train,y_train)
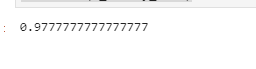
clf.score(x_test,y_test)
测试模型的准确率:
train_test_split:
- 参数列表,传入拆分数据集、拆分特征集
- test_size 拆分多少数据用于测试 0.3:30%数据用于测试
KNN电影类型预测
import math
#特征 1.动作镜头 2.拥抱镜头 3.搞笑镜头 4.类型
#训练数据集
mv = {
'追龙1':[16,2,0,'动作片'],
'人潮汹涌':[8,4,14,'喜剧片'],
'飞驰人生':[3,4,16,'喜剧片'],
'夏洛特烦恼':[0,4,18,'喜剧片'],
'战狼':[18,0,0,'动作片'],
'无双':[14,2,2,'动作片'],
'大人物':[15,0,3,'动作片'],
'从你的全世界路过':[0,7,0,'爱情片'],
'再见前任3':[0,13,2,'爱情片']
}
#预测影片特征 唐人街探案3
x=[23,3,17]
#拆分数据和特征
date=[]
target=[]
for i in mv:
date.append(mv[i][:-1])
target.append(mv[i][-1:])
#创建模型
clf=KNeighborsClassifier(n_neighbors=3)
#训练数据
clf.fit(date,target)
#获取预测类型并添加到字典中
tp=clf.predict([x])[0]
x.append(tp)
mv['唐人街探案3']=x
mv
预测结果


 浙公网安备 33010602011771号
浙公网安备 33010602011771号