项目遇见问题解决记录
问题:
ERROR org.springframework.web.context.ContextLoader:(ContextLoader.java:215)
- Context initialization failed
org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'productSearchServiceBean': Injection of resource methods failed; nested exception is org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'compass' defined in class path resource [beans.xml]: Invocation of init method failed; nested exception is org.compass.core.engine.SearchEngineException: Cannot instantiate Lucene Analyzer [net.paoding.analysis.analyzer.PaodingAnalyzer] for analyzer [default]. Please verify the analyzer setting at [type]; nested exception is net.paoding.analysis.exception.PaodingAnalysisException: dic home should not be a file, but a directory!
解决方案:
①通过search engine 去检索您的所需答案,like this link:http://zhidao.baidu.com/question/273848534.html?qbl=relate_question_0
主要content like follow part:
启动服务器的时候抛出 dic home should not be a file, but a directory!
分析问题:这是因为PaodingMaker.getFile()方法中采用了老版本的java.net.URL.getFile(),不能够识别中文或者空格,只有采用URL.toURI().getPath()才能识别汉字与空格。
解决问题:需要修改一下Paoding中的代码了。找到PaodingMaker.java的setDicHomeProperties方法,修改File dicHomeFile = getFile(dicHome);为
1 File dicHomeFile2 = getFile(dicHome); 2 String path=""; 3 4 try { 5 path = URLDecoder.decode(dicHomeFile2.getPath(),"UTF-8"); 6 } catch (UnsupportedEncodingException e) { 7 e.printStackTrace(); 8 } 9 File dicHomeFile = new File(path);
以上步骤完成后,还需如下step:
①PaodingMaker.java 在哪里?通过分析(by your brain and search engine),该java文件在 https://code.google.com/p/paoding/ 所在的项目中。
【即:
Paoding Analysis摘要
Paoding's Knives 中文分词具有极 高效率 和 高扩展性 。引入隐喻,采用完全的面向对象设计,构思先进。
高效率:在PIII 1G内存个人机器上,1秒 可准确分词 100万 汉字。
采用基于 不限制个数 的词典文件对文章进行有效切分,使能够将对词汇分类定义。
能够对未知的词汇进行合理解析
】
②如何替换项目中引入JAR file 里的PaodingMaker.class文件,思路尝试如下,并成功。在上面googleCode的该项目托管download 该项目的sourceCode,可以针对性的只下载
PaodingMaker.java 文件【目录:paoding - Revision 154: /branches/paoding-for-lucene-2.4/src/net/paoding/analysis/knife】(advice:just try it!),
③直接将downloaded 的 PaodingMaker.java 拖到myeclipse里,或根据该文件package 语句进行创建 package,然后new 该文件,copy all content,如上:进行特定area Code 更改。
④Project-》clean,重新运行【restart server】,完美解决
WEB先加载用户的java class文件,而javaSE先加载jre、java内部提供类
关于java虚拟机JVM原理的相关知识大家可以参考“淘宝大学”的相关power point,个人认为讲的很好!
java ClassLoader的学习
java是一门解释执行的语言,由开发人员编写好的java源文件先编译成字节码文件.class形式,然后由java虚拟机(JVM)解释执行,.class字节码文件本身是平台无关的,但是jvm却不是,为了实现所谓的一次编译,到处执行,sun提供了各个平台的JVM实现--也就是说jvm不是跨平台的,编译好的字节码文件被放在不同的操作系统平台上的jvm所解释执行,这个章节主要解释一下JVM装载类的机制
1.ClassLoader是什么?
一个类如果要被JVM所调度执行,必须先把这个类加载到JVM内存里,java.lang下有个很重要的类ClassLoader,这个类主要就是用来把指定名称(指定路径下)的类加载到JVM中
2.ClassLoader的分类
主要分4类,见下图橙色部分
JVM类加载器:这个模式会加载JAVA_HOME/lib下的jar包
扩展类加载器:会加载JAVA_HOME/lib/ext下的jar包
系统类加载器:这个会去加载指定了classpath参数指定的jar文件
用户自定义类加载器:sun提供的ClassLoader是可以被继承的,允许用户自己实现类加载器
类加载器的加载顺序如图所示:
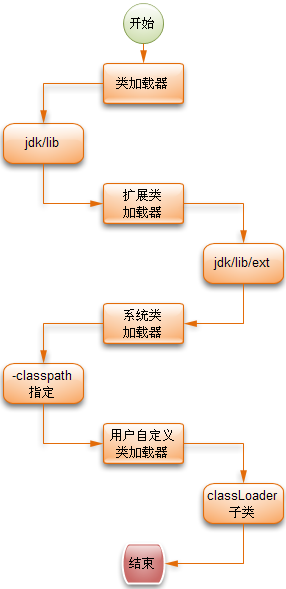
3.类加载顺序
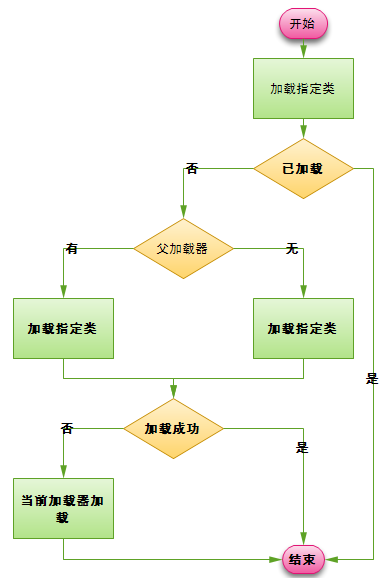
JVM并不是把所有的类一次性全部加载到JVM中的,也不是每次用到一个类的时候都去查找,对于JVM级别的类加载器在启动时就会把默认的JAVA_HOME/lib里的class文件加载到JVM中,因为这些是系统常用的类,对于其他的第三方类,则采用用到时就去找,找到了就缓存起来的,下次再用到这个类的时候就可以直接用缓存起来的类对象了,ClassLoader之间也是有父子关系的,没个ClassLoader都有一个父ClassLoader,在加载类时ClassLoader与其父ClassLoader的查找顺序如下图所示

 浙公网安备 33010602011771号
浙公网安备 33010602011771号