
Hadoop运行环境搭建
目录:
1. 准备虚拟机(最小化安装)
2. 配置一台纯净版模板机
-- 固定ip地址、修改主机名
-- 用xshell工具连接模板机
-- 通过yum安装方式安装必要的软件
-- 关防火墙
-- 修改hosts文件
-- 创建普通户用(atguigu)并且提升它能拥有root权限
-- 在Linux的/opt目录下创建 software 和 module
-- 将software 和 module 目录的所有者和所属组修改为 atguigu
3. 准备hadoop102 机器(通过克隆模板机的方式创建)
-- 修改IP
-- 修改主机名
4. 在hadoop102上安装jdk
-- 将jdk的安装包上传到 /opt/software 下
-- 将jdk安装到 /opt/module 下
-- 配置jdk的环境变量
-- 在/etc/profile.d 目录下创建自定的配置文件 my_env.sh
-- 在my_env.sh写入以下内容
#声明JAVA_HOME变量
JAVA_HOME=/opt/module/jdk1.8.0_212
#将JAVA_HOME变量追加到PATH变量上
PATH=$PATH:$JAVA_HOME/bin
#提升JAVA_HOME变量为系统变量
export JAVA_HOME PATH
5. 在hadoop102上安装hadoop
-- 将hadoop的安装包上传到 /opt/software 下
-- 将hadoop安装到 /opt/module 下
-- 配置hadoop的环境变量
-- 在my_env.sh写入以下内容
#声明JAVA_HOME变量
JAVA_HOME=/opt/module/jdk1.8.0_212
#声明HADOOP_HOME变量
HADOOP_HOME=/opt/module/hadoop-3.1.3
#将JAVA_HOME变量追加到PATH变量上
#将HADOOP_HOME/bin 、HADOOP_HOME/sbin 追加到PATH变量上
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
#提升JAVA_HOME、PATH、HADOOP_HOME 变量为系统变量,
export JAVA_HOME PATH HADOOP_HOME
具体操作过程:
1.最小化安装一个虚拟机
这一步比较简单,按照下面步骤操作即可。
配置完成之后的一些系统简单配置
2.配置一台纯净版模板机
1)模板虚拟机必要环境
在终端运行下面命令,安装必要的环境。
[root@hadoop100 ~]# yum install -y epel-release [root@hadoop100 ~]# yum install -y psmisc nc net-tools rsync vim lrzsz ntp libzstd openssl-static tree iotop git
2)关闭防火墙,关闭防火墙开机自启。
[root@hadoop100 ~]# systemctl stop firewalld
[root@hadoop100 ~]# systemctl disable firewalld
3)创建普通用户,修改用户密码。
[root@hadoop100 ~]# useradd user1
[root@hadoop100 ~]# passwd 123456
4)给普通用户root权限,方便之后加sudo使用root的权限。
[root@hadoop100 ~]# vim /etc/sudoers
修改/etc/sudoers文件,找到下面一行(91行),在root下面添加一行,如下所示:
## Allow root to run any commands anywhere root ALL=(ALL) ALL user1 ALL=(ALL) NOPASSWD:ALL
5)在/opt目录下创建文件夹,并修改所属主和所著组。
(1)在/opt目录下创建module、software文件夹
[root@hadoop100 ~]# mkdir /opt/module
[root@hadoop100 ~]# mkdir /opt/software
(2)修改module、software文件夹的所有者和所属组均为atguigu用户
[root@hadoop100 ~]# chown user1:user1 /opt/module
[root@hadoop100 ~]# chown user1:user1 /opt/software
6)重启虚拟机
[root@hadoop100 ~]# reboot
3.用克隆的方式创建另一台机器
以下是克隆过程:
克隆新的系统后需要做两件事,一是修改主机名,二是修改IP地址。
(1)修改克隆虚拟机的静态IP
保证Linux系统ifcfg-ens33文件中IP地址、虚拟网络编辑器地址和Windows系统VM8网络IP地址相同。
[root@hadoop100 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
改成
DEVICE=ens33 TYPE=Ethernet ONBOOT=yes BOOTPROTO=static NAME="ens33" IPADDR=192.168.1.102 PREFIX=24 GATEWAY=192.168.1.2 DNS1=192.168.1.2
要保证Linux系统和Windows系统的IP地址相同,所以上面的192.168.1.102和192.168.1.2里面的1可能不是填1,这个要看自己Windows系统和虚拟机的地址填多少。
比如点击VMware上方的编辑,查看虚拟网络编辑器,
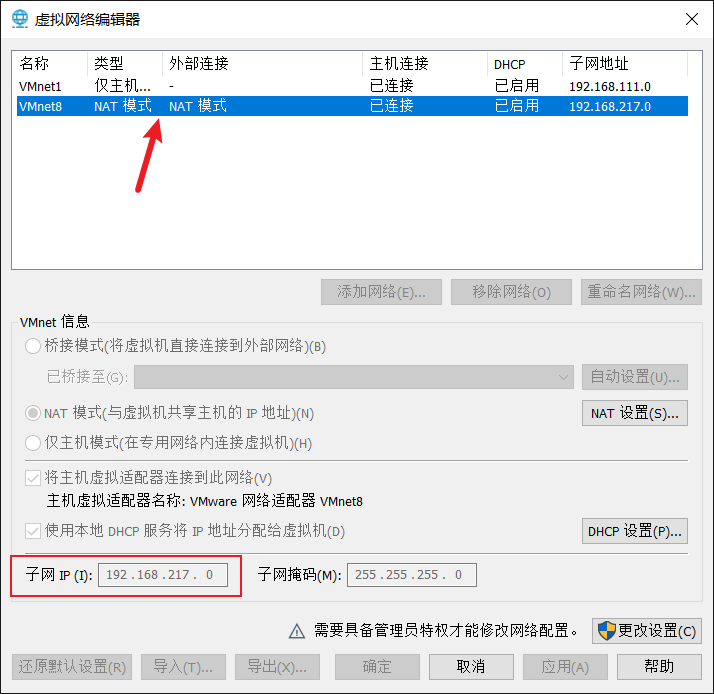
上面显示IP为192.168.217.0,所以在设置Linux系统IP的时候就需要设置192.168.217.102,最后这个数不固定。
(2)修改克隆虚拟机的主机名,映射文件。
修改主机名称
[root@hadoop100 ~]# vim /etc/hostname
hadoop2
配置linux克隆机主机名称映射hosts文件
[root@hadoop100 ~]# vim /etc/hosts
添加如下内容
192.168.1.100 hadoop2
之后重启
[root@hadoop100 ~]# reboot
修改Windows的映射文件
在C:\Windows\System32\drivers\etc\hosts
添加
192.168.1.100 hadoop2
4.安装JDK、Hadoop。
将jdk和hadoop的tar包导入到opt目录的software下,解压到opt目录的module下,这两个文件夹都是之前创建的。
[user1@hadoop2 software]$ tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
配置jdk的环境
(1)新建/etc/profile.d/my_env.sh文件
[user1@hadoop2 ~]$ sudo vim /etc/profile.d/my_env.sh
添加内容
#JAVA_HOME export JAVA_HOME=/opt/module/jdk1.8.0_212 export PATH=$PATH:$JAVA_HOME/bin
(2)保存后退出 :wq!
(3)source一下/etc/profile文件,让新的环境变量PATH生效
[user1@hadoop2 ~]$ source /etc/profile
同样解压hadoop
[user1@hadoop2 software]$ tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
配置hadoop的环境变量
sudo vim /etc/profile.d/my_env.sh
在末尾加下面内容
#HADOOP_HOME export HADOOP_HOME=/opt/module/hadoop-3.1.3 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin
(3)保存后退出
(4)让修改后的文件生效
[user1@hadoop2 hadoop-3.1.3]$ source /etc/profile
配置好了之后可以重启一下
[user1@hadoop2 hadoop-3.1.3]$ sudo reboot

 浙公网安备 33010602011771号
浙公网安备 33010602011771号