
python内置collections模块
collections模块
在内置数据类型(dict、list、set、tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter、deque、defaultdict、namedtuple和OrderedDict等。
1.namedtuple: 生成可以使用名字来访问元素内容的tuple
2.deque: 双端队列,可以快速的从另外一侧追加和推出对象
3.Counter: 计数器,主要用来计数
4.OrderedDict: 有序字典
5.defaultdict: 带有默认值的字典
namedtuple
我们知道tuple可以表示不变集合,例如,一个点的二维坐标就可以表示成:
p =(1,2)
但是,看到(1, 2),很难看出这个tuple是用来表示一个坐标的。
这时,namedtuple就派上了用场:
from collections import namedtuple
#namedtuple('名称', [属性list])
p = namedtuple("point",["x","y"])
p1 = p(1,2)
print(p)
print(p1)
print(p1.x)
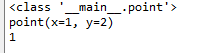
deque
使用list存储数据时,按索引访问元素很快,但是插入和删除元素就很慢了,因为list是线性存储,数据量大的时候,插入和删除效率很低。
from collections import deque
q = deque(['a', 'b', 'c'])
q.append('x')
q.appendleft('y')
OrderedDict
使用dict时,Key是无序的。在对dict做迭代时,我们无法确定Key的顺序。
如果要保持Key的顺序,可以用OrderedDict:
from collections import OrderedDict
d = dict([('a', 1), ('b', 2), ('c', 3)])
d # dict的Key是无序的
#{'a': 1, 'c': 3, 'b': 2}
od = OrderedDict([('a', 1), ('b', 2), ('c', 3)])
od # OrderedDict的Key是有序的
#OrderedDict([('a', 1), ('b', 2), ('c', 3)])
注意,OrderedDict的Key会按照插入的顺序排列,不是Key本身排序:
有如下值集合 [11,22,33,44,55,66,77,88,99,90...],将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中。
即: {'k1': 大于66 , 'k2': 小于66}
li = [11,22,33,44,55,77,88,99,90]
result = {}
for row in li:
if row > 66:
if 'key1' not in result:
result['key1'] = []
result['key1'].append(row)
else:
if 'key2' not in result:
result['key2'] = []
result['key2'].append(row)
print(result)
from collections import defaultdict
values = [11, 22, 33,44,55,66,77,88,99,90]
my_dict = defaultdict(list) #如果key不存在 则创建,并且默认值为空列表
#my_dict = defaultdict(tuple)
for value in values:
if value>66:
my_dict['k1'].append(value)
else:
my_dict['k2'].append(value)
from collections import defaultdict
dd = defaultdict(lambda: 'N/A')
dd['key1'] = 'abc'
dd['key1'] # key1存在
#'abc'
dd['key2'] # key2不存在,返回默认值
#'N/A'
Counter
Counter类的目的是用来跟踪值出现的次数。它是一个无序的容器类型,以字典的键值对形式存储,其中元素作为key,其计数作为value。计数值可以是任意的Interger(包括0和负数)。Counter类和其他语言的bags或multisets很相似。
c = Counter('abcdeabcdabcaba')
print c
#输出:Counter({'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1})

 浙公网安备 33010602011771号
浙公网安备 33010602011771号