
【课程学习】课程1:交通枢纽高密人流下的防疫筛查解决方案(1)
最近我在第三期百度黄埔学院支持下进行了一些学习,还是很有收获的,本文主要记录学习过程中的技术细节和想法。
课程1:交通枢纽高密人流下的防疫筛查解决方案,主讲人为百度视觉技术部:奉孝老师。
课程主要有以下四个方面的内容:
- AI多人体温度快速检测系统——人脸检测算法Pyramidbox
- 口罩检测分类模型
- 企业AI入场解决方案
- 基于深度学习的嵌入式人脸技术及行业应用
ps:本来是准备一篇文章都整理完的,写着写着发现篇幅太长了。。。只好分成几部分
本文介绍第一部分:AI多人体体温快速检测模型,包括Pyramidbox和模型压缩技术。
AI多人体体温快速检测模型
2020年,新型冠状病毒爆发,为控制病情,重点场所和公共交通的测体温和口罩检测成为了刚需。但在高密度的人流下,基层排查人员面临着几个问题:(1)人手不够,测温效率低;(2)长期暴露在人群中,受感染风险大。
为解决上述问题,百度的视觉技术相关部门在短短的一个月内完成了测温、口罩检测、身份识别等的技术开发和产品落地,相关方案在北京高铁清河站、北京地铁、百度科技园等场所应用,辅助一线人员进行防疫工作。
检测方案需要满足测量连续性、准确性、快速性和异常报警等需求。百度给出的解决方案是在固定点位设置红外摄像机采集人群的面部和温度,然后采取基于深度学习的嵌入式的AI人脸检测技术,并整合了红外热成像技术,形成了完善的人群快速测温方案。
系统由四部分组成:前端采集、边缘计算、深度学习算法和可视化展示。其中比较核心的是边缘计算设备的开发和深度学习算法。深度学习算法里提到了比较重要的指标:召回率>99%,耗时<10ms,模型的体积只有kb级。在有限的算力设备和如此小的模型下,能取得这种效果还是很厉害的。下面介绍一下涉及到的技术。

(1)从算法训练到应用落地
研究中的算法开发和应用落地的算法开发是不同的,研究型的算法开发在强大算力的支持下追求最佳的检测效果,但在应用落地时要综合考虑算法性能和硬件成本等因素。边缘设备的算力比较差,在有限算力的限制下将模型小型化,同时保证算法的性能十分关键。这就涉及到模型选择、模型压缩和模型推理三个内容。
(2)Pyramidbox算法
方案使用的框架是百度自己的PaddlePaddle(飞桨),采用PaddleCV用于模型训练,用PaddleCV有一个好处是它里面有比较优质的预训练模型,同时集成了常用的图像分类、目标检测、图像分割等算法,比如目标检测的SSD、Faster-RCNN和YOLOV3等等。口罩检测用的是百度的Pyramidbox。
PaddleCV:https://github.com/PaddlePaddle/models/tree/v1.5.1/PaddleCV

PyramidBox是WIDER FACE人脸检测的三料冠军,先看一下它的效果吧。

图中的1000张人脸被识别出890张,可以看出PyramidBox对比较小的、或者部分遮挡的人脸均有比较好的识别效果。
PyramidBox是基于anchor的目标检测网络,主架构采用了与S3FD相同的extended VGG16。
Low-level Feature Pyramid Layers(LFPN)
FPN中提出多尺度特征融合的方式强化特征重用,提高特征图的映射,PyramidBox借鉴了这种思想,提出了low-level的FPN(LFPN)。
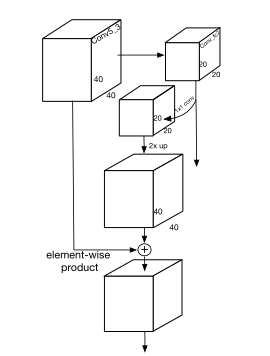
FPN的特征融合是从最顶层开始的,PyramidBox的作者认为最顶层的特征图感受野太大了,对于检测较小面孔没什么益处,反而可能会引入噪声。LFPN选择从从中间层开始构建自顶向下的结构,其感受野差不多是输入图像尺寸的一半。我们从源码中也能看出来,自顶向下的融合是从conv6(论文里是fc6和fc7转换为conv fc层)开始的,没有从conv7(论文里是conv6_1和conv6_2)和conv8(论文里是conv7_1和conv7_2)这两个最顶层开始。
def _low_level_fpn(self):
"""
Low-level feature pyramid network.
"""
def fpn(up_from, up_to):
ch = up_to.shape[1]
b_attr = ParamAttr(learning_rate=2., regularizer=L2Decay(0.))
conv1 = fluid.layers.conv2d(
up_from, ch, 1, act='relu', bias_attr=b_attr)
if self.use_transposed_conv2d:
w_attr = ParamAttr(
learning_rate=0.,
regularizer=L2Decay(0.),
initializer=Bilinear())
upsampling = fluid.layers.conv2d_transpose(
conv1,
ch,
output_size=None,
filter_size=4,
padding=1,
stride=2,
groups=ch,
param_attr=w_attr,
bias_attr=False,
use_cudnn=False)
else:
upsampling = fluid.layers.resize_bilinear(
conv1, out_shape=up_to.shape[2:])
conv2 = fluid.layers.conv2d(
up_to, ch, 1, act='relu', bias_attr=b_attr)
if self.is_infer:
upsampling = fluid.layers.crop(upsampling, shape=conv2)
# eltwise mul
conv_fuse = upsampling * conv2
return conv_fuse
self.lfpn2_on_conv5 = fpn(self.conv6, self.conv5)
self.lfpn1_on_conv4 = fpn(self.lfpn2_on_conv5, self.conv4)
self.lfpn0_on_conv3 = fpn(self.lfpn1_on_conv4, self.conv3)
与FPN相似,PyramidBox也将检测分布到多个尺度的特征图上,文章中提到选择lfpn_2、lfpn_1、lfpn_0、conv_fc7、conv6_2、conv7_2作为检测层,anchor的尺寸分别为16、32、64、128、256、512。其中lfpn_2、lfpn_1、lfpn_0分别是基于conv3、conv4_3、conv5_3的lfpn的输出层。
检测层后直接接上CPM,CPM的输出用于监督Pyramid anchor。论文中提到了通道数\(c_l=20\)
Context-sensitive Predict Module (CPM)
PyramidBox的第二创新点是将语境信息融入到了人脸识别中。毕竟一般人脸是不会单独出现的,身体和肩部的信息可以为人脸识别中提供语境层面的特征,这在检测被遮挡或部分缺失的人脸时能起到很好的辅助效果。比如下图中的这几个检测案例,人脸信息都不是很明显的,但是检测效果很好。

一开始看论文的时候有点懵,考虑到PyramidBox中设计的Context-sensitive Predict Module (CPM)是将SSH和DSSD两个模型的优势攒到一起,我又看了看SSH才大概搞懂(也可能理解错了)。
SSH是在三个不同深度的卷积层引入了不同的预测模块,从而检测不同大小的人脸。检测模块M1这一分枝将conv4-3 和conv5-3 的特征进行了融合,来检测最小尺寸人脸。M2则是是直接在conv5-3卷积层之后做检测,检测到稍大一些的人脸。M1与M2相比多了一个池化层,通过Max-pooling操作来增加感受野,使其能检测到比M2更大的人脸。
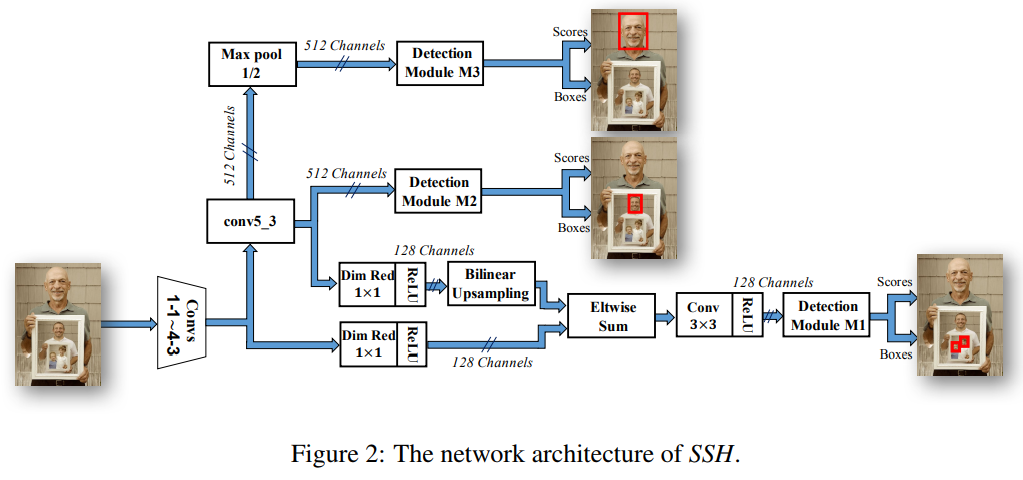
CPM吸收了这种思想,不过作者认为增加宽度和深度都会提升检测效果,因此用DSSD中的残差模块代替了SSH中的卷积模块

源码中也能看出,CPM是由这两部分组成。
def _cpm_module(self):
"""
Context-sensitive Prediction Module
"""
def cpm(input):
# residual
branch1 = conv_bn(input, 1024, 1, 1, 0, None)
branch2a = conv_bn(input, 256, 1, 1, 0, act='relu')
branch2b = conv_bn(branch2a, 256, 3, 1, 1, act='relu')
branch2c = conv_bn(branch2b, 1024, 1, 1, 0, None)
sum = branch1 + branch2c
rescomb = fluid.layers.relu(x=sum)
# ssh
b_attr = ParamAttr(learning_rate=2., regularizer=L2Decay(0.))
ssh_1 = fluid.layers.conv2d(rescomb, 256, 3, 1, 1, bias_attr=b_attr)
ssh_dimred = fluid.layers.conv2d(
rescomb, 128, 3, 1, 1, act='relu', bias_attr=b_attr)
ssh_2 = fluid.layers.conv2d(
ssh_dimred, 128, 3, 1, 1, bias_attr=b_attr)
ssh_3a = fluid.layers.conv2d(
ssh_dimred, 128, 3, 1, 1, act='relu', bias_attr=b_attr)
ssh_3b = fluid.layers.conv2d(ssh_3a, 128, 3, 1, 1, bias_attr=b_attr)
ssh_concat = fluid.layers.concat([ssh_1, ssh_2, ssh_3b], axis=1)
ssh_out = fluid.layers.relu(x=ssh_concat)
return ssh_out
self.ssh_conv3 = cpm(self.lfpn0_on_conv3)
self.ssh_conv4 = cpm(self.lfpn1_on_conv4)
self.ssh_conv5 = cpm(self.lfpn2_on_conv5)
self.ssh_conv6 = cpm(self.conv6)
self.ssh_conv7 = cpm(self.conv7)
self.ssh_conv8 = cpm(self.conv8)
PyramidAnchors
这一部分我看了好长时间,还是有点懵,不确定我的理解是不是准确,期待有百度的小伙伴能来补充。
基于anchor的检测器都是直接奔着目标物去的,作者认为这种方式忽略了上下文信息。作者提出了一种PyramidAnchors的anchor方法。 PyramidAnchors生成的anchor不仅与脸部信息相关,还包含了脸部以外的相关信息,比如头和身体。在实施中,对应每个目标人脸都生成与之相关的包含语境信息的anchor,设置方式是让目标人脸的大小和anchor的大小相匹配。
先举个例子再分析细节吧。
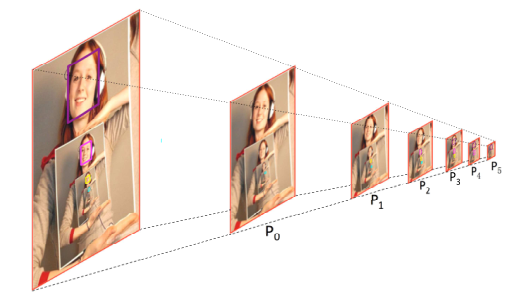
论文中提到,当检测最大的这张脸时(紫色框),利用的是P3、P4和P5三个尺度上的anchor,其中P3用来检测脸,P4用来检测与脸相关的头部,P5用来检测与脸相关的身体,分别对应了CPM中的三个输出,这三个输出特征图的大小是不一样的。
PyramidAnchors使用anchor进行预测,首先要给不同的anchor打上label,假设\(anchor_{i,j}\)是第\(i\)个特征图上的第\(j\)个anchor,定义其\(k\)阶pyramid-anchor的label为:
\(label_k(anchor_{i,j})=\left\{\begin{matrix}1
&if\ iou(anchor_{i,j}·s_i/s_{pa}^{\ k},\ region_{target})>threshold\\ 0
&otherwise
\end{matrix}\right.\)
这个公式的意思是要定义K个label(文中K=2,\(label_1\)、\(label_2\)和\(lable_3\)分别对应人脸、头部和身体的label),也就是说用于预测人类的PyramidAnchors的层数是三层。至于label的值是1还是0,取决于\((anchor_{i,j}·s_i/s_{pa}^{\ k}\)和目标区域\(region_{target}\)的iou值。\(s_i\)表示特征图的stride size,\((anchor_{i,j}·s_i\)是该\(anchor\)对应原图中的区域,\((anchor_{i,j}·s_i/s_{pa}^{\ k}\)指的是以步长\(s_{pa}^{\ k}\)下采样后的区域,试验表明K=2、\(s_{pa}=2\)的情况效果最好。

Data-anchor-sampling
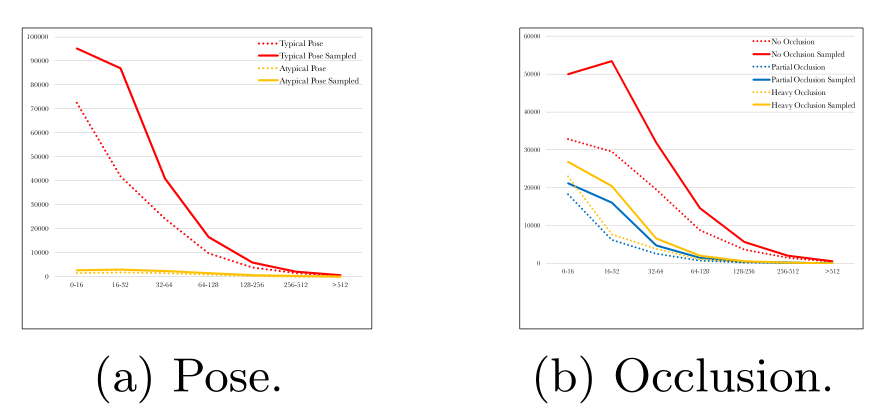
Data-anchor-sampling作为一种扩增数据的方式,通过将图像中较大的人脸缩放至小人脸,增加训练样本在不同尺度上的多样性。
可以看到,WIDER FACE训练集中的四种类型数据:a 姿态(典型和非典型) 、b 遮挡情况(无遮挡、部分遮挡、严重遮挡)、c 模糊度(清晰、一般、模糊)和d 曝光度(正常、过曝),小尺寸的人脸都变多了不少。
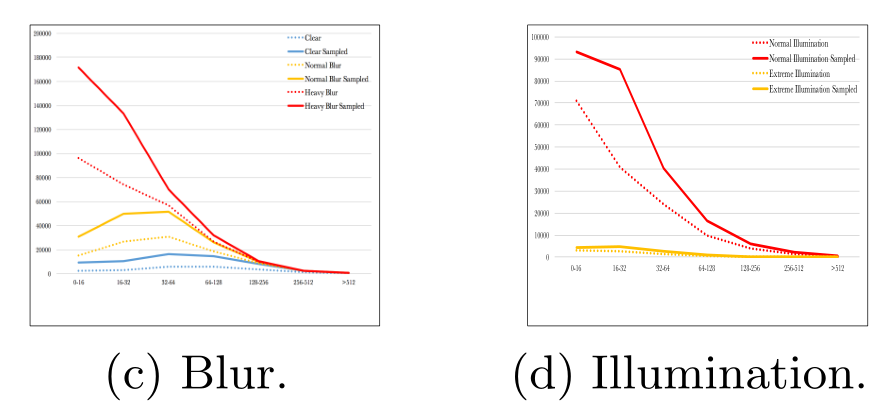
操作方式论文中举了个例子,很好懂,我就不多解释了。

以上,就是Pyramidbox算法的内容
(3)模型小型化
算法研究追求的是在算力充足的条件下达到state-of-art的算法效果,但是在项目落地时,还需要综合考虑效果、速度和成本等要素。
模型压缩有可能造成精度损失,如何在可接受的损失范围内下实现模型小型化是算法在嵌入式场景落地的关键。
该团队使用的模型压缩工具是PaddleSlim。模型地址:https://github.com/PaddlePaddle/PaddleSlim
课程中提到PaddleSlim的几个优势:
1、包含蒸馏、剪裁、量化、模型结构搜索等模型小型化技术,能够实现超过70%的体积压缩。
2、自动化网络结构搜索代替人工迭代网络,实现5倍于传统方法的软硬适配速度
3、人脸检测算法通过模型蒸馏、网络结构搜索、剪枝和量化实现10倍以上的加速,模型大小达到kb级。
我不太了解模型压缩这一块的内容,就把它能达到的效果给大家展示一下。
模型蒸馏:模型蒸馏将复杂网络中的有用信息提取出来,迁移到一个更小的网络中去,从而达到节省计算资源的目的。PaddleSlim中的蒸馏对于分类、检测任务都有几个点的提升。

模型裁剪:PaddleSlim使用的是基于敏感度的模型裁剪,支持模型敏感度的多机、多线程加速计算。令我比较惊讶的是剪枝之后的模型精度不降反升,同时模型体积大大减小。

模型量化:定点量化的目的是将神经网络前向过程中浮点数运算(float32)量化为整数(int8)运算,以达到计算加速的目的,毕竟浮点数的计算会消耗比较大的计算资源。对于大多数处理器来说,整型运算的速度是浮点要快很多的,目前不管是移动端还是服务器端,新的计算设备正不断迎合量化技术,支持int8计算是一个趋势。

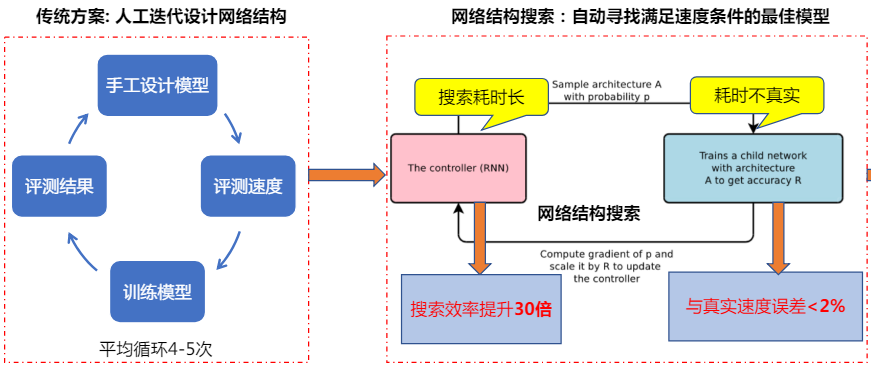
网络结构搜索:网络结构搜索的目的是用机器设计网络结构代替手工设计。目前的搜索策略有基于强化学习的、基于进化算法的和基于梯度的。百度的PaddleSlim采取的策略之前是基于退火等进化算法的,后来又新增了基于超网络的One-shot网络结构搜索方法(说实话我也不懂。。。),效果杠杠的:将搜索效率提升了30倍,与真实速度误差<2%。
|
作者:李是李雅普诺夫的李 出处:http://www.cnblogs.com/lky-learning/ 如需交流或转载,请联系本人,欢迎关注公众号:一刻AI 如果文中有什么错误,欢迎指出。以免更多的人被误导。 |

|

 浙公网安备 33010602011771号
浙公网安备 33010602011771号