第六次作业
作业①
1)、用requests和BeautifulSoup库方法爬取豆瓣电影Top250数据实验
主函数:
import os
import urllib
import urllib.request
import re
from bs4 import UnicodeDammit, BeautifulSoup
import prettytable as pt
import threading
x = pt.PrettyTable() # 制表
x.field_names = ["排名", "电影名称", "导演", "主演", "上映时间", "国家", "电影类型", "评分", "评价人数", "引用", "文件路径"] # 设置表头
class MySpider:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3775.400 QQBrowser/10.6.4209.400"}
def start(self):
self.no = 0
def getHTMLText(self, url, k):
try:
if (k == 0):
url = url
else:
url = "https://movie.douban.com/top250?start=" + str(k) + "&filter="
req = urllib.request.Request(url, headers=MySpider.headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, 'html.parser')
return soup
except Exception as err:
print(err)
def getData(self, soup):
movieList = soup.find('ol', attrs={'class': 'grid_view'}) # 找到第一个class属性值为grid_view的ol标签
for movieLi in movieList.find_all('li'): # 找到所有li标签
data = []
self.no += 1
data.append(self.no)
# 得到电影名字
movieHd = movieLi.find('div', attrs={'class': 'hd'}) # 找到第一个class属性值为hd的div标签
movieName = movieHd.find('span', attrs={'class': 'title'}).getText() # 找到第一个class属性值为title的span标签
# 得到电影的导演和主演的名称(导演过多会导致主演名未显示)
bd = movieLi.find('div', attrs={'class': 'bd'})
msg = bd.find('p').text.strip('').split('\n')
if '\xa0\xa0\xa0' in msg[1]:
actors_director = msg[1].strip('').split('\xa0\xa0\xa0')
director = actors_director[0].strip(' ')[3:]
actor = actors_director[1].strip('.')[3:]
else:
actors_director = msg[1].strip('').split('\xa0\xa0\xa0')
director = actors_director[0].strip(' ')[3:]
actor = ''
# 得到上映时间,国家与种类
msg1 = msg[2].strip('').split('\xa0/\xa0')
year = msg1[0].strip(' ')
nation = msg1[1]
category = msg1[2]
# 得到电影的评分
movieScore = movieLi.find('span', attrs={'class': 'rating_num'}).getText()
# 得到电影的评价人数
movieEval = movieLi.find('div', attrs={'class': 'star'})
movieEvalNum = re.findall(r'\d+', str(movieEval))[-1]
# 得到引用(没有引用则为空)
try:
quote = movieLi.find('span', attrs={'class': 'inq'}).getText()
except Exception:
quote = " "
# 得到文件路径
pic_url = movieLi.find('div', attrs={'class': 'pic'}).select("img")[0]["src"]
if (pic_url[len(pic_url) - 4] == "."):
ext = pic_url[len(pic_url) - 4:]
else:
ext = ""
x.add_row([self.no,movieName,director,actor,year,nation,category,movieScore,movieEvalNum,quote,movieName+ext])
T = threading.Thread(target=self.download, args=(pic_url, movieName))
T.setDaemon(False)
T.start()
def download(self, url, movieName):
if (url[len(url) - 4] == "."):
ext = url[len(url) - 4:]
else:
ext = ""
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
fobj = open("./6.1_picture/" + movieName + ext, "wb")
fobj.write(data)
fobj.close()
url = "https://movie.douban.com/top250"
k = 0
spider = MySpider()
spider.start()
# 创建图片存储文件夹
if not os.path.exists("./6.1_picture"):
os.mkdir('./6.1_picture')
while k <= 225:
html = spider.getHTMLText(url, k)
k += 25
spider.getData(html)
print(x)


2)、心得体会:
感觉这个作业是这次作业中最难的一题,这几周用Selenium用习惯了,现在反而不怎么会用requests和BeautifulSoup库方法。这次作业遇到的困难主要集中在导演和主演那里,导演、演员、电影类型、年份、国家这几种数据都在同一个‘p’标签下,而且有的中国电影的格式还跟其他电影的格式不一样,试了很多方法最后还是成功爬出来了,但是还是有一点瑕疵。其他地方没有遇到什么问题,相对来说比较容易。
作业②
1)、用Scrapy+Xpath+MySQL数据库存储技术路线爬取科软排名信息实验
主函数:
import os
import urllib
import scrapy
from ..items import SchoolItem
from bs4 import UnicodeDammit
class MySpider(scrapy.Spider):
name = "mySpider"
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
url = "https://www.shanghairanking.cn/rankings/bcur/2020"
def start_requests(self):
url = MySpider.url
self.no = 1
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
try:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
lis = selector.xpath("//td[@class='align-left']")
for li in lis:
suffix = li.xpath("./a[position()=1]/@href").extract_first() # 单个学校网站后缀
school_url = "https://www.shanghairanking.cn/"+suffix
req = urllib.request.Request(school_url, headers=MySpider.headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
msg = scrapy.Selector(text=data)
rank = msg.xpath("//div[@class='rank-table-rank']/a/text()").extract_first()
print(rank)
name = msg.xpath("//div[@class='univ-name']/text()").extract_first()
city = li.xpath("//td[position()=3]/text()").extract_first()
officalUrl = msg.xpath("//div[@class='univ-website']/a/text()").extract_first()
info = msg.xpath("//div[@class='univ-introduce']/p/text()").extract_first()
pic_url = msg.xpath("//td[@class='univ-logo']/img/@src").extract_first()
mfile = str(self.no) + ".jpg"
self.download(pic_url)
self.no += 1
item = SchoolItem()
item["rank"] = rank.strip() if rank else ""
item["name"] = name.strip() if name else ""
item["city"] = city.strip() if city else ""
item["officalUrl"] = officalUrl.strip() if officalUrl else ""
item["info"] = info.strip() if info else ""
item["mfile"] = mfile.strip() if mfile else ""
yield item
link = selector.xpath("//div[@class='paging']/ul[@name='Fy']/li[@class='next']/a/@href").extract_first()
if link:
url = response.urljoin(link)
yield scrapy.Request(url=url, callback=self.parse)
except Exception as err:
print(err)
def download(self, url):
if (url[len(url) - 4] == "."):
ext = url[len(url) - 4:]
else:
ext = ""
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
fobj = open("./6.2_picture/"+ str(self.no) + ext, "wb")
fobj.write(data)
fobj.close()pipelines.py:
import os
import pymysql
class SpiderPipeline:
def open_spider(self, spider):
if not os.path.exists("./6.2_picture"):
os.mkdir('./6.2_picture')
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="123456", db="mydb",
charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("DROP TABLE IF EXISTS school")
# 创建表
self.cursor.execute("CREATE TABLE IF NOT EXISTS school(sNo INT PRIMARY KEY,"
"schoolName VARCHAR(32),"
"city VARCHAR(32),"
"officalUrl VARCHAR(256),"
"info VARCHAR(512),"
"mfile VARCHAR(32))")
self.opened = True
self.count = 0
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
def process_item(self, item, spider):
try:
if self.opened:
self.cursor.execute(
"insert into school (sNo,schoolName,city,officalUrl,info,mfile) values( % s, % s, % s, % s, % s, % s)",
(item["rank"], item["name"], item["city"], item["officalUrl"], item["info"], item["mfile"]))
except Exception as err:
print(err)
return ite
setting:
ITEM_PIPELINES = {
'spider.pipelines.SpiderPipeline': 300,
}items.py:
import scrapy
class SchoolItem(scrapy.Item):
rank = scrapy.Field()
name = scrapy.Field()
city = scrapy.Field()
officalUrl = scrapy.Field()
info = scrapy.Field()
mfile = scrapy.Field()run.py:
from scrapy import cmdline
cmdline.execute("scrapy crawl mySpider -s LOG_ENABLED=False".split())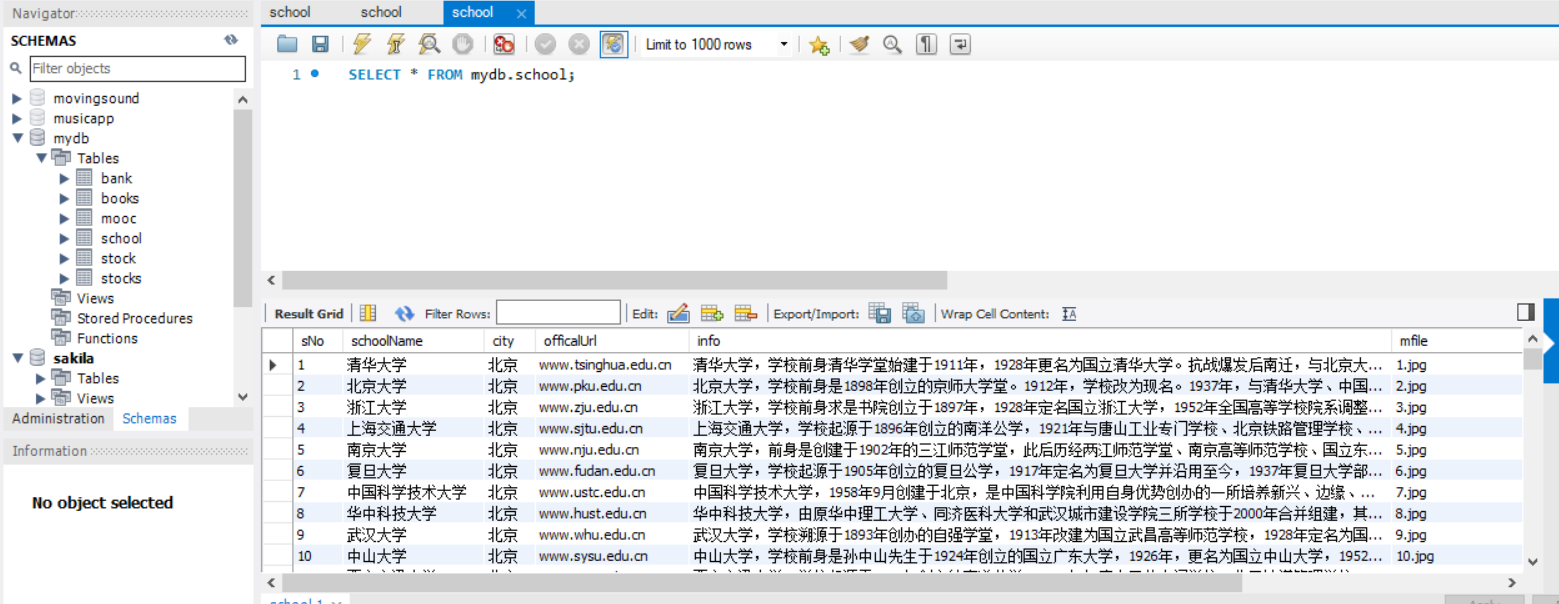

2)、心得体会:
虽然我觉得我的代码还有很多可以优化的地方,但这次实验总体上还是挺顺利的,题目所需的信息一种一种找,中途都没有出现问题,最后下载学校Logo存储直接套用之前实验做的代码。感觉这次实验没什么好说的,按照以前的模板老老实实找就找到了,不过还是让我回忆了很多之前的知识。
作业③
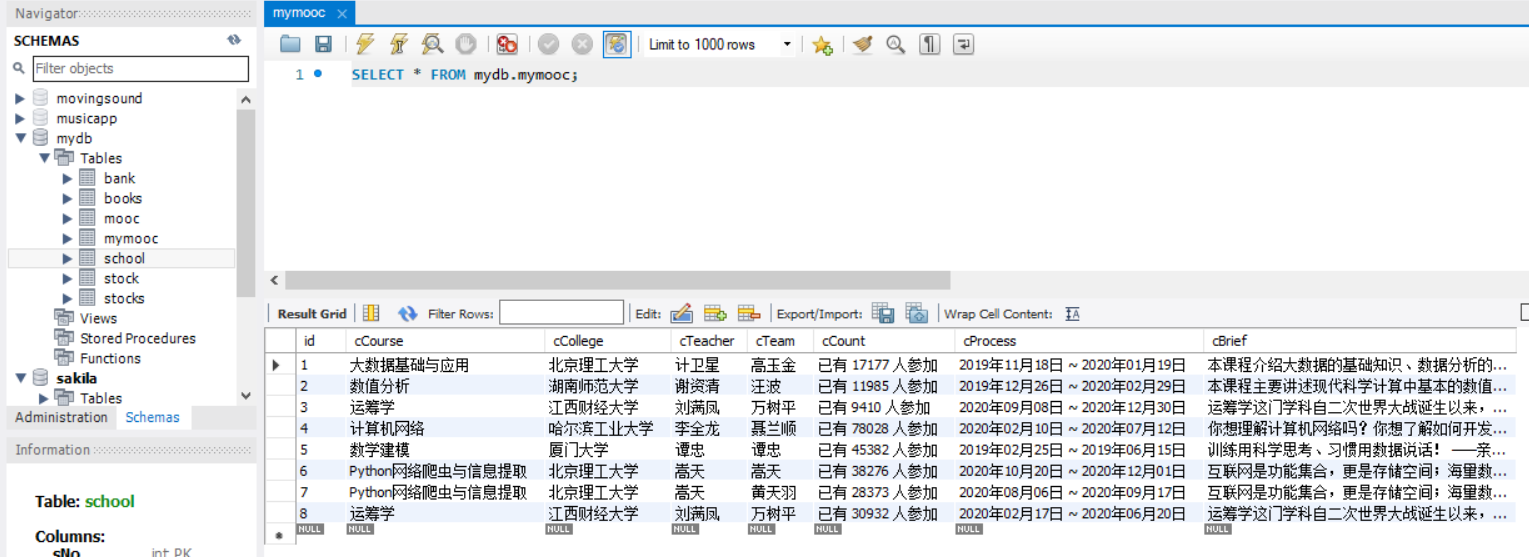
1)、用Selenium框架+ MySQL数据库存储技术模拟登录慕课网,并获取学生自己账户中已学课程的信息并保存在MYSQL中实验
主函数:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import pymysql
import time
class MySpider:
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
def startUp(self, url):
chrome_options = Options()
self.driver = webdriver.Chrome(options=chrome_options)
self.driver.maximize_window() # 最大化浏览器
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="123456", db="mydb",
charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("DROP TABLE IF EXISTS mymooc")
# 创建表
self.cursor.execute("CREATE TABLE IF NOT EXISTS mymooc(id INT PRIMARY KEY,"
"cCourse VARCHAR(256),"
"cCollege VARCHAR(256),"
"cTeacher VARCHAR(256),"
"cTeam VARCHAR(256),"
"cCount VARCHAR(256),"
"cProcess VARCHAR(256),"
"cBrief VARCHAR(256))")
self.opened = True
self.No = 0
except Exception as err:
print(err)
self.opened = False
self.driver.get(url)
def enter(self): # 手机登录
try:
self.driver.find_element_by_xpath("//div[@class='_3uWA6']").click()
self.driver.find_element_by_xpath("//span[@class='ux-login-set-scan-code_ft_back']").click()
self.driver.find_elements_by_xpath("//ul[@class='ux-tabs-underline_hd']//li")[1].click()
iframe_id = self.driver.find_elements_by_tag_name("iframe")[1].get_attribute('id')
self.driver.switch_to.frame(iframe_id)
self.driver.find_element_by_xpath("//input[@id='phoneipt']").send_keys("15260736737")
time.sleep(0.5)
self.driver.find_element_by_xpath("//input[@class='j-inputtext dlemail']").send_keys("lkx1013476640")
time.sleep(0.5)
self.driver.find_element_by_xpath("//a[@class='u-loginbtn btncolor tabfocus ']").click()
time.sleep(3)
self.driver.find_element_by_xpath("//div[@class='_3uWA6']").click()
self.driver.get(self.driver.current_url)
except Exception as err:
print(err)
def closeUp(self):
try:
self.con.commit()
self.con.close()
self.driver.close()
except Exception as err:
print(err);
def insertDB(self, cNo, cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief):
try:
self.cursor.execute(
"insert into mymooc( id, cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief) values(%s,%s,%s,%s,%s,%s,%s,%s)",
(cNo, cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief))
except Exception as err:
print(err)
def processSpider(self):
try:
lis = self.driver.find_elements_by_xpath("//div[@class='course-panel-body-wrapper']//div[@class='course-card-wrapper']")
for li in lis:
li.find_element_by_xpath(".//div[@class='img']").click()
last_window = self.driver.window_handles[-1]
self.driver.switch_to.window(last_window)
time.sleep(2)
self.driver.find_element_by_xpath(".//a[@class='f-fl']").click()
last_window = self.driver.window_handles[-1]
self.driver.switch_to.window(last_window)
try:
cCource = self.driver.find_element_by_xpath("//span[@class='course-title f-ib f-vam']").text
cCollege = self.driver.find_element_by_xpath("//img[@class='u-img']").get_attribute("alt")
cTeacher = self.driver.find_element_by_xpath(
"//div[@class='um-list-slider_con']/div[position()=1]//h3[@class='f-fc3']").text
z = 0
while (True):
try:
cTeam = self.driver.find_elements_by_xpath(
"//div[@class='um-list-slider_con_item']//h3[@class='f-fc3']")[z].text
z += 1
except:
break
cCount = self.driver.find_element_by_xpath(
"//span[@class='course-enroll-info_course-enroll_price-enroll_enroll-count']").text
cProcess = self.driver.find_element_by_xpath(
"//div[@class='course-enroll-info_course-info_term-info_term-time']//span[position()=2]").text
cBrief = self.driver.find_element_by_xpath("//div[@id='j-rectxt2']").text
except Exception as err:
print(err)
self.driver.close()
old_window1 = self.driver.window_handles[-1]
self.driver.switch_to.window(old_window1)
self.driver.close()
old_window2 = self.driver.window_handles[0]
self.driver.switch_to.window(old_window2)
self.No = self.No + 1
no = str(self.No)
while len(no) < 3:
no = "0" + no
self.insertDB(no, cCource, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief)
except Exception as err:
print(err)
def executeSpider(self, url):
print("Spider starting......")
self.startUp(url)
print("Spider processing......")
self.enter()
self.processSpider()
print("Spider closing......")
self.closeUp()
spider = MySpider()
url = "https://www.icourse163.org/"
spider = MySpider()
spider.executeSpider(url)
2)、心得体会:
解题思路:登录后进入“我的课程”,对已学课程逐一点击进入该课程,再点击左上角的课程名进入课程详情界面,剩下的就是上次实验的爬取内容了。
这次实验我觉得重点是在登录以及打开两个网页后的窗口转换这两个方面,解决了这两个问题,剩下的爬取信息就跟上次试验一模一样了。
