第五次作业
作业①
1)、使用Selenium框架爬取京东商城手机商品信息及图片实验
主函数:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import urllib.request
import threading
import sqlite3
import os
import datetime
from selenium.webdriver.common.keys import Keys
import time
class MySpider:
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
imagePath = "download"
def startUp(self, url, key):
# # Initializing Chrome browser
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
self.driver = webdriver.Chrome(chrome_options=chrome_options)
# Initializing variables
self.threads = []
self.No = 0
self.imgNo = 0
# Initializing database
try:
self.con = sqlite3.connect("phones.db")
self.cursor = self.con.cursor()
try:
# 如果有表就删除
self.cursor.execute("drop table phones")
except:
pass
try:
# 建立新的表
sql = "create table phones (mNo varchar(32) primary key, mMark varchar(256),mPrice varchar(32),mNote varchar(1024),mFile varchar(256))"
self.cursor.execute(sql)
except:
pass
except Exception as err:
print(err)
# Initializing images folder
try:
if not os.path.exists(MySpider.imagePath):
os.mkdir(MySpider.imagePath)
images = os.listdir(MySpider.imagePath)
for img in images:
s = os.path.join(MySpider.imagePath, img)
os.remove(s)
except Exception as err:
print(err)
self.driver.get(url)
keyInput = self.driver.find_element_by_id("key")
keyInput.send_keys(key)
keyInput.send_keys(Keys.ENTER)
def closeUp(self):
try:
self.con.commit()
self.con.close()
self.driver.close()
except Exception as err:
print(err);
def insertDB(self, mNo, mMark, mPrice, mNote, mFile):
try:
sql = "insert into phones (mNo,mMark,mPrice,mNote,mFile) values (?,?,?,?,?)"
self.cursor.execute(sql, (mNo, mMark, mPrice, mNote, mFile))
except Exception as err:
print(err)
def showDB(self):
try:
con = sqlite3.connect("phones.db")
cursor =con.cursor()
print("%-8s%-16s%-8s%-16s%s"%("No", "Mark", "Price", "Image", "Note"))
cursor.execute("select mNo,mMark,mPrice,mFile,mNote from phones order by mNo")
rows = cursor.fetchall()
for row in rows:
print("%-8s %-16s %-8s %-16s %s" % (row[0], row[1], row[2], row[3],row[4]))
con.close()
except Exception as err:
print(err)
def download(self, src1, src2, mFile):
data = None
if src1:
try:
req = urllib.request.Request(src1, headers=MySpider.headers)
resp = urllib.request.urlopen(req, timeout=10)
data = resp.read()
except:
pass
if not data and src2:
try:
req = urllib.request.Request(src2, headers=MySpider.headers)
resp = urllib.request.urlopen(req, timeout=10)
data = resp.read()
except:
pass
if data:
print("download begin", mFile)
fobj = open(MySpider.imagePath + "\\" + mFile, "wb")
fobj.write(data)
fobj.close()
print("download finish", mFile)
def processSpider(self):
try:
time.sleep(1)
print(self.driver.current_url)
lis =self.driver.find_elements_by_xpath("//div[@id='J_goodsList']//li[@class='gl-item']")
for li in lis:
# We find that the image is either in src or in data-lazy-img attribute
try:
src1 = li.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("src")
except:
src1 = ""
try:
src2 = li.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("data-lazy-img")
except:
src2 = ""
try:
price = li.find_element_by_xpath(".//div[@class='p-price']//i").text
except:
price = "0"
try:
note = li.find_element_by_xpath(".//div[@class='p-name p-name-type-2']//em").text
mark = note.split(" ")[0]
mark = mark.replace("爱心东东\n", "")
mark = mark.replace(",", "")
note = note.replace("爱心东东\n", "")
note = note.replace(",", "")
except:
note = ""
mark = ""
self.No = self.No + 1
no = str(self.No)
while len(no) < 6:
no = "0" + no
print(no, mark, price)
if src1:
src1 = urllib.request.urljoin(self.driver.current_url, src1)
p = src1.rfind(".")
mFile = no + src1[p:]
elif src2:
src2 = urllib.request.urljoin(self.driver.current_url, src2)
p = src2.rfind(".")
mFile = no + src2[p:]
if src1 or src2:
T = threading.Thread(target=self.download, args=(src1, src2, mFile))
T.setDaemon(False)
T.start()
self.threads.append(T)
else:
mFile = ""
self.insertDB(no, mark, price, note, mFile)
# 取下一页的数据,直到最后一页
try:
self.driver.find_element_by_xpath("//span[@class='p-num']//a[@class='pn-next disabled']")
except:
nextPage = self.driver.find_element_by_xpath("//span[@class='p-num']//a[@class='pn-next']")
time.sleep(10)
nextPage.click()
self.processSpider()
except Exception as err:
print(err)
def executeSpider(self, url, key):
starttime = datetime.datetime.now()
print("Spider starting......")
self.startUp(url, key)
print("Spider processing......")
self.processSpider()
print("Spider closing......")
self.closeUp()
for t in self.threads:
t.join()
print("Spider completed......")
endtime = datetime.datetime.now()
elapsed = (endtime - starttime).seconds
print("Total ", elapsed, " seconds elapsed")
url = "http://www.jd.com"
spider = MySpider()
while True:
print("1.爬取")
print("2.显示")
print("3.退出")
s = input("请选择(1,2,3):")
if s == "1":
spider.executeSpider(url, "手机")
continue
elif s == "2":
spider.showDB()
continue
elif s == "3":
break

2)、心得体会:
虽然代码都是照着书打的,但是有点长,花了挺多时间进行理解。这次实验主要学习了翻页操作,感觉爬取的过程越来越丰富有趣了。
作业②
1)、使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息实验
主函数:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import pymysql
import datetime
import time
class MySpider:
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
def start(self, url):
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
self.driver = webdriver.Chrome(options=chrome_options)
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="123456", db="mydb",
charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("DROP TABLE IF EXISTS stock")
# 创建表
self.cursor.execute("CREATE TABLE IF NOT EXISTS stock(Sid INT PRIMARY KEY,"
"Ssymbol VARCHAR(32),"
"Sname VARCHAR(32),"
"Soffer VARCHAR(32),"
"SchangeRate VARCHAR(32),"
"SchangePrice VARCHAR(32),"
"Svolume VARCHAR(32),"
"Sturnover VARCHAR(32),"
"Samplitude VARCHAR(32),"
"Shighest VARCHAR(32),"
"Slowest VARCHAR(32),"
"Stoday VARCHAR(32),"
"Syesterday VARCHAR(32))")
self.opened = True
self.No = 0
except Exception as err:
print(err)
self.opened = False
self.driver.get(url)
def close(self):
try:
self.con.commit()
self.con.close()
self.driver.close()
except Exception as err:
print(err);
def insertDB(self, Ssymbol, Sname, Soffer, SchangeRate, SchangePrice, Svolume, Sturnover, Samplitude, Shighest,
Slowest, Stoday, Syesterday):
try:
print(self.No, Ssymbol, Sname, Soffer, SchangeRate, SchangePrice, Svolume, Sturnover, Samplitude, Shighest,
Slowest, Stoday, Syesterday)
self.cursor.execute(
"insert into stock(Sid,Ssymbol,Sname,Soffer,SchangeRate,SchangePrice,Svolume,Sturnover,Samplitude,Shighest,Slowest,Stoday,Syesterday) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)",
(self.No, Ssymbol, Sname, Soffer, SchangeRate, SchangePrice, Svolume, Sturnover, Samplitude, Shighest,
Slowest, Stoday, Syesterday))
except Exception as err:
print(err)
def process(self):
try:
time.sleep(1)
print(self.driver.current_url)
datas = self.driver.find_elements_by_xpath("//table[@id='table_wrapper-table']/tbody/tr")
for data in datas:
try:
datas1 = data.text.split(" ")
Ssymbol = datas1[1]
Sname = datas1[2]
Soffer = datas1[6]
SchangeRate = datas1[7]
SchangePrice = datas1[8]
Svolume = datas1[9]
Sturnover = datas1[10]
Samplitude = datas1[11]
Shighest = datas1[12]
Slowest = datas1[13]
Stoday = datas1[14]
Syesterday = datas1[15]
except:
Ssymbol = " "
Sname = " "
Soffer = " "
SchangeRate = " "
SchangePrice = " "
Svolume = " "
Sturnover = " "
Samplitude = " "
Shighest = " "
Slowest = " "
Stoday = " "
Syesterday = " "
self.No = self.No + 1
self.insertDB(Ssymbol, Sname, Soffer, SchangeRate, SchangePrice, Svolume, Sturnover, Samplitude,
Shighest, Slowest, Stoday, Syesterday)
try:
self.driver.find_element_by_xpath(
"//div[@class='dataTables_paginate paging_input']//a[@class='next paginate_button disabled']")
except:
nextPage = self.driver.find_element_by_xpath(
"//div[@class='dataTables_paginate paging_input']//a[@class='next paginate_button']")
time.sleep(10)
if (self.No <= 60):
nextPage.click()
self.process()
except Exception as err:
print(err)
def executeSpider(self, url):
print("Spider processing......")
self.process()
spider = MySpider()
fs = {
"沪深A股": "/gridlist.html#hs_a_board",
"上证A股": "/gridlist.html#sh_a_board",
"深证A股": "/gridlist.html#sz_a_board"
}
starttime = datetime.datetime.now()
count = 0
for i in fs.keys():
url = "http://quote.eastmoney.com/center" + fs[i]
print("Spider starting......")
spider.start(url)
spider.executeSpider(url)
print("Spider closing......")
spider.close()
print("Spider completed......")
endtime = datetime.datetime.now()
elapsed = (endtime - starttime).seconds
print("Total ", elapsed, " seconds elapsed")
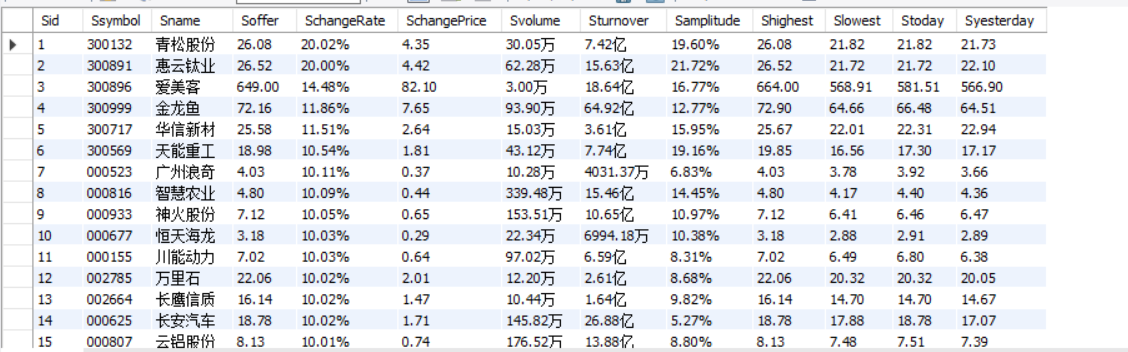
2)、心得体会:
这次实验又是股票,主要参照之前打好的爬取股票代码,并结合之前学的一些东西进行一些修改就完成了
作业③
1)、使用Selenium框架+MySQL爬取中国mooc网课程资源信息实验
主函数:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import pymysql
import time
class MySpider:
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
def startUp(self, url):
chrome_options = Options()
self.driver = webdriver.Chrome(options=chrome_options)
self.driver.maximize_window() # 最大化浏览器
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="123456", db="mydb",
charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("DROP TABLE IF EXISTS mooc")
# 创建表
self.cursor.execute("CREATE TABLE IF NOT EXISTS mooc(id INT PRIMARY KEY,"
"cCourse VARCHAR(256),"
"cCollege VARCHAR(256),"
"cTeacher VARCHAR(256),"
"cTeam VARCHAR(256),"
"cCount VARCHAR(256),"
"cProcess VARCHAR(256),"
"cBrief VARCHAR(256))")
self.opened = True
self.No = 0
except Exception as err:
print(err)
self.opened = False
self.driver.get(url)
def closeUp(self):
try:
self.con.commit()
self.con.close()
self.driver.close()
except Exception as err:
print(err);
def insertDB(self, cNo, cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief):
try:
self.cursor.execute(
"insert into mooc( id, cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief) values(%s,%s,%s,%s,%s,%s,%s,%s)",
(cNo, cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief))
except Exception as err:
print(err)
def processSpider(self):
try:
lis = self.driver.find_elements_by_xpath(
"//div[@class='_1aoKr']//div[@class='_1gBJC']//div[@class='_2mbYw']")
for li in lis:
li.find_element_by_xpath(".//div[@class='_3KiL7']").click()
last_window = self.driver.window_handles[-1]
self.driver.switch_to.window(last_window)
print(self.driver.current_url)
time.sleep(2)
try:
cCource = self.driver.find_element_by_xpath("//span[@class='course-title f-ib f-vam']").text
print(cCource)
cCollege = self.driver.find_element_by_xpath("//img[@class='u-img']").get_attribute("alt")
print(cCollege)
cTeacher = self.driver.find_element_by_xpath(
"//div[@class='um-list-slider_con']/div[position()=1]//h3[@class='f-fc3']").text
print(cTeacher)
z = 0
while (True):
try:
cTeam = self.driver.find_elements_by_xpath(
"//div[@class='um-list-slider_con_item']//h3[@class='f-fc3']")[z].text
print(cTeam)
z += 1
except:
break
cCount = self.driver.find_element_by_xpath(
"//span[@class='course-enroll-info_course-enroll_price-enroll_enroll-count']").text
print(cCount)
cProcess = self.driver.find_element_by_xpath(
"//div[@class='course-enroll-info_course-info_term-info_term-time']//span[position()=2]").text
print(cProcess)
cBrief = self.driver.find_element_by_xpath("//div[@id='j-rectxt2']").text
print(cBrief)
except Exception as err:
print(err)
self.driver.close()
old_window = self.driver.window_handles[1]
self.driver.switch_to.window(old_window)
self.No = self.No + 1
no = str(self.No)
while len(no) < 3:
no = "0" + no
print(no)
self.insertDB(no, cCource, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief)
try:
nextpage = self.driver.find_element_by_xpath("//a[@class='_3YiUU ']")
time.sleep(3)
nextpage.click()
self.processSpider()
except:
self.driver.find_element_by_xpath("//a[@class='_3YiUU _1BSqy']")
except Exception as err:
print(err)
def executeSpider(self, url):
print("Spider starting......")
self.startUp(url)
print("Spider processing......")
start = self.driver.find_element_by_xpath("//span[@class='_2KM6p']//a[@href]")
start.click()
last_window = self.driver.window_handles[-1]
self.driver.switch_to.window(last_window)
self.processSpider()
print("Spider closing......")
self.closeUp()
spider = MySpider()
url = "https://www.icourse163.org/"
spider = MySpider()
spider.executeSpider(url)
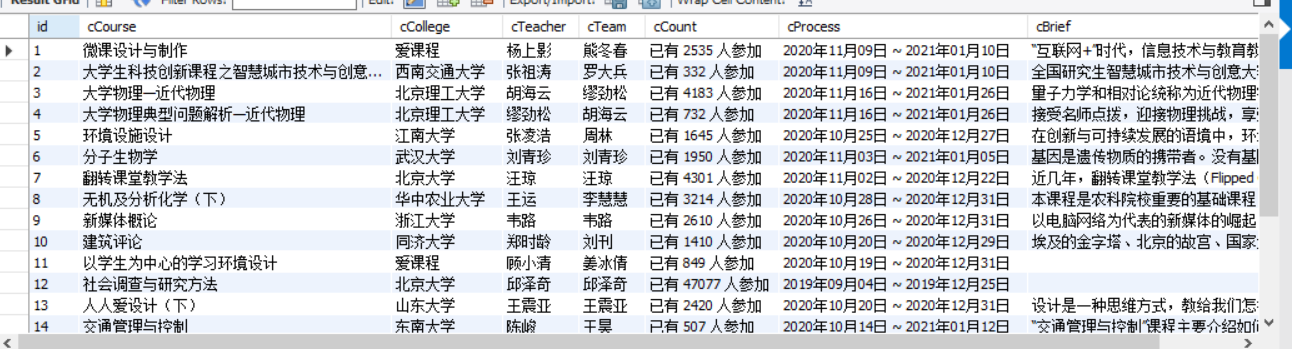
2)、心得体会:
这次实验最为关键的是click操作。有一个问题困扰了很久,花了很长时间才解决。打开chrome浏览器时,它是最小化的,屏幕只显示了前四个课程的图片,所以爬取到第五个课程就会出现有关点击的报错。花了好久的时间才找到这一个小问题,加了一句最大化浏览器的语句就解决了。尚未完成功能:登录以及爬取讲师团队人数大于三人的全部团队信息
