结对编程作业
一、博客开头
1、自己的博客链接:https://www.cnblogs.com/lkx15260/p/13819781.html
队友的博客链接:https://www.cnblogs.com/fzujch/p/13843158.html
2、自己的Github项目地址:https://github.com/101347/team-work
队友的Github项目地址:https://github.com/jchxch/jigsaw
3、具体分工:
| 分工 | 人员 |
|---|---|
| AI | 金昌鸿 |
| 原型设计实现 | 林坤贤 |
| 博客编写 | 林坤贤 |
| Github使用相关 | 金昌鸿 |
二、原型设计
1)设计说明:

2)原型模型设计工具: Axure Rp
3)结对照片:

4)遇到的困难及解决方法:
第一次接触这类软件,面对陌生的功能以及一堆英文不知道从哪里下手。最后通过CSDN以及b站教学视频,将Axure Rp汉化,并花了些时间学习了许多相关操作,从而使完成过程变得容易了很多。
前期花了一定时间学习操作,剩下的制作过程挺顺利的,之后就没有遇到什么困难了
三、AI设计实现
3.1代码实现思路
1)网络接口的使用
def gethtml(url_get):#获取题目信息
try:
url = 'http://47.102.118.1:8089/api/challenge/start/'+url_get
body = {
"teamid": 18,
"token": "87224375-52f9-4269-9674-780baf50d7d1"
}
resp = requests.post(url, json=body)
# resp.raise_for_status()
# resp.encoding = resp.apparent_encoding
print(resp.text)
return resp.text
except:
print('err')
def get_question(url):#提取题目信息,保存并返回
text = json.loads(gethtml(url))#将下载到的文本转位json格式
print(text.keys())#ai大比拼'img', 'step', 'swap', 'uuid'在'data'的值中
data=text["data"]
print(data.keys())
img_base64 = data["img"]
step = data["step"]
swap = data["swap"]
uuid = text["uuid"]
img = base64.b64decode(img_base64)
# 获取接口的图片并写入本地
def submit(uuid,op,swap_out):#上传答案
try:
if swap_out==[]:
s_out=[]
else:
s_out=swap_out[0]
url = 'http://47.102.118.1:8089/api/challenge/submit'
body = {
"uuid": uuid,
"teamid": 18,
"token": "87224375-52f9-4269-9674-780baf50d7d1",
"answer": {
"operations": op,
"swap": s_out
}
}
resp = requests.post(url, json=body)
resp.raise_for_status()
resp.encoding = resp.apparent_encoding
print(resp.text)
return resp.text
except:
print('err')
2)代码组织与内部实现设计(类图)

3)说明算法的关键与关键实现部分流程图
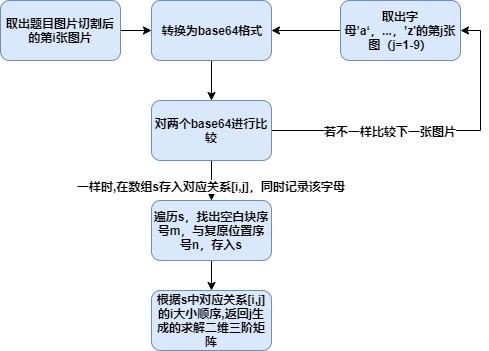
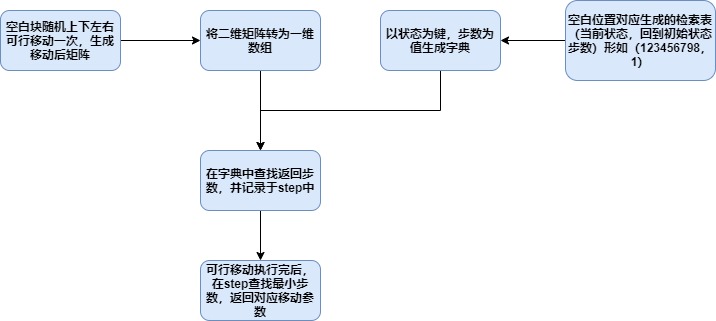
4)重要的代码片段
受题目启发,用base64的格式进行图片的比较,最大的感受是快很多,而且实现简单,相比rgb的读入格式,这极大地缩小了数据量的比较
for file in TrainFiles: # 所有字母
count = 0#与每一个字母文件夹遍历比较,题目图片应该与原图片有8张小图片相同
blank = []#记录匹配图片对应关系
p1 = os.listdir('./picture/' + file)
path = './answer'
if not os.path.exists(path):
os.mkdir('answer')
for problem1 in os.listdir("problem"):
for p2 in p1: # p1字母对比
with open("./picture/" + file + "/" + p2, "rb") as f: # 转为二进制格式
base64_data1 = base64.b64encode(f.read()) # 使用base64进行加密
with open("./problem/" + problem1, "rb") as f: # 转为二进制格式
base64_data2 = base64.b64encode(f.read()) # 使用base64进行加密
if base64_data1 == base64_data2:
count = count + 1
img = Image.open("./problem/" + problem1)
img.save("./answer/" + p2)
blank.append([problem1[0], p2[0]])
当前三阶矩阵有解的条件是由当前状态生成的逆序数必须为偶数,我们组想到了一个虽然不是最优但很方便的方法,交换第一个有逆序数的数与其后一位数
def swap(qi, p):#更换棋盘矩阵中第p位与第p+1位的图片
qi_wezhi=qi.bk_x*3+qi.bk_y#判断空白块是否在交换格子的左边
if p>=qi_wezhi:
p=p+1
p_next=p+1
x_p_next = math.floor(p_next / 3)#判断空白块是否在交换格右边
y_p_next = p_next % 3
if x_p_next==qi.bk_x and y_p_next==qi.bk_y:
p_next=p_next+1
print('swap[%d , %d]' % (qi.qipan[p // 3][p % 3], qi.qipan[p_next // 3][p_next % 3]))
t_1 = qi.qipan[p // 3][p % 3]
qi.qipan[p // 3][p % 3] = qi.qipan[p_next // 3][p_next % 3]
qi.qipan[p_next // 3][p_next % 3] = t_1
return p,p_next
5)性能分析与改进
当初开始想到的是转为RGB格式比较,实现复杂,耗时大,后面转为base64,很好用,极大减少匹配图片上的时间。
6)描述你改进的思路
该算法遇到初始不可解的三阶矩阵时,还只能随机执行移动,改进方向:利用强制交换,加快求解
7)展示性能分析图和程序中消耗最大的函数
主要是匹配图片时图片的打开消耗的比较大
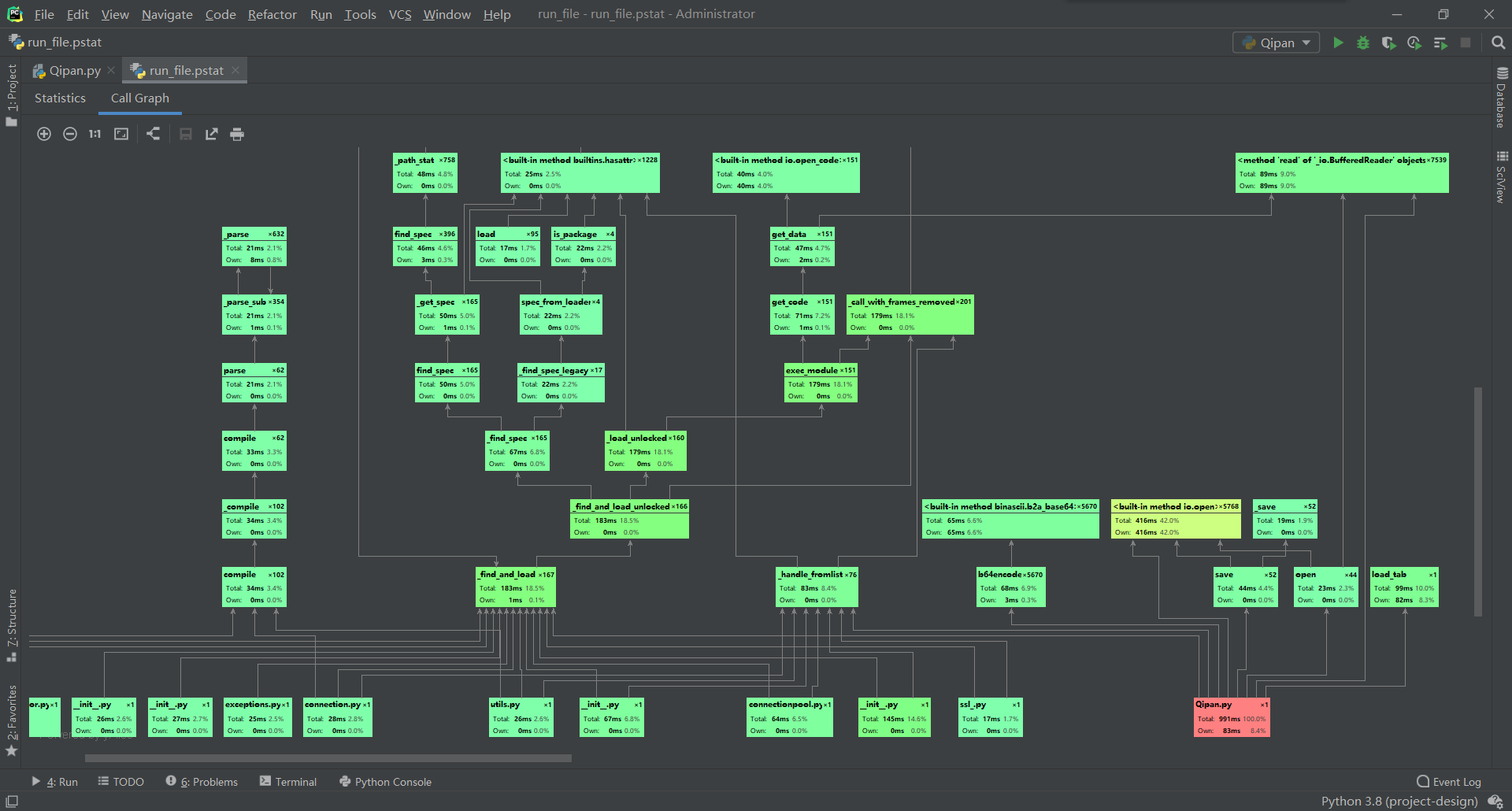
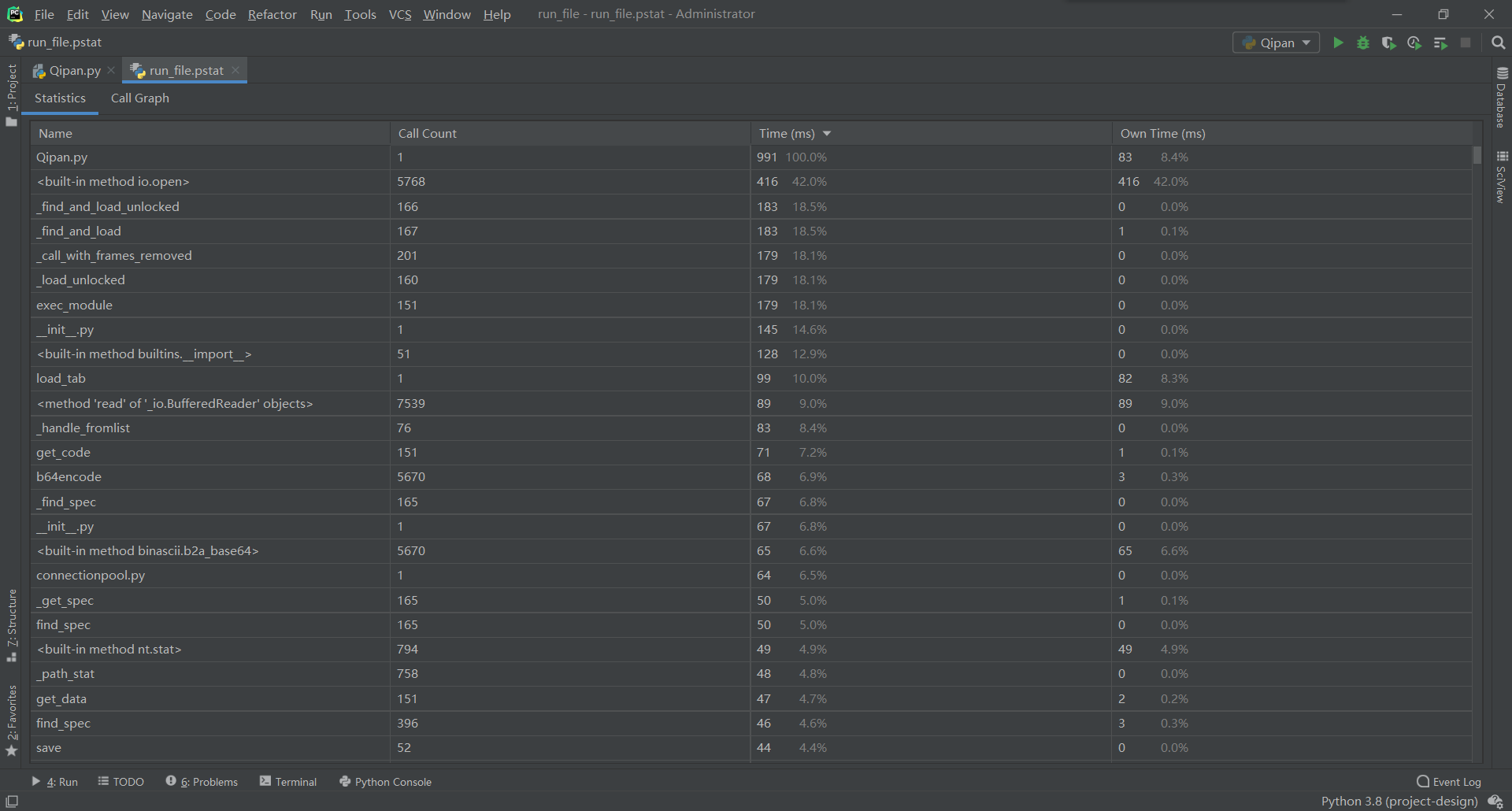
8)展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路
def gethtml(url_get):
try:
url = 'http://47.102.118.1:8089/api/challenge/start/'+url_get
body = {
"teamid": 18,
"token": "87224375-52f9-4269-9674-780baf50d7d1"
}
resp = requests.post(url, json=body)
print(resp.text)
return resp.text
except:
print('err')
def get_question(url):
text = json.loads(gethtml(url))#将下载到的文本转位json格式
print(text.keys())#dict_keys(['img', 'step', 'swap', 'uuid'])
data=text["data"]
print(data.keys())
img_base64 = data["img"]
step = data["step"]
swap = data["swap"]
uuid = text["uuid"]
img = base64.b64decode(img_base64)
# 获取接口的图片并写入本地
with open("photo.jpg", "wb") as fp:
fp.write(img)
return swap,step,uuid
def submit(uuid,op,swap_out):
try:
if swap_out==[]:
s_out=[]
else:
s_out=swap_out[0]
url = 'http://47.102.118.1:8089/api/challenge/submit'
body = {
"uuid": uuid,
"teamid": 18,
"token": "87224375-52f9-4269-9674-780baf50d7d1",
"answer": {
"operations": op,
"swap": s_out
}
}
resp = requests.post(url, json=body)
resp.raise_for_status()
resp.encoding = resp.apparent_encoding
print(resp.text)
return resp.text
except:
print('err')
def gethtml(url_get):
try:
url = 'http://47.102.118.1:8089/api/challenge/start/'+url_get
body = {
"teamid": 18,
"token": "87224375-52f9-4269-9674-780baf50d7d1"
}
resp = requests.post(url, json=body)
print(resp.text)
return resp.text
except:
print('err')
def get_question(url):
text = json.loads(gethtml(url))#将下载到的文本转位json格式
print(text.keys())#dict_keys(['img', 'step', 'swap', 'uuid'])
data=text["data"]
print(data.keys())
img_base64 = data["img"]
step = data["step"]
swap = data["swap"]
uuid = text["uuid"]
img = base64.b64decode(img_base64)
# 获取接口的图片并写入本地
with open("photo.jpg", "wb") as fp:
fp.write(img)
return swap,step,uuid
def submit(uuid,op,swap_out):
try:
if swap_out==[]:
s_out=[]
else:
s_out=swap_out[0]
url = 'http://47.102.118.1:8089/api/challenge/submit'
body = {
"uuid": uuid,
"teamid": 18,
"token": "87224375-52f9-4269-9674-780baf50d7d1",
"answer": {
"operations": op,
"swap": s_out
}
}
resp = requests.post(url, json=body)
resp.raise_for_status()
resp.encoding = resp.apparent_encoding
print(resp.text)
return resp.text
except:
print('err')
3.2贴出Github的代码签入记录,合理记录commit信息。

3.3遇到的代码模块异常或结对困难及解决方法
解决方法,判断交换位置前面,与左边位置是否为空白块,进行修正。
3.5评价你的队友
学习能力强,对项目积极主动,带动我学习
没啥需要改进的,这样的队友,很棒
四、提供此次结对作业的PSP和学习进度条
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 500 | 500 |
| · Estimate | · 估计这个任务需要多少时间 | 500 | 500 |
| Development | 开发 | 1225 | 1325 |
| · Analysis | · 需求分析 (包括学习新技术) | 600 | 620 |
| · Design Spec | · 生成设计文档 | 30 | 30 |
| · Design Review | · 设计复审 | 40 | 35 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| · Design | · 具体设计 | 45 | 60 |
| · Coding | · 具体编码 | 360 | 390 |
| · Code Review | · 代码复审 | 30 | 40 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 90 | 120 |
| Reporting | 报告 | 105 | 120 |
| · Test Repor | · 测试报告 | 30 | 45 |
| · Size Measurement | · 计算工作量 | 30 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 45 | 45 |
| · 合计 | 1830 | 1945 |
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 0 | 0 | 1 | 1 | 熟悉Python语言class特性 |
| 2 | 78 | 78 | 2 | 3 | 理解华容道游戏的游戏框架与实现过程 |
| 3 | 215 | 293 | 3.5 | 6.5 | 学习了Pyqt5的许多操作;熟悉了base64图片操作 |
| 4 | 666 | 959 | 8 | 14.5 | 熟悉了bfs用法、request用法;理解了字典操作;熟悉了Axure RP的基本操作 |

