

centos7下安装docker(18.2docker日志---ELK)
ELK是三个软件得组合:Elasticsearch,Logstash,Kibana
Elasticsearch:实时查询的全文搜索引擎。Elasticsearch的设计目的就是能够处理和搜索巨量的日志数据
Logstash:读取原始日志,并对其进行分析过滤,然后将其转发给其他组件,(比如elasticsearch)进行所以或存储,Logstash支持丰富的INPUT和Output类型,能够处理各种应用日志
Kibana:一个基于javascript的web图形界面程序,专门用于可视化elasticsearch的数据。kibana能够查询elasticsearch并通过丰富的图表展示结果,用户创建dashboard来监控系统日志。
日志处理流程,如盗图:
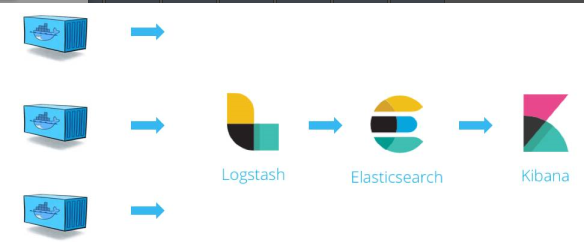
logstash负责从各个docker容器中提取日志,logstash将日志转发给elasticsearch进行索引和保存,kibana分析和可视化数据
进行部署:
1.安装ELk套件:
ELK的部署方案可以非常灵活,在规模较大的生产系统中,ELK有自己的集群,实现了高可用负载均衡。我们可以在容器中实现最小部署方案:
docker run -p 5601:5601 -p 9200:9200 -p 5044:5044 -it --name elk sebp/elk
我们使用的是sebp/elk这个现成的镜像,里面包含了整个ELK stack(这是我见过的层次最多的镜像)。容器启动后ELK各个组件将分别监听如下端口:
5601:kibana web接口
9200:elasticsearch JSON接口
5044:logstash 日志接受接口
在启动容器的时候出现以下错误:
[ERROR][o.e.b.Bootstrap ] [hrtgLaO] node validation exception
[1] bootstrap checks failed
[1]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
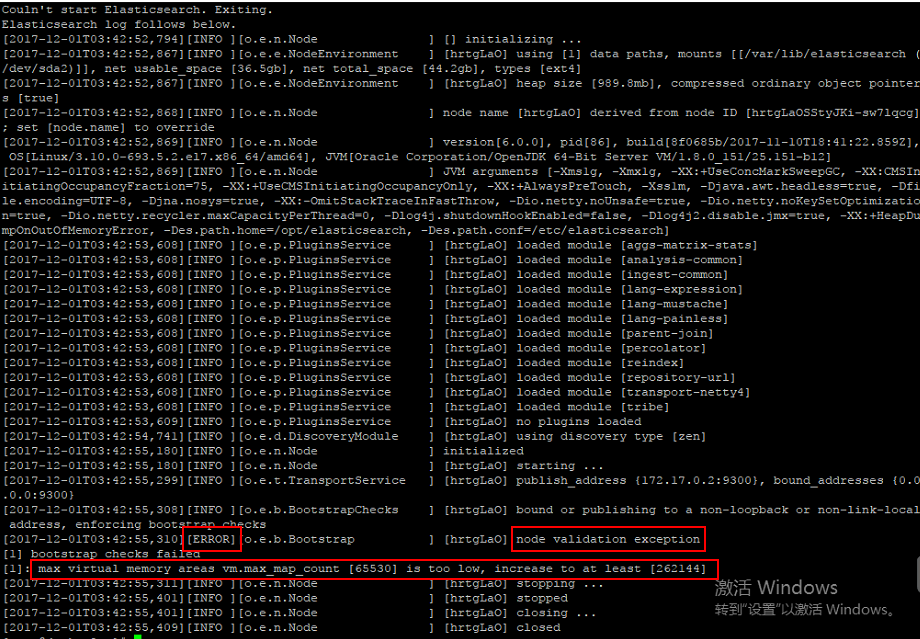
解决办法:
在/etc/sysctl.conf下添加
vm.max_map_count=655360
保存退出后,执行一下命令
sysctl -p

这个是内存报错,其他的CPU或文件数报错,也可以参考:http://blog.csdn.net/xiegh2014/article/details/53771086
容器正常运行后:

我们先来访问kibana http://ip:5601
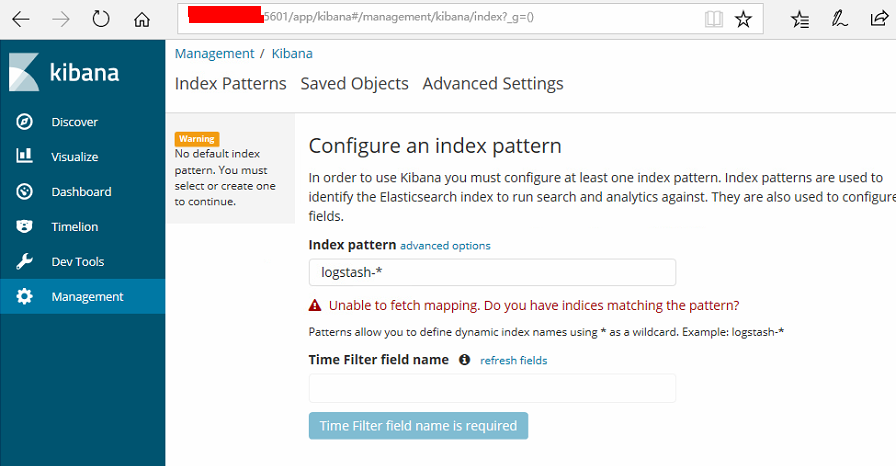
当前kibana没有可显示的数据,因为elasticsearch还没有任何日志数据
访问一下elasticsearch的JSON接口:http://ip:9200/_search?pretty
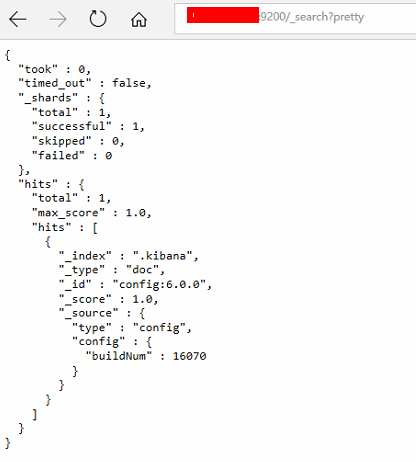
可以看出,目前elasticsearch没有与日志相关的index
将日志导入ELK并进行图形化展示:
几乎所有的软件和应用都有自己的日志文件,容器也不例外,上面我们知道docker 会将容器日志记录到/var/lib/containers/<containers_id>/<container ID>-json.log,那我们只需要将此文件发送给ELK就可以实现日志管理
其实要实现这一步也不难,因为ELK提供了一个配套小工具Filebeat,他将指定路径下的日志文件转发给ELK。同时Filebeat很聪明,他将监控日志的文件,当日志更新时,Filebeat会将新的内容发送给ELK
安装filebeat
在docker host中安装配置filebeat,可根据官网:https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-installation.html
![]()

由于我们使用的是centos的操作系统,这里选择使用YUM的安装方式:参考:https://www.elastic.co/guide/en/beats/filebeat/current/setup-repositories.html
1.下载安装密钥: rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch
2.建立源vim /etc/yum.repos.d/elastic.repo
[elastic-6.x] name=Elastic repository for 6.x packages baseurl=https://artifacts.elastic.co/packages/6.x/yum gpgcheck=1 gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch enabled=1 autorefresh=1 type=rpm-md

3.安装filebeat
yum install filebeat

4.设置开机自启动
systemctl enable filebeat

配置filebeat
filebeat的配置文件/etc/filebeat/filebeat.yml,我们需要告诉filebeat两件事:
1.监控哪些日志文件?
2.将日志文件发送到哪里?
首先第一个问题:

在paths中我们配置了两条路径:
1。/var/log/*.log是Host操作系统的日志
2./var/lib/docker/containers/*/*.log是所有容器的日志文件路径
接下来是告诉filebeat将这些日志文件发送到elk
filebeat可以将日志发送给elasticsearch进行索引和保存,也可以发送给logstash先进行分析和过滤,然后由logstash转发给elasticsearch进行分析和过滤
1.先将日志直接发给elasticsearch
vim /etc/filebeat/filebeat.yml
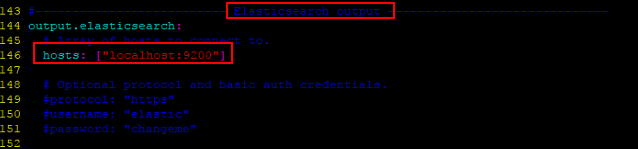
默认的设置,不需更改
当前的日志处理流程如下图:盗图
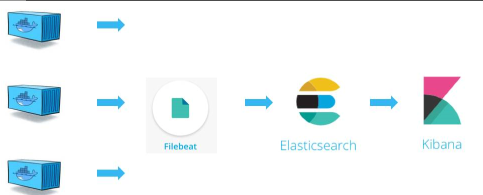
2.filebeat现将日志文件发送给logstash进行过滤分析,再转给elasticsearch
vim /etc/filebeat/filebeat.yml

修改好filebeat的配置文件后重启filebeat服务:systemctl restart filebeat
管理日志:
filebeat服务启动后,正常情况下会将监控日志发送给elasticsearch。刷新elasticsearch的JSON接口http://ip:9200/_search?pretty进行确认

这次我们能看到filebeat-*的index,以及filebeat监控的那两个路径下的日志
现在,elasticsearch已经创建了日志的索引并保存起来,接下来是在kibana中展示日志
首先需要配置一个index pattern,及告诉kibana查询和分析elasticsearch中那些日志
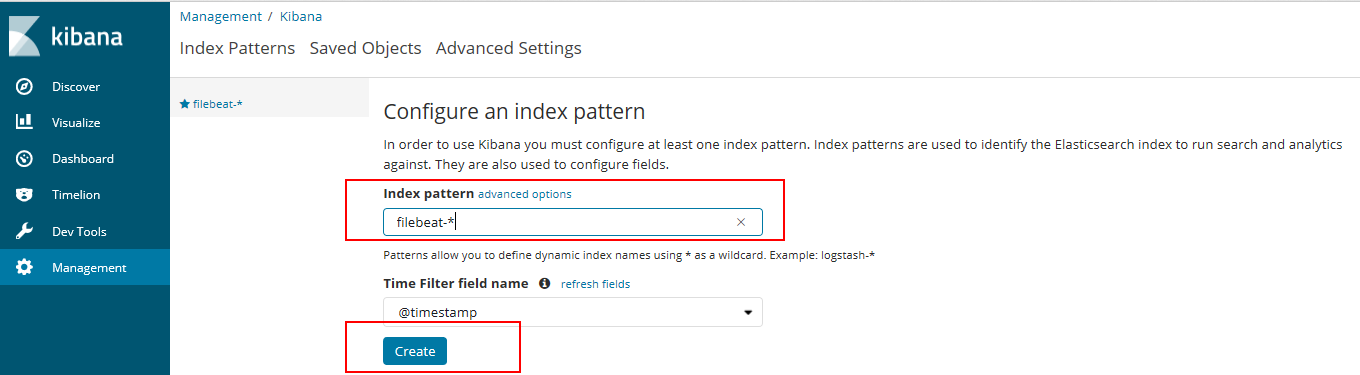
1.指定index pattern为filebeat-*,这与elasticsearch中的index一致
2.Time-files name 选择@timestamp
3.点击create创建index pattern
点击kibana左侧的discover菜单,便可看到容器和syslog日志信息

刷新kibana界面右上角的
就能看到新的日志

kibana也提供了强大的搜索功能,比如输入关键字busybox能搜索出所有匹配的日志条目
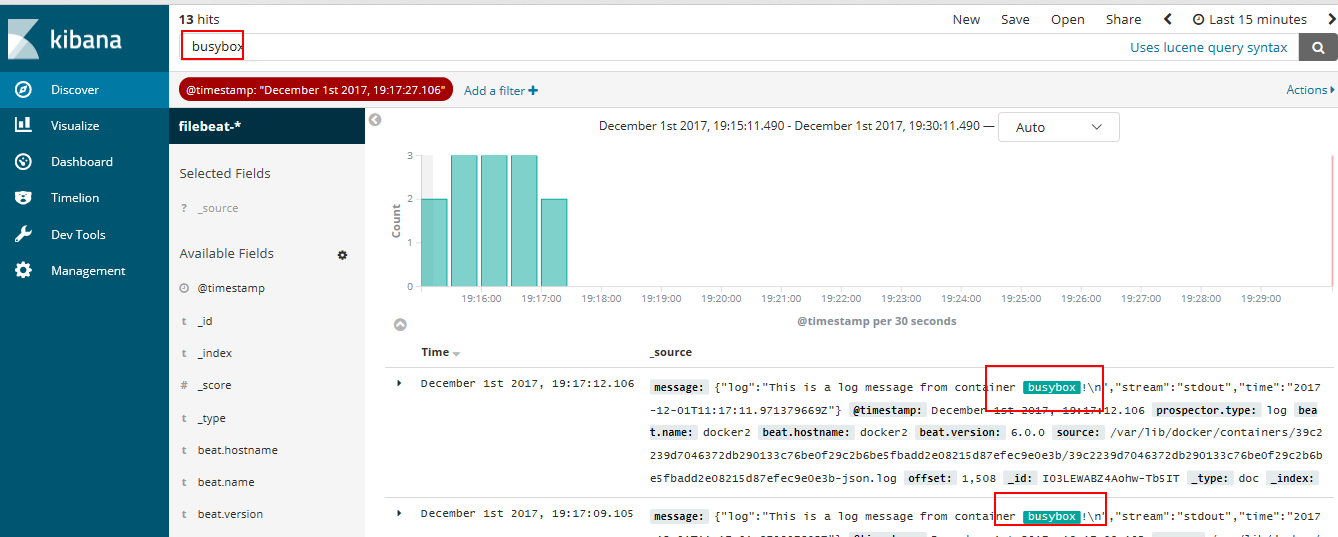
我们这里只是简单的将日志导入ELK并朴素的显示出来,我们用的是filebeat将收集来的信息直接转发给elasticsearch搜索,而不是转发给logstach进行分析过滤,。实际上ELK可以创建更炫酷的dashboard,可以挖掘的内容很多。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号