与JavaWeb有关的故事(web请求与Java I/O)
作为一名后端屌丝程序员,对算法、并发、性能乐此不疲。但是,随着年龄和阅历的增加,显然叶落而不知秋的心态是不太能混了。尤其是,某T面试官在明知我是后端,且明确表示对HTTP协议不太熟的情况下,强行让我解释HTTP状态码200至600的含义。这,便是本篇的初衷,讲一讲后端眼里的前端故事。内容基于《深入分析JavaWeb技术内幕》,加入了自己的理解,思维会比较跳跃,需要后端基础。
web请求过程
作为一名从CS架构转入BS架构的后端,不得不说,BS是趋势也是方向,两个好处:
- 客户端使用统一的浏览器,使用配置简单
- 服务端基于统一的HTTP,简化开发模式,并且开源服务器众多,开发成本低
B/S网络架构
CS架构通常是长链接交互数据,而BS架构是通过基于HTTP协议的无状态的短链接通讯。当在浏览器输入`http://www.cnblogs.com/1024Community/`时,会发生一系列动作,最终将需要的信息返回到浏览器。其中涉及很多概念,如DNS解析、CDN、负载均衡等(后续会详解),但是基本架构还是差不多,基本流程是:浏览器输入URL---DNS解析成对应IP---负载均衡服务器---CDN---服务端系统---分布式缓存---文件系统/DB
包含CDN的架构图:
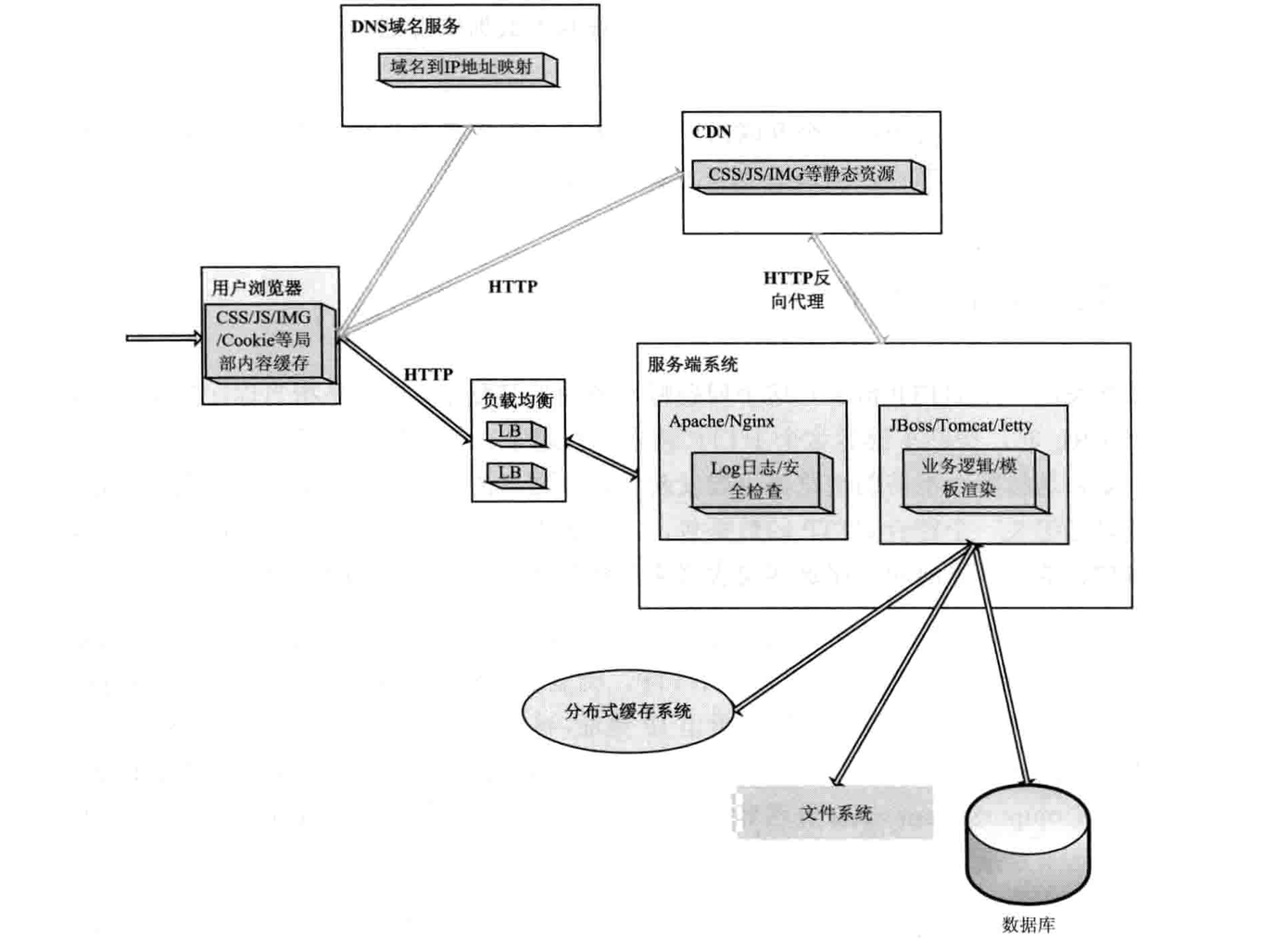
发起一个HTTP请求
概括为,通过URL解析到服务器IP,建立socket链接,发送符合HTTP规范的输入流,等待服务器返回数据,然后断开链接。linux中curl+URL命令,可以简单发起一个HTTP请求。HTTP解析
HTTP是BS网络架构的核心,程序员*杀人放火*之必备。 首先,要了解的是HTTP header部分,它控制着数据传输、浏览器渲染、服务器执行逻辑。 常见HTTP请求头: 常见响应头:

常见错误码:

总结:
HTTP请求头,charset、encoding、language、host、User-Agent、Connection
HTTP响应头,Server、type、encoding、language、length、Keep-Alive
HTTP常见状态码,200成功,302临时跳转,400请求语法错误,403服务器收到请求,拒绝服务,404请求资源不存在,500服务端异常
浏览器缓存机制
复杂而又重要,常用ctrl+F5组合键刷新界面,来获得最新数据。其原理是,在header中添加了两项,Pragma:no-cache和Cache-Control:no-cache。对于缓存相关的header参数,主要如下:-
Pragma/Cache-Control
缓存控制,Cache-Control优先级较高,和其他请求字段同时存在时(如Expires),会覆盖其他字段。Pragma类似,常用就是Pragma:no-cache,可选值如下:
![]()
-
Expires
指定一个日期,超过这个日期,缓存超时,重新请求 -
Last-Modified/Etag
服务端响应头中返回一个Last-Modified字段,告诉浏览器这个页面的最后修改时间。当浏览器再次请求时,在header中添加If-Modified-Since字段,来询问页面是否最新,最新则返回304,服务器也不会传送数据。
Etag类似功能,为每一个页面分配一个唯一编号,后端比较难处理,需要记住网站所有资源。

DNS域名解析
将域名解析成地址,非常重要。整个HTTP通信都是基于TCP/IP协议簇的,没有IP地址就没法通信,但是IP地址是一串数字,难记,所以有了IP和域名的对应关系。有了对应关系,就要有解析,知道域名通过对应关系,就能得到IP,从而建立起通信。DNS域名解析过程
看书说话,我们来捋一捋,当你在浏览器输入一串URL时,怎么找到的对应服务器IP 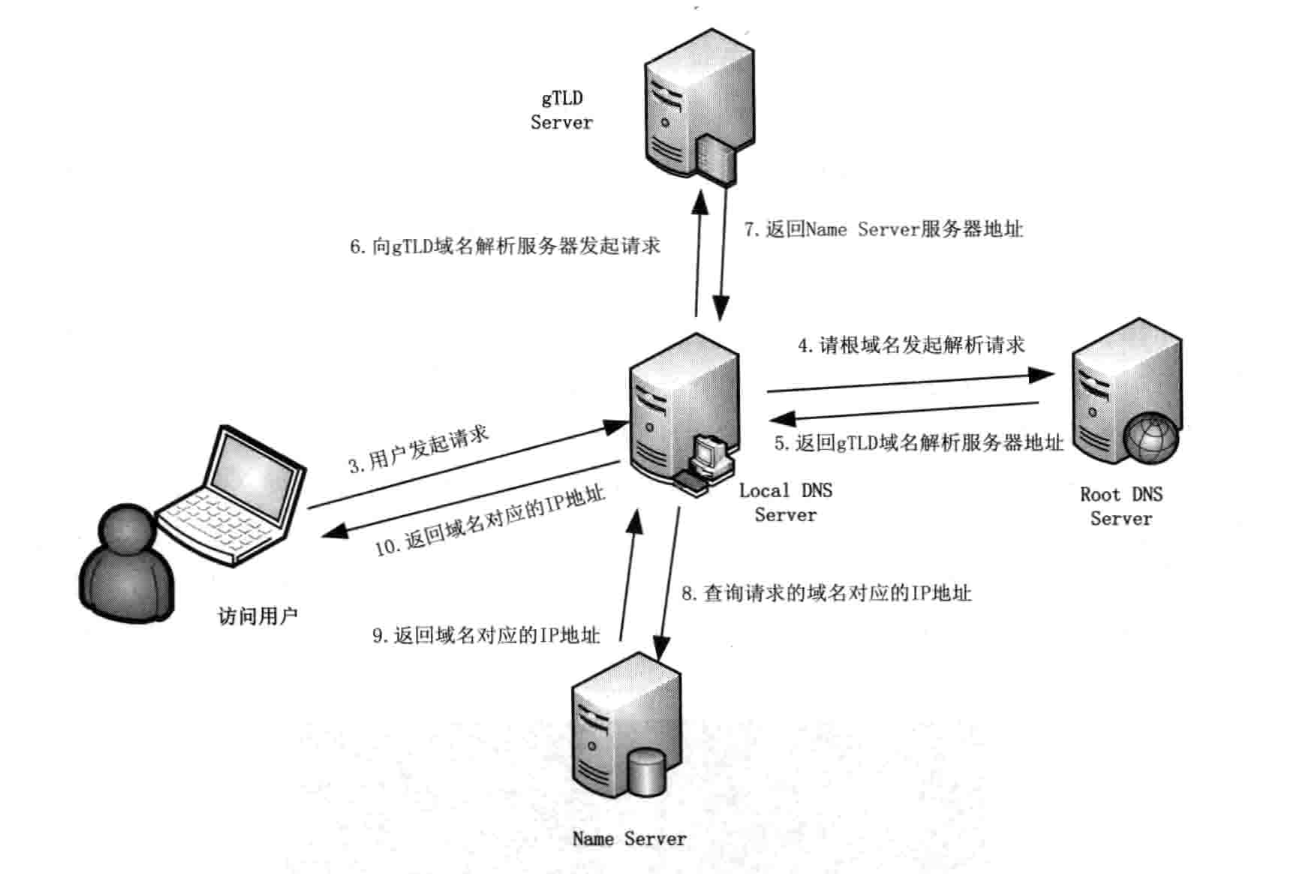- 浏览器检查本地缓存,缓存有实效,通过TTL(DNS记录在DNS服务器上缓存时间)设置
- 检查操作系统缓存,linux下在/etc/hosts
- 本地区域名服务器,LDNS
- Root Server域名服务器
- 根域名服务器返回给本地域名服务器一个所查询域的主域名服务器gTLD Server地址(全球13台左右)
- LDNS在向上一步gTLD发送请求
- 接收请求的gTLD服务器查找并返回此域名对应的Name Server域名服务器地址(通常是注册的域名(提供商)服务器)
- Name Server查询存储的域名和IP映射关系,连同一个TTL值返回给DNS Server
- 返回该域名对应的IP和TTL值,LDS会缓存这个对应关系
- 把解析结果返回给用户,用户根据TTL值缓存在本地
Tips:
win下使用nslookup,linux使用dig查询解析过程。 两个缓存地方LDS和本地机器,可用命令刷新,JVM也会缓存DNS结果,使用InetAddress时,注意使用单例模式,避免性能问题。
CDN工作机制
Content Delivery Network(内容分布网络)类似镜像+缓存+整体LB,通常缓存静态资源,用户主站取动态数据,CDN下载静态数据。目标:可扩展,安全性,可靠性。CDN架构
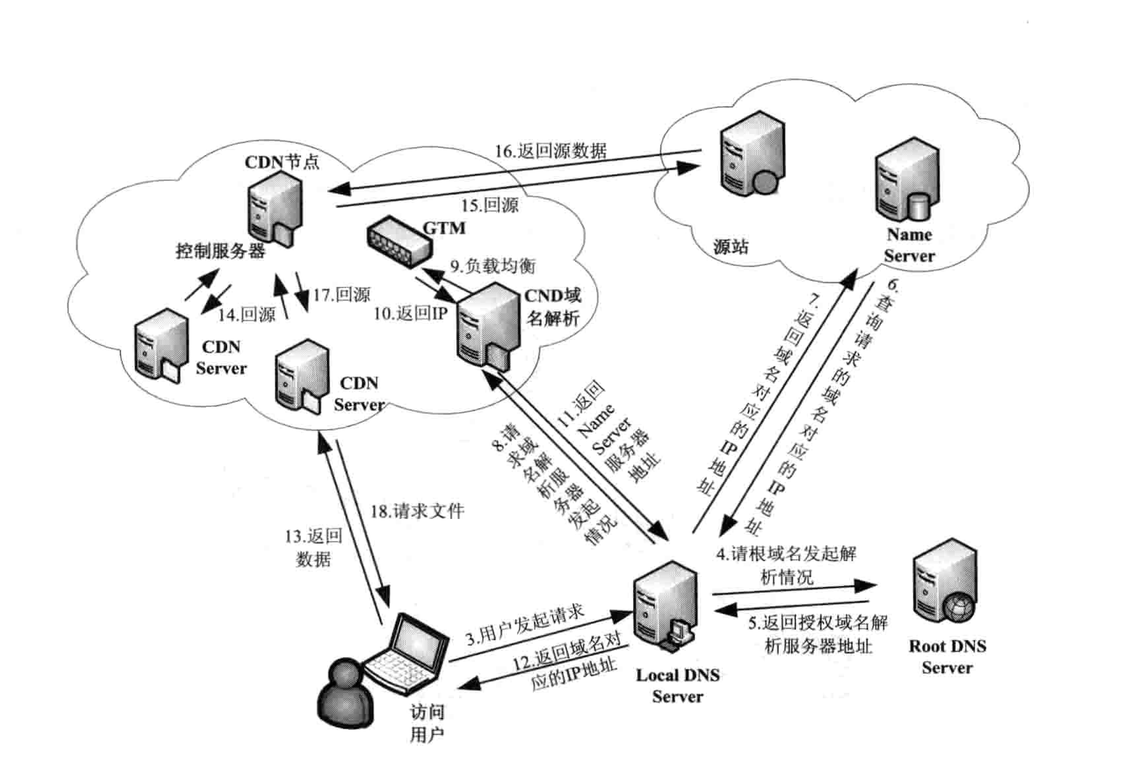
看图说话,通过域名解析,通常会CNAME到CDN全局中的DNS负载均衡服务器,在通过这个GTM(广域网流量管理)分配到离用户最近的CDN节点。用户就可以到这个节点访问静态文件了。
负载均衡
负载均衡,分为链路LB(DNS解析成不同IP)、集群LB(分为硬件和软件,硬件贵,性能好,但不能动态扩容,如F5;软件LB,如LVS)、操作系统LB(软中断和硬件中断,如多队列网卡)。CDN动态加速
`总结为,通过CDN的DNS解析中通过动态的链路探测寻找回源最佳路径,然后通过DNS调度将所有请求调度到选定的路径上回源,加速用户访问效率`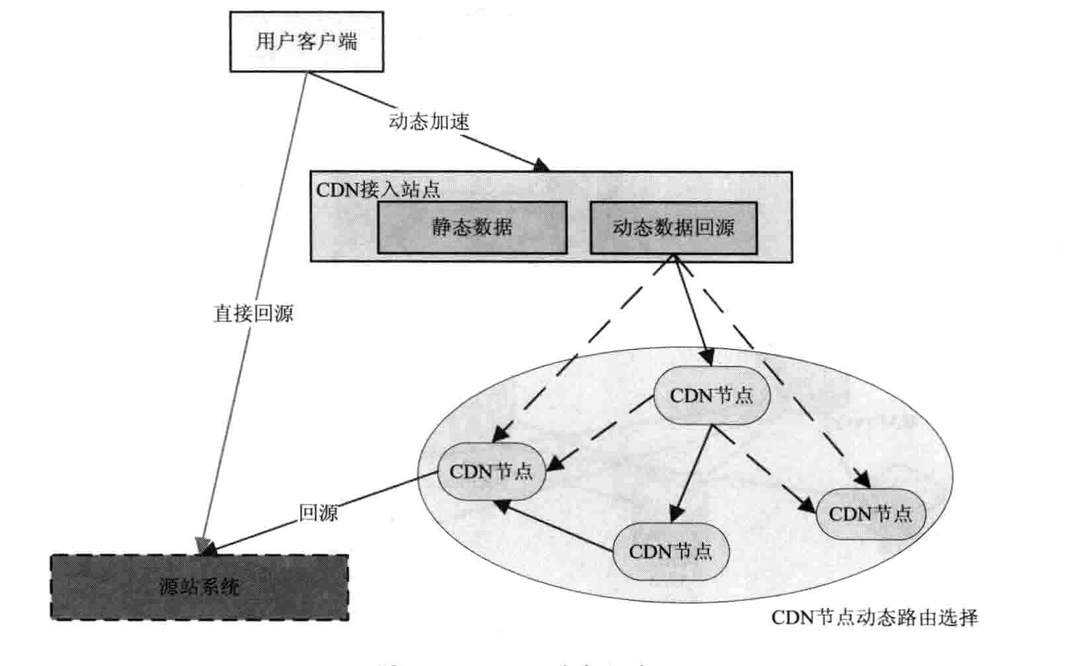
Java I/O的工作机制
Java I/O类库的基本架构
IO问题是人机交互的核心问题,是获取和交换信息的渠道,向来是应用系统的瓶颈,Java也在持续优化,如1.4版本引入了NIO。整个java.io包几十个类,有些概念不再详细介绍了(如字节流、字符流、io包继承结构),总体上看IO大体分为: 1. 基于字节操作的io接口:InputStream和OutputStream 2. 基于字符操作的io接口:Writer和Reader 3. 基于磁盘操作的io接口:File 4. 基于网络操作的io接口:Socket(也算是IO)字节和字符的转化
首先,数据持久化或网络传输都是以字节进行的,这就涉及一个字符和字节转化的问题,其中最重要的就是字符集编码问题,否则很容易出现常见的乱码问题,字符解码类图如下:
其中InputStreamReader类是从字节到字符转化桥梁,过程中要指定字符集,否则使用操作系统默认。
补充个UML知识,上图中使用的是组合,是整体与部分的关系,代码实现就是成员变量,如下

读的时候,字节流转化为字符,要解码(StreamDecoder),同样道理,写入是从字符到字节,需要编码(StreamEncoder)
磁盘IO工作机制
几种访问文件方式
访问文件,读取和写入是调用操作系统的IO接口,因为磁盘是由操作系统管理。而只要是系统调用就会存在内核空间和用户空间切换问题,这本身是操作系统保护本身运行安全的机制,这就会出现一个问题,`内核空间和用户空间的数据复制`,由于内核空间访问快,用户空间访问慢,所以,出现了缓存。这是基本原理,几种访问文件方式如下: 1. 标准访问文件方式(实际上读写都是和内核空间缓存打交道,什么时候刷新到磁盘由操作系统决定) 2. 直接IO方式(内核不缓存,直接和磁盘IO打交道,慢,通常结合异步IO提升性能) 3. 同步访问文件(和标准访问类似,但是等缓存数据刷新到磁盘,才返回给应用) 4. 异步访问方式(访问发出后,不阻塞,异步返回) 5. 内存映射方式(把内核空间和磁盘文件关联,共享数据,减少`数据复制`操作)Java访问磁盘文件
File对象是个虚拟的描述,解码类StreamDecoder、真正的文件描述类FileDescriptor,一图胜万言,如下,
Java序列化技术
序列化就是将一个对象转为为一串二进制的字节数组,通过保存或转移这些字节数据来达到持久化的目的。接口,java.io.Serializable。 对象序列化之后,查看二进制数组,会包含序列化协议、版本、是否新对象、class完整类名、UID、标记、所含域的个数、域类型、域名城、父类信息、类各属性的实际值。 几个Java序列化要点: 1. 父类继承Serializable接口时,所有子类可序列化 2. 子类实现Serializable接口时,父类没有,则只有字类的属性可序列化(不报错) 3. 如果序列化的属性是对象,则这个对象也必须实现Serializable接口,否则报错 4. 反序列化时,如果对象属性有修改或删减,修改的属性部分会丢失,不报错 5. 反序列化时,UID被修改,会失败纯Java环境,序列化可以很好的工作。多语言环境见还是推荐使用通用的数据结构如XML、JSON。
网络IO机制
TCP三次握手和四次挥手
TCP建立过程,三次握手和四次挥手,过程如下: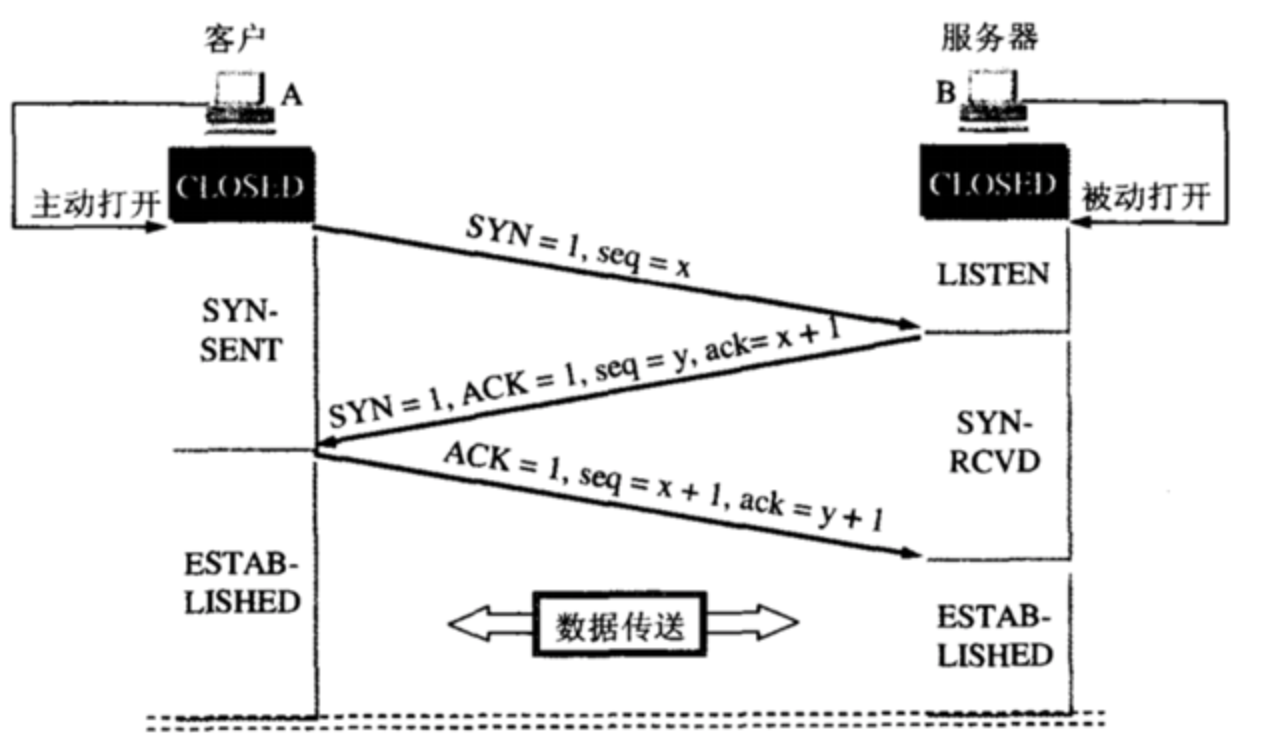
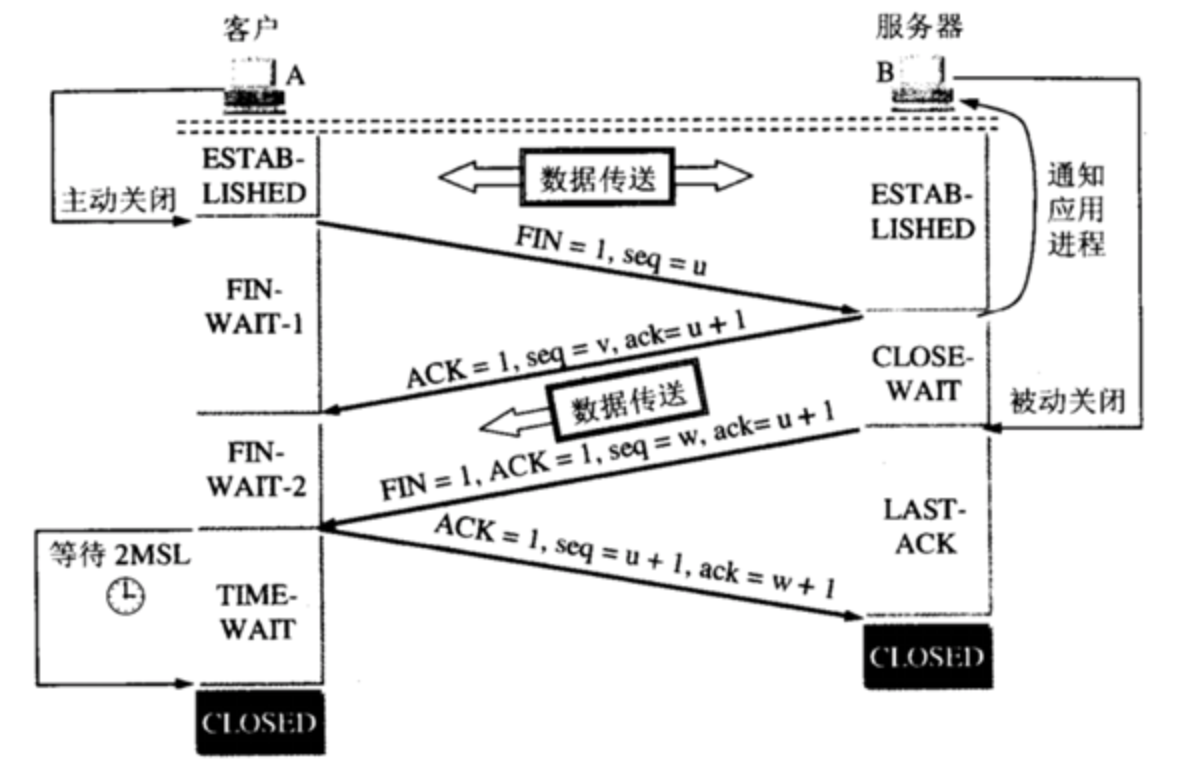
两个问题:
-
为什么A还要发送一次确认呢?可以二次握手吗?
为了防止已失效的连接请求报文段突然又传送到了B,因而产生错误 -
为什么连接的时候是三次握手,关闭的时候却是四次握手?
因为当Server端收到Client端的SYN连接请求报文后,可以直接发送SYN+ACK报文。其中ACK报文是用来应答的,SYN报文是用来同步的。但是关闭连接时,当Server端收到FIN报文时,很可能并不会立即关闭SOCKET,所以只能先回复一个ACK报文,告诉Client端,"你发的FIN报文我收到了"。只有等到我Server端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送。故需要四步握手。
Java Socket工作机制
底层TCP/IP协议,Socket和ServerSocket(accept之前是阻塞的)建立连接,通过字节流传输,传输过程中,操作系统会为InputStream和OutputStream分配一定大小缓冲区,数据读写通过缓冲区完成。NIO概述
BIO方式,不管是网络还是磁盘,一旦有阻塞,线程都会失去CPU使用权。当需要大量HTTP长链接的情况,或者提升个别IO请求优先级,或者竞态资源同步,BIO处理起来会非常复杂,此时,NIO闪亮登场。显然,这个话题需要一个崭新的大篇幅来介绍,此处省略一万字=。=IO调优
- 磁盘IO优化 - 增加缓存,减少磁盘访问次数
- 优化磁盘管理系统,设计最优的磁盘寻址策略(太底层)
- 设计合理的磁盘存储数据块
- 应用合理的RAID策略提升磁盘IO
- TCP网络参数调优
- 32位系统通常只有65535个端口,0~1024受保护,查看可用端口数量,较少时可以通过更改tcp_fin_timeout位更小的值来快速释放。常用信息:
cat /proc/net/netstat :查看TCP统计信息
cat /proc/net/snmp :查看当前系统连接情况
netstat -s :查看网络统计信息
- 网络IO优化
- 减少网络交互次数
- 减少网络传输数据量大小
- 减少编码(重要,网络流是字节形式,字符转字节比较耗时,尽量以字节形式传输或提前转码)
- 同步和异步的选择(同步就是一个任务的完成需要依赖另外一个任务的完成)
- 阻塞与非阻塞的选择(阻塞就是CPU停下来等待一个慢的操作完成才接着完成其他的工作)
- 同步、异步、阻塞、非阻塞混搭组合(根据场景来选择)
IO涉及的设计模式
*以下高能,需要功底:*适配器模式,关键点:Adapter完成源到目标的适配,一般是继承源或持有源(构造器注入、方法注入等),实现目标接口。
装饰器模式,关键点:在不改变源的接口的情况下,进行功能扩展。io包InputStream各种装饰器(FilterInputStream、BufferedInputStream等)通过持有源(构造器注入)来完成功能扩展。
两者都对类进行了包装,两者的本质区别在于是否改变了源的接口。
I am a slow walker, but I never walk backwards.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号