使用 ONLINE 选项重建 SQL Server 索引
问题
随着时间的推移,我们数据库的正常运行时间要求越来越大,这意味着我们必须对数据库进行维护的停机时间越来越小。本技巧将介绍 SQL Server 2005 中引入的一项功能,该功能允许我们在重建索引时保持索引在线并可访问。
解决方案
SQL Server 在线索引重建背景信息
在我们讨论细节之前,我想提一下有关在线索引重建的一些事情。首先,我想确保您了解重建索引和重新组织索引之间的区别。本技巧将仅关注重建。如果您想了解有关这两种操作之间差异的更多信息,可以在此处阅读更多内容。其次,我们应该注意到,在 SQL Server 2005 中,索引重建的在线选项仅在企业版中可用,而在 SQL Server 2008 中,它在企业版、开发人员版和评估版中可用。最后,如果出现以下情况,此选项不可用:
- 该索引是 XML 索引
- 该索引是一个空间索引
- 索引位于本地临时表上
- 索引是聚集的并且表包含 LOB 数据库列
- 该索引不是聚集索引,并且索引本身包含 LOB 数据库列
SQL Server ALTER INDEX 语法
重建索引的语法非常简单,我们只需在ALTER INDEX命令中添加“WITH ONLINE=ON”子句即可。这里有几个例子。第一个重建表上的单个索引,第二个重建表上的所有索引。您可以在此处阅读有关重建索引的更多信息。
ALTER INDEX [IX_Test] ON [dbo].[Test] REBUILD WITH (ONLINE = ON); ALTER INDEX ALL ON [dbo].[Test] REBUILD WITH (ONLINE = ON);
SQL Server 联机与脱机索引重建的性能
为了测试在线重建索引的性能,我想使用一个相当大的表,因此重建至少需要一两分钟。我使用了一个包含大约 20,000,000 条记录的表和两个索引,一个聚集主键和一个非聚集单列索引。这是完整的表和索引定义。
CREATE TABLE [dbo].[Test] ( [PKID] [int] NOT NULL, [IndCol] [int] NOT NULL, [Col1] [int] NULL, [Col2] [int] NULL, [Col3] [datetime] NULL, [Col4] [varchar](1000) NULL, [Col5] [timestamp] NOT NULL, [Col6] [int] NULL, [Col7] [varchar](200) NULL, [Col8] [int] NULL, CONSTRAINT [PK_Test] PRIMARY KEY CLUSTERED ( [PKID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] CREATE NONCLUSTERED INDEX [IX_Test] ON [dbo].[Test] ( [IndCol] ASC WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] GO
对于此性能测试,我首先将传统的 OFFLINE 索引重建与使用 ONLINE 参数进行聚集和非聚集索引重建进行比较。此初始基线测试使用以下命令,并且在表上没有任何其他并发活动的情况下运行。
ALTER INDEX [PK_Test] ON [dbo].[Test] REBUILD WITH (ONLINE=ON) ALTER INDEX [IX_Text] ON [dbo].[Test] REBUILD WITH (ONLINE=ON) ALTER INDEX [PK_Test] ON [dbo].[Test] REBUILD WITH (ONLINE=OFF) ALTER INDEX [IX_Text] ON [dbo].[Test] REBUILD WITH (ONLINE=OFF)
请注意,每个命令都运行 5 次,并取每个指标的平均值。以下是测试结果:
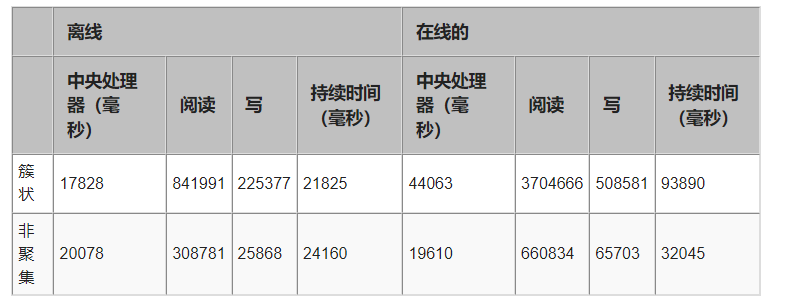
从这些结果中可以明显看出,在线索引重建的执行效果甚至不及在离线模式下运行时的执行效果,因为它使用更多的资源来完成重建。额外的读取和写入可归因于 SQL Server 在索引重建的初始阶段创建的索引的第二个副本。稍后会详细介绍这一点。
接下来,让我们看看在重建索引时表上有一些活动(插入/更新/选择)时会发生什么。为了在重建运行时模拟表上的活动,我打开了另外 3 个会话,每个会话每秒运行一个语句。其中一个运行简单的选择,一个运行插入,最后一个会话运行随机更新,每个语句将更新大约 600 条记录。这是该测试的结果。
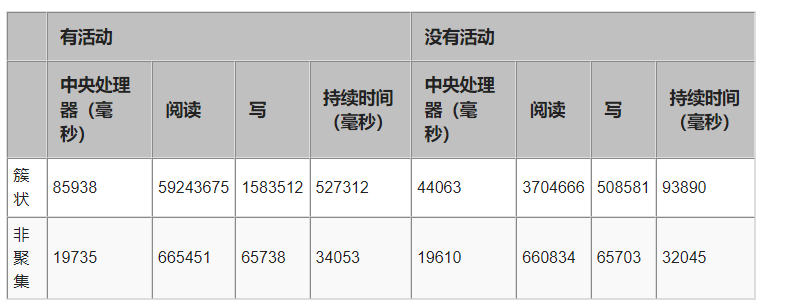
这些结果非常有趣。首先看看无聚集索引重建,我们发现它在表上的并发活动中仅使用了稍微多一点的资源。然而,聚集索引在表上的活动中使用更多的资源,完成时间几乎延长了 5 倍。这可能是因为在重建运行且其他进程正在访问表时,它基本上维护索引的两个副本(以及数据,因为它是聚集的)。
SQL Server 事务日志的使用
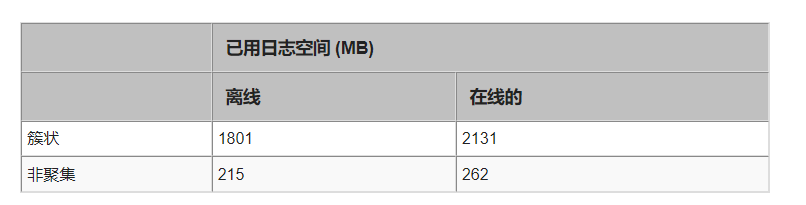
在启用 ONLINE 选项的情况下运行索引重建时要考虑的另一个因素是事务日志中所需的额外空间。为了查看使用了多少额外空间,我在重建命令之前进行了备份以清除日志。然后,我运行每个重建命令,并在每次重建之间进行另一个事务日志备份。以下是结果。您可以看到,在这两种情况下,无论是聚集索引还是无聚集索引,每个联机操作都会比正常的离线重建生成更多的重做。
SQL Server 联机索引重建期间需要额外的磁盘空间
第一个需要更多磁盘空间的地方是索引所在的数据文件。在联机重建的初始阶段,由于 SQL Server 创建索引快照,因此需要足够的空间来存储该索引的第二个副本。此外,对于聚集索引,会创建一个临时映射索引,用于在重建阶段原始索引发生更改时确定新索引中要修改的记录。一旦重建过程完成,该索引就会在最后阶段被删除。可以在此处找到对这些阶段的详细解释。tempdb 的版本存储部分还需要额外的空间。在在线重建期间,您可以查询sys.dm_db_file_space_usage DMV查看当前保留了多少页。在我的测试用例中,我发现在聚集索引重建期间版本存储需要大约 1880 个页面。该数字完全取决于重建期间表上活动的性质。我还注意到,对于没有聚集索引重建的情况,仅当您更新属于索引一部分的列时才会使用版本存储。如果我更新的列不属于正在重建的索引的一部分(如本技巧中的示例),则根本不使用版本存储。
通过 SQL Server 联机索引重建获取的 SQL Server 锁
此链接还准确显示了在线索引重建期间获取了哪些类型的锁。准备和构建阶段的锁 IS 和 S 主要是为了确保在重建索引时另一个进程不会获得该对象的排它锁。最后阶段获取的最后一个锁是 Sch-M 锁。此模式修改锁会阻止对表的所有其他并发访问,但它仅在旧索引被删除和元数据更新时保留很短的时间。
概括
从上面的测试中我们可以看到,与旧的离线索引重建相比,在线索引重建确实需要更多的资源,并且需要更长的时间才能完成。对于我们这些系统中有可用停机时间的人来说,在此窗口期间执行这些维护活动可能是一个更好的主意,但对于我们这些没有这种奢侈的人来说,在线索引重建是一个非常方便的功能。
下一步
 微信赞赏
微信赞赏

 支付宝赞赏
支付宝赞赏


 浙公网安备 33010602011771号
浙公网安备 33010602011771号