
RAC一个节点自动重启问题分析
题记:在RAC数据库的故障当中,节点重启的现象很常见,在这种问题的处理当中,有一定的规律性。为了更好的说明这个问题的处理过程,保证出现该类问题的时候,能够有序的进行处理,特编写此文档。
问题现象描述
此问题的现象比较明显,也就是数据库自动重启,或者是节点自动重启,客户端在数据库重启期间无法连接数据库,导致业务断连的现象。这种情况如果出现在业务高峰期间,将会对业务造成较大的影响,所有连接到重启节点的用户将断开,系统压力全部转移到健康节点,如果另外一个节点无法支撑较大压力的时候,那么业务将全部中断,因此,需要对此类问题进行重视,并理解此类问题的一个处理思路!
问题处理思路
遇到此类问题的发生,需要一个明确的思路,特别是当故障发生比较紧急时候,需要快速的定位故障原因,快速的解决问题。
(1)首先需要进行问题定位
通过命令检查操作系统的启动时间:Uptime
通过命令检查数据库启动的时间:
Select start_time from v$instance;
检查后台日志,看有没有实例重启的日志;
诊断节点重启问题是经常搜集的信息。
如果上述条件满足,那么可以确定和本文档相符,可继续往下处理。
(2)接下来我们讨论如何诊断节点重启问题。
-->由ocssd导致的节点重启。
如果在ocssd.log中出现以下错误,则表示节点重启是由于丢失网络心跳。接下来需要查看和网络相关的信息,如操作系统日志,OSW报表(traceroute的输出),以确定网络层面(cluster interconnect)是否存在问题,并确定最终的原因。

注意:如果在主节点的ocssd.log中出现以上信息的时间点要晚于节点的重启时间,则说明节点重启的原因不是丢失网络心跳。
如果ocssd.log中出现以下错误,则表示节点重启是由于丢失磁盘心跳。接下来需要查看操作系统日志,OSWatcher报告(iostat的输出),以确定i/o层面是否存在问题,并确定最终的原因。
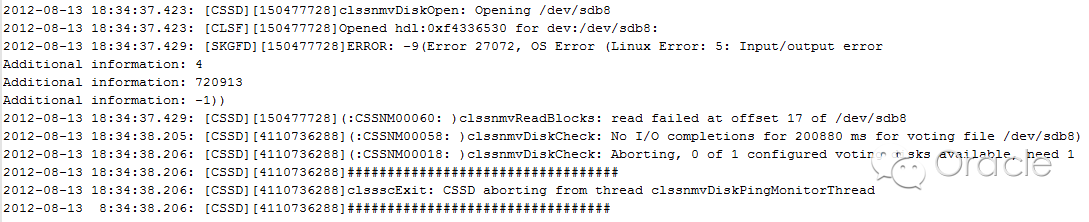
-->由oclsomon导致的节点重启。
如果在oclsomon.log 中出现错误,则表示节点重启是由于ocssd进程挂起,由于ocssd进程拥有实时(RT)优先级,很可能此时操作系统存在资源(如cpu)竞争,接下来需要察看操作系统日志,OSW报表(vmstat,top的输出),以确定最终的原因。
-->由oprocd导致的节点重启。
如果在oprocd日志中出现以下信息,则表明节点重启是由oprocd进程导致。
Dec 21 16:15:30.369857 | LASTGASP | AlarmHandler: timeout(2312msec) exceeds interval(1000 msec)+margin(500 msec). Rebooting NOW.
由于oprocd进程通过查看系统时间以确定操作系统是否挂起,正确的配置ntp(或其他时间同步软件),调整diagwait=13 可以避免节点重启,另外,如果需要大幅度修改系统时间,建议首先停止CRS,在修改完成之后再重新启动。当然,我们也不排除操作系统挂起导致oprocd重启节点,所以,也需要查看OSWatcher报告(vmstat,top的输出),以确定最终的原因。
-->由安装问题导致的节点重启。
Oracle数据库集群的安装,官方文档都已经详尽的说明了如何配置数据库,如何配置集群,如何配置主机,如何配置网络,需要哪些补丁。这些必需的条件如果在安装的过程中没有正确配置,也许在某一天的节点重启中,无法准确确定问题的起因的时候,它就是罪魁祸首。
相关理论知识介绍
首先我们对能够导致节点重启的CRS进程进行介绍:
1、ocssd : 它的主要功能是节点监控(Node Monitoring)和组管理(GroupManagement),它是CRS的核心进程之一。节点监控是指监控集群中节点的健康,监控的方法是通过网络心跳(network heartbeat)和磁盘心跳(disk heartbeat)实现的,如果集群中的节点连续丢失磁盘心跳或网络心跳,该节点就会被从集群中驱逐,也就是节点重启。组管理导致的节点重启,我们称之为node kill escalation(只有在11gR1以及以上版本适用),我们会在后面的文章进行详细介绍。重启需要在指定的时间(reboot time,一般为3秒)内完成。
-
网络心跳:ocssd.bin进程每秒钟向集群中的各个节点通过私网发送网络心跳信息,以确认各个节点是否正常。如果某个节点连续丢失网络心跳达到阀值,misscount(默认为30秒,如果存在其他集群管理软件则为600秒),集群会通过表决盘进行投票,使丢失网络心跳的节点被主节点驱逐出集群,即节点重启。如果集群只包含2个节点,则会出现脑裂,结果是节点号小的节点存活下来,即使是节点号小的节点存在网络问题。
-
磁盘心跳:ocssd.bin进程每秒钟都会向所有表决盘(Voting File)注册本节点的状态信息,这个过程叫做磁盘心跳。如果某个节点连续丢失磁盘心跳达到阀值,disk timeou(一般为200秒),则该节点会自动重启以保证集群的一致性。另外,CRS只要求[N/2]+1个表决盘可用即可,其中N为表决盘数量,一般为奇数。
2、oclsomon:这个进程负责监控ocssd是否挂起,如果发现ocssd.bin存在性能问题,则重启该节点。
3、oprocd:这个进程只在Linux和Unix系统,并且第三方集群管理软件未安装的情况下才会出现。如果它发现节点挂起,则重启该节点。
注意:以上的所有进程都是由脚本init.cssd产生的。
故障处理案例分析
经过数据库故障磨炼的兄弟都知道,数据库是一个综合体,它的每一次故障都涉及到方方面面,比如网络,系统,存储,应用等等。如果把数据库作为一个独立体处理,也许在故障处理的过程中,就失去了扩展的思维,把自己禁锢在某个点,而无法突破。只有把数据库看作一个整体,你才有那种众里寻他千百度,蓦然回首,却在灯火阑珊处的感觉!
这个时候,时间定格在2012年7月7日,这时候,突然电话铃响,紧急报障,某数据库节点一发生重启,故障就是命令,事不宜迟,登录数据库查看相关信息。
信息也比较明显:
[cssd(3539304)]CRS-1611:nodecs_02 (0) at 75% heartbeat fatal, eviction in 0.000 seconds
也就是心跳超时,导致节点重启。既然是心跳超时,那么有两种原因:一种原因是心跳磁盘无法连接,另一种是是心跳网络无法连接。首先去查证心跳磁盘有没有问题:
$ crsctl query css votedisk
0. 0 /dev/rvotedisk1
1. 0 /dev/rvotedisk2
2. 0 /dev/rvotedisk3
located 3 votedisk(s).
从这里可以看出,心跳磁盘正常访问,没有异常。那就是网络了,由于没有部署相关的网络监控软件,此时无法确定网络什么时候出了异常,断链情况如何,于是部署OSW软件,并且在后台部署长ping命令:
On Node1:
traceroute -s 192.168.65.234-r 192.168.65.235 1472
ping -s 1500 -c 2 -I192.168.65.234 192.168.65.234
ping -s 1500 -c 2 -I 192.168.65.234192.168.65.235
On Node2:
#traceroute -s 192.168.65.235-r 192.168.65.234 1472
ping -s 1500 -c 2 -I192.168.65.235 192.168.65.235
ping -s 1500 -c 2 -I192.168.65.235 192.168.65.234)
时间又在飞逝,系统不知道是不是知道我们布好了天罗地网,也不重启了,大家都以为相安无事,也渐渐淡忘,唯有我们数据库最后的保护者,还是一直在关注着,因为我们知道,这是我们的责任,这是DBA的一种执着的责任,对客户的负责,对数据库的负责。
终于这天来到了,2012年8月1日,这家伙终于不老实了,再次发生重启。我们有条不紊的进入数据库,按部就班的搬出我们的网,看看捕到了什么大鱼。首先,还是检查日志,和上次重启一样,是发生脑裂,剔除节点;然后检查系统层面,没有任何报错,排除硬件原因引起的重启;最后用我们部署的脚本,找到了相关的蛛丝马迹:
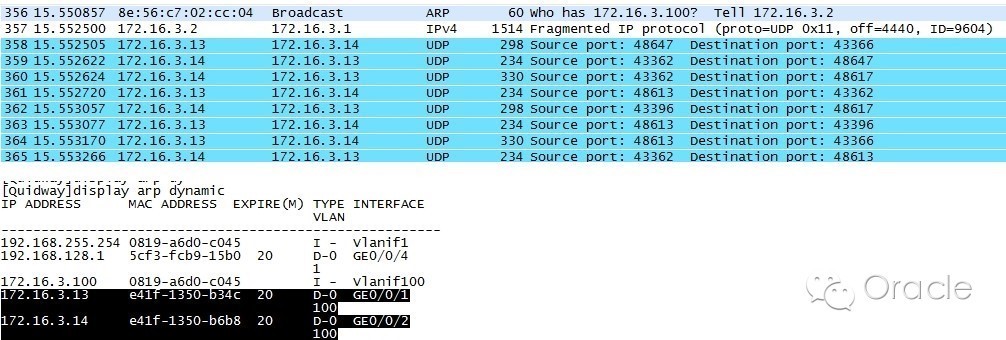
从这里我们可以看到,交换机的信息出现混乱,从末数据库的主机的端口接收到了其它IP的包信息。
查看OSW信息:
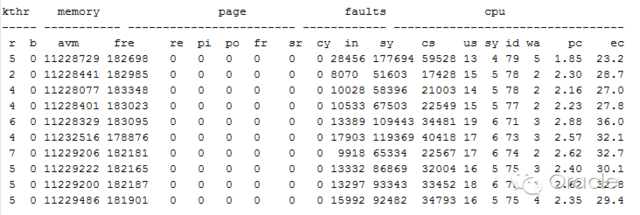
发现在故障期间,主机资源都算比较充足,因此可以排除由于主机负载引起的脑裂重启。
那会不会是系统或者是DRM配置的问题呢,因为在我们接触的案例中,有这种问题,于是进行相关整改:
通过关闭DRM设置,目前DRM是打开的;
oraclebug,Bug 5190596 LMON dumps LMS0 too often during DRM leading to IPC sendtimout
aix6.1没有打补丁,Block Lost or IPC Send Timeout PossibleWithout Fix of APAR IZ97457
整改完成后,数据库再次稳定,这个时候,时间已经到达2012年8月14日,很不幸的消息,从14日开始,连续发生多次重启,越来越频繁的重启,牵动着每一位参与此故障处理的同事们的心,就像是自己的孩子,一次又一次被人家欺负,而我们又只能远远看着。
时间来到8月20日,这段时间也经历了一个插曲,两个节点的操作系统版本竟然不一致,于是矛头也曾经指向了它,但是进行操作系统内核升级后,节点还是多次出现重启。终于,经过这么长时间的排查和摸索,最终将问题定位在网络上。有了大家一致认定的方向,剩下的就是排查了,首先指向的就是交换机,因为此交换机是多部主机共用,而且是同一个vlan,这在实际运用中,是比较大的隐患。
后续网络的同事发现原交换机配置错误,同一个IP段划分了2个VLAN,VLAN1用于某数据库系统,VLAN100用于某应用系统的心跳,导致数据包异常。(其实这个不是原因,当时网络同事想改了后,再换回来,想不通过换交换机的方式,但是我们坚持要换,所以才查出是交换机的问题,如果当时没换,改完之后还是有问题,估计又得折腾了,而且是折腾我们自己,遇到网络问题的时候,能最小化问题,就最小化问题)。从后面处理的过程就可以看出,后来重新换回交换机后,先后通过调整心跳交换机配置、停止IBM的DHCP server、恢复交换机出厂配置操作,问题依然没有解决,而且后续的日志也更有欺骗性:
2012-09-0701:34:08.928
[cssd(3539304)]CRS-1605:CSSDvoting file is online: /dev/rvotedisk1. Details in/u01/oracle/product/10.2/crs/log/cs_01/cssd/ocssd.log.
2012-09-0701:34:08.931
[cssd(3539304)]CRS-1605:CSSDvoting file is online: /dev/rvotedisk2. Details in/u01/oracle/product/10.2/crs/log/cs_01/cssd/ocssd.log.
更换交换机后,节点再没有重启,至此,耗时60天的主机重启问题,终于得到圆满的解决。
回顾整个故障的处理过程,走过了不少的弯路,从主机,存储,网络,数据库
各个层面进行了多层次的分析,一步一步的走近答案。在这个过程中,有着永不放弃精神,有着责任心,最终抽丝剥茧的找到了问题的最终答案。
后记
作为一个合格的DBA,必须拥有丰富的知识,冷静的头脑和解决问题的思路;
DBA这个职业并不像是圈外人士想象的就是钱多事少的职业;
DBA应该是这种状态,当你维护的数据库健康稳定的运作,当最终用户由衷的赞叹:这个查询真快的时候,我们会心的一笑;
作为一个DBA老兵,我们应该有那种心里的感觉,当处理完每一次故障的时候,蓦然回首的时候,它却在灯火阑珊处……
关于MCELOG的一点补充:
1.MCE(Machine Check Exception)是用来报告主机硬件相关问题的一种日志机制.
2.MCE(Machine Check Exception)的日志文件是/var/log/mcelog
3.该mcelog不一定在任何一台Linux主机上都存在.只有发生硬件报错了,才会有 /var/log/mcelog.
4.在/var/log/messages文件中,也可能有mce的一点痕迹.搜索关键字是mce
比如:
kernel: mce: [Hardware Error]: Machine check events logged
比如:
Jun 28 18:42:11 <hostname> mcelog: failed to prefill DIMM database from DMI data
-----根据工程经验:如上一行不代表硬件有问题
参考资料:
Oracle Linux: Hardware Error: Machine check Events Logged (文档 ID 2048885.1)
 微信赞赏
微信赞赏

 支付宝赞赏
支付宝赞赏





【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步