锁机制
1锁基础和优化。
(1)对象头mark
*对象头的标记,描述对象的hash,锁信息,垃圾回收标记,年龄等。包括指向锁记录的指针,指向monitor的指针,gc标记,偏向锁线程id。这部分数据的长度在32位和64位的虚拟机中分别为32bit和64bit,简称“Mark Word”
*对象头信息是与对象自身定义的数据无关的额外存储成本。它会根据对象的状态复用自己的存储空间。例如:在32位的HotSpot虚拟机中对象未被锁定的状态下,Mark Word的32bit空间中的25bit用于存储对象哈希(HashCode),4bit用于存储对象分代年龄,2bit用于存储锁标志位,1bit固定为0。
*如果对象是数组类型,则虚拟机用3个Word(字宽)存储对象头,如果对象是非数组类型,则用2Word存储对象头。下图是64位mark
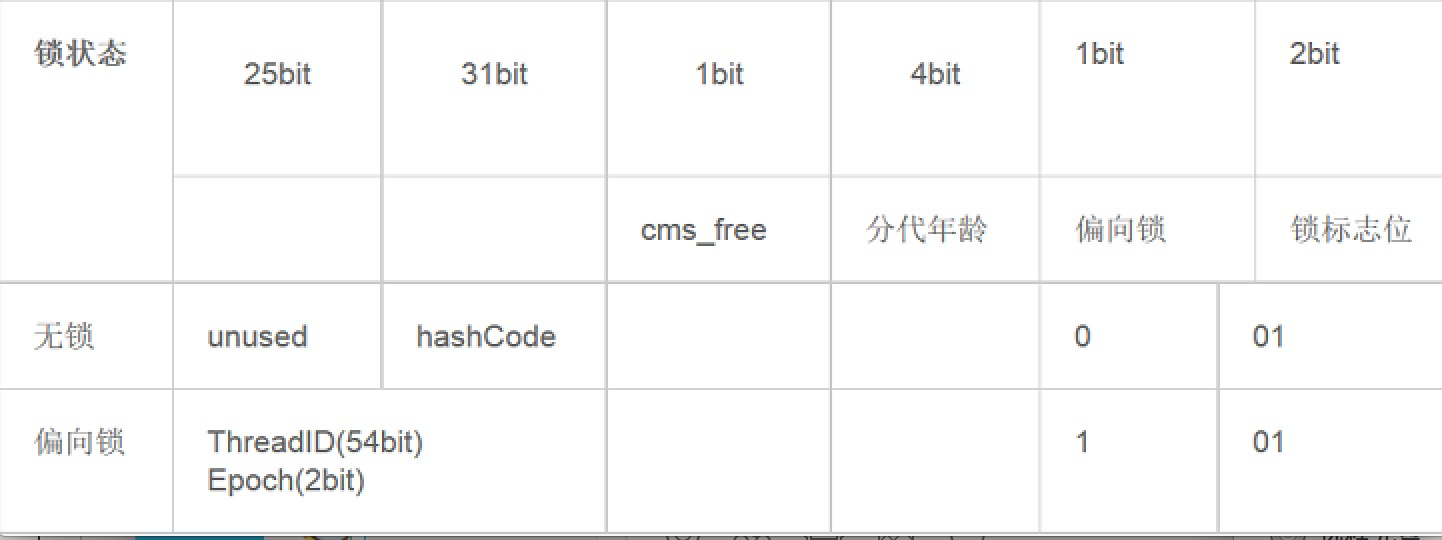
(2)偏向锁 jdk1.6引入,锁会偏向于当前已经占有锁的线程。因为普遍认为大部分情况没有竞争,通过偏向可以提高性能。偏向锁将对象头mark的标记设置为偏向,并将线程id写入对象头mark。如果没有竞争,获得偏向锁的线程在将来进入同步块时,不需要做同步。当其他线程请求相同的锁时,偏向模式结束。注意如果在竞争激烈的场合,偏向锁会增加系统负担。
意义:锁偏向于第一个获得它的线程。消除数据在无竞争情况下的同步原语,提高性能。如果在接下来的执行过程中,该锁没有被其他的线程获取,则持有偏向锁的线程将永远不需要再进行同步。
-XX:+UseBiasedLocking=true/false 启用/禁用偏向锁,默认偏向锁是开启的。
-XX:BiasedLockingStartupDelay=0 偏向锁启动延时。一般启动时jdk认为竞争不激烈,会延迟几秒再启动偏向锁。
(3)轻量级锁
BasicObjectLock 嵌入在线程栈中的对象,是一种快速的锁定方法。
如果对象没有被锁定,那么轻量级锁使用时会将对象头的mark指针保存到锁对象中,将对象头的轻量锁指针设置为指向锁的指针。线程栈里有指针指向对象头,对象头又指向线程栈的轻量级锁,形成一个互相引用的关系。所以只要判断对象头的指针是否指向某个线程栈,就知道对象是否加上轻量级锁。
*如果轻量级锁失败,表示存在竞争,则升级为重量级锁,即常规锁。竞争较少的情况下,轻量级锁可以减少使用操作系统互斥量产生的性能消耗;在竞争激烈时,轻量级锁的工作是白费的,相当于额外操作导致性能下降。
(4)自旋锁
当竞争存在时,如果线程可以很快获得锁,那么可以不在os层挂起线程,而是让线程自己做些空动作。
jdk1.6中,-XX:+UseSpinning开启自旋,1.7以后默认自旋。
如果同步块较长,则自旋失败,降低系统性能;同步较短则自旋成功,节省线程挂起时间,提升系统性能。
*偏向锁,轻量级锁,自旋锁 是jvm层面的锁优化方法,系统会先尝试偏向锁,若不可用则用轻量级锁,再不可用则自旋,如果再失败则升级到一般锁调用os资源。
*代码层面,应该尽量减少锁的时间,比如只锁部分代码;减少锁粒度,比如concurrentHashMap只对部分加锁(segment);
(5)锁分离
根据功能进行锁分离,是减少锁粒度的一种,典型例子是读写锁(readWriteLock),读多写少的情况可以提高性能。读锁可重入,写锁读写都独占。
* linkedBlockingQueue 是个链表队列,同时有take和put两种操作,可以进行锁分离,take和push有单独的锁,可以提高性能。
(6)锁粗化
正常情况下,系统要求每个线程持有锁的时间尽量短,尽快释放资源,其他线程尽早得资源;但是如果对锁请求太频繁,请求同步释放等过程会消耗过多系统资源。例如,两个同步块之间的代码时间较短,jdk会把两个同步块连同中间代码合成一个同步块,避免反复请求资源;或者for循环内部加锁,会优化成直接锁for循环。
(7)锁消除
jvm在编译时,如果发现不可能被共享的对象,则可以擦除不起作用的锁。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号