selenium爬虫报错:Message: stale element reference: element is not attached to the page document 促成1分钟爬完斗鱼主播信息。
先看代码
#-*- coding:utf-8 -*- #_author:John #date:2018/10/16 19:05 #softwave: PyCharm import lxml from bs4 import BeautifulSoup from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.wait import WebDriverWait boswer = webdriver.Chrome() wait = WebDriverWait(boswer, 10) url = 'https://www.douyu.com/directory/all' boswer.get(url) f = open('F:\douyu.txt', 'w', encoding='utf-8') i = 0 while True: html = boswer.page_source soup = BeautifulSoup(html, 'lxml') soup_titles = soup.select('.ellipsis') soup_nums = soup.select('.dy-num.fr') for soup_title, soup_num in zip(soup_titles, soup_nums): title = soup_title.get_text().replace('\n', '').strip() num = soup_num.get_text() print('标题:{} | 人气:{}'.format(title, num)) f.write(title) f.write(num) i += 1 print('*'*25 + '\n'+ '第 {} 页爬取成功'.format(i)+ '\n'+'*'*25 ) # 等待下一页是可点击状态 next_page = wait.until( EC.element_to_be_clickable((By.CLASS_NAME,"shark-pager-next")) ) # 获取最后一页 end_page = boswer.find_element_by_xpath("//a[@class='shark-pager-item'][last()]").text if i == int(end_page): break next_page.click() # 等待当前页码为下一页,证明已经执行了翻页 wait.until( EC.text_to_be_present_in_element((By.CSS_SELECTOR,".shark-pager-item.current"), str(i+1)) ) boswer.close() f.close()
执行后只爬了两页就报错误:
Traceback (most recent call last): File "C:/Users/yao/PycharmProjects/test20181003/test1016.py", line 38, in <module> next_page.click() File "C:\Users\yao\PycharmProjects\test20181003\venv\lib\site-packages\selenium\webdriver\remote\webelement.py", line 80, in click self._execute(Command.CLICK_ELEMENT) File "C:\Users\yao\PycharmProjects\test20181003\venv\lib\site-packages\selenium\webdriver\remote\webelement.py", line 633, in _execute return self._parent.execute(command, params) File "C:\Users\yao\PycharmProjects\test20181003\venv\lib\site-packages\selenium\webdriver\remote\webdriver.py", line 321, in execute self.error_handler.check_response(response) File "C:\Users\yao\PycharmProjects\test20181003\venv\lib\site-packages\selenium\webdriver\remote\errorhandler.py", line 242, in check_response raise exception_class(message, screen, stacktrace) selenium.common.exceptions.StaleElementReferenceException: Message: stale element reference: element is not attached to the page document (Session info: chrome=71.0.3559.6) (Driver info: chromedriver=70.0.3538.16 (16ed95b41bb05e565b11fb66ac33c660b721f778),platform=Windows NT 10.0.17134 x86_64)
这样的错误是说我已经点击了翻页,但是还没有完成翻页,于是又爬了一次当前页,然后再要执行翻页时页面已经刷新了,前面找到的翻页元素已经过期了,无法执行点击。
当然最有效的方法是在点击翻页后强制sleep几秒,但是这样会浪费时间,而且太low了。于是我加了等待当前页为下一页的功能仍然无效,于是尝试翻页后再等待下一页是可点击状态。
#-*- coding:utf-8 -*- #_author:John #date:2018/10/16 19:05 #softwave: PyCharm import lxml from bs4 import BeautifulSoup from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.wait import WebDriverWait boswer = webdriver.Chrome() wait = WebDriverWait(boswer, 10) url = 'https://www.douyu.com/directory/all' boswer.get(url) f = open('F:\douyu.txt', 'w', encoding='utf-8') i = 0 while True: html = boswer.page_source soup = BeautifulSoup(html, 'lxml') soup_titles = soup.select('.ellipsis') soup_nums = soup.select('.dy-num.fr') for soup_title, soup_num in zip(soup_titles, soup_nums): title = soup_title.get_text().replace('\n', '').strip() num = soup_num.get_text() print('标题:{} | 人气:{}'.format(title, num)) f.write(title) f.write(num) i += 1 print('*'*25 + '\n'+ '第 {} 页爬取成功'.format(i)+ '\n'+'*'*25 ) # 等待下一页是可点击状态 next_page = wait.until( EC.element_to_be_clickable((By.CLASS_NAME,"shark-pager-next")) ) # 获取最后一页 end_page = boswer.find_element_by_xpath("//a[@class='shark-pager-item'][last()]").text if i == int(end_page): break next_page.click() # 等待当前页码为下一页,证明已经执行了翻页 wait.until( EC.text_to_be_present_in_element((By.CSS_SELECTOR,".shark-pager-item.current"), str(i+1)) ) # 再等待下页为可点击状态确保页面完成刷新 wait.until( EC.element_to_be_clickable((By.CLASS_NAME, "shark-pager-next")) ) boswer.close() f.close()
看着刷刷地翻了20页以为大功告成了,却在21页又挂掉了。于是我手动点击了下一页试试,当前页瞬间跳到下一页,下一页可点击也只是稍晚一点,并不能完全证明页面已经完成刷新了。
后面再几经折腾,用了异常处理,遇到失效再sleep 1s重新获取下一页元素,可以重试3次。
#-*- coding:utf-8 -*- #_author:John #date:2018/10/16 19:05 #softwave: PyCharm import lxml import time from bs4 import BeautifulSoup from selenium import webdriver from selenium.common.exceptions import StaleElementReferenceException from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.wait import WebDriverWait boswer = webdriver.Chrome() wait = WebDriverWait(boswer, 10) url = 'https://www.douyu.com/directory/all' boswer.get(url) f = open('F:\douyu.txt', 'w', encoding='utf-8') i = 0 while True: html = boswer.page_source soup = BeautifulSoup(html, 'lxml') soup_titles = soup.select('.ellipsis') soup_nums = soup.select('.dy-num.fr') for soup_title, soup_num in zip(soup_titles, soup_nums): title = soup_title.get_text().replace('\n', '').strip() num = soup_num.get_text() print('标题:{} | 人气:{}'.format(title, num)) f.write(title) f.write(num) i += 1 print('*'*25 + '\n'+ '第 {} 页爬取成功'.format(i)+ '\n'+'*'*25 ) # 等待下一页是可点击状态 if boswer.page_source.find("shark-pager-disable-next") != -1: break # 尝试3次获取下一页,如果遇到失效就等待1s重新获取下一页元素 for _ in range(3): try: next_page = wait.until( EC.element_to_be_clickable((By.CLASS_NAME, "shark-pager-next")) ) next_page.click() break except StaleElementReferenceException: time.sleep(1) print('try to find element click') # 等待当前页码为下一页,证明已经执行了翻页 # wait.until( # EC.text_to_be_present_in_element((By.CSS_SELECTOR,".shark-pager-item.current"), str(i+1)) # ) # 再等待下页为可点击状态确保页面完成刷新 # wait.until( # EC.element_to_be_clickable((By.CLASS_NAME, "shark-pager-next")) # ) # time.sleep(0.5) boswer.close() f.close()
这样一来确实没有再挂掉了,但是会出现重复爬同一页的情况。无奈只能按low的方法强制sleep了,再想想既然已经选择了selenium就已经预料到它已经是牺牲了速度来得到的一个简易的翻页方法,如果说对爬虫速度确实有要求的话就需要抓包分析,放弃selenium了。
以下是最终用selenium完成的爬虫,经过一番折腾还是强制sleep 2s了。
#-*- coding:utf-8 -*- #_author:John #date:2018/10/16 19:05 #softwave: PyCharm import lxml import time from bs4 import BeautifulSoup from selenium import webdriver from selenium.common.exceptions import StaleElementReferenceException from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.wait import WebDriverWait boswer = webdriver.Chrome() wait = WebDriverWait(boswer, 10) url = 'https://www.douyu.com/directory/all' boswer.get(url) f = open('F:\douyu.txt', 'w', encoding='utf-8') i = 0 while True: html = boswer.page_source soup = BeautifulSoup(html, 'lxml') soup_titles = soup.select('.ellipsis') soup_nums = soup.select('.dy-num.fr') for soup_title, soup_num in zip(soup_titles, soup_nums): title = soup_title.get_text().replace('\n', '').strip() num = soup_num.get_text() print('标题:{} | 人气:{}'.format(title, num)) f.write(title) f.write(num) i += 1 print('*'*25 + '\n'+ '第 {} 页爬取成功'.format(i)+ '\n'+'*'*25 ) # 最后做出的妥协,延时长短根据网速而定 time.sleep(2) # 等待下一页是可点击状态 if boswer.page_source.find("shark-pager-disable-next") != -1: break # 尝试3次获取下一页,如果遇到失效就等待1s重新获取下一页元素 for _ in range(3): try: next_page = wait.until( EC.element_to_be_clickable((By.CLASS_NAME, "shark-pager-next")) ) next_page.click() break except StaleElementReferenceException: time.sleep(1) print('try to find element click') # 等待当前页码为下一页,证明已经执行了翻页 # wait.until( # EC.text_to_be_present_in_element((By.CSS_SELECTOR,".shark-pager-item.current"), str(i+1)) # ) # 再等待下页为可点击状态确保页面完成刷新 # wait.until( # EC.element_to_be_clickable((By.CLASS_NAME, "shark-pager-next")) # ) # time.sleep(0.5) boswer.close() f.close()
用selenium折腾了很久,还是不甘心,想看看通过网页抓包方法试试,于是意外的发现这个URL带有页码的,那后面似乎就很简单了。
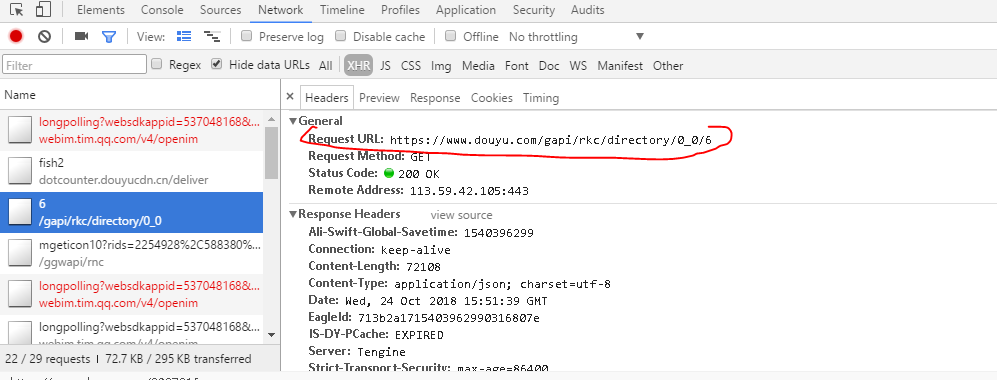

进入这个带页码的url得到这样一个网页就可以用json.load变成字典取出来想要的东西。直接多进程循环200页,这效率不谈了,不到1分钟瞬间完成!
#-*- coding:utf-8 -*- #_author:John #date:2018/10/25 0:07 #softwave: PyCharm import requests import json from multiprocessing import Pool import pymongo client = pymongo.MongoClient('localhost') db = client['douyu'] def single_page_info(page): respones = requests.get('https://www.douyu.com/gapi/rkc/directory/0_0/{}'.format(page)) datas = json.loads(respones.text) items = datas['data']['rl'] for item in items: data = { '标题': item['rn'], '主播': item['nn'], '人气' : item['ol'], } print(data) db['ajax_spider'].insert(data) print('已经完成第{}页'.format(page)) if __name__ == '__main__': pool = Pool() # 多线程抓200页 pool.map(single_page_info, [page for page in range(1,200)])
更改一下,找到更多的信息,并且不保存重复数据。
#-*- coding:utf-8 -*- #_author:John #date:2018/10/25 0:07 #softwave: PyCharm import requests import json from multiprocessing import Pool import pymongo import datetime client = pymongo.MongoClient('localhost') db = client['douyu'] cur_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M') def single_page_info(page): respones = requests.get('https://www.douyu.com/gapi/rkc/directory/0_0/{}'.format(page)) datas = json.loads(respones.text) items = datas['data']['rl'] for item in items: data = { '标题': item['rn'], '主播': item['nn'], '人气': item['ol'], '类别': item['c2name'], '房间号': item['rid'], '时间': cur_time } # 不保存相同时间相同主播名的记录 if db['host_info'].update({'主播': data['主播'], '时间': data['时间']}, {'$set': data}, True): print('Save to Mongo, {}'.format(data)) else: print('Save to Mong fail, {}'.format(data)) print('已经完成第{}页'.format(page)) if __name__ == '__main__': pool = Pool() #多线程抓200页 pool.map(single_page_info, [page for page in range(1, 201)])
运行完就可以到Mongdb里面筛选想要的数据了,比如按类别,按人气,按时间等key_work查找数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号