用pyspider爬斗鱼主播信息
之前用request+bs4+Mongodb爬斗鱼主播信息,需要自己写很长一大段, 现在用pyspider试试。开始安装pyspider。
python3.7还不支持,3.6版本直接pip install pyspider就好了。
浏览器输入http://localhost:5000

Creaet按钮创建新项目,并输入起始网址,这里选择斗鱼分类网址,在这里爬出所有类目。
三个步骤:
1.起始页(获取下个操作步骤的url)
2.得到的url下(爬取信息)
3.save_to_mongo(存入数据库)
#!/usr/bin/env python # -*- encoding: utf-8 -*- # Created on 2018-10-23 21:01:23 # Project: douyu from pyspider.libs.base_handler import * import pymongo class Handler(BaseHandler): crawl_config = { } client = pymongo.MongoClient('localhost') db = client['spider_douyu'] @every(minutes=24 * 60) def on_start(self): self.crawl('https://www.douyu.com/directory', callback=self.index_page, validate_cert=False) @config(age=10 * 24 * 60 * 60) def index_page(self, response): # 在浏览器里面获取的选择器 for each in response.doc('#live-list-contentbox a[href^="http"]').items(): self.crawl(each.attr.href, callback=self.detail_page, validate_cert=False) @config(priority=2) def detail_page(self, response): host_names = response.doc('.ellipsis.fl').items() nums = response.doc('.dy-num.fr').items() titles = response.doc('.mes h3').items() urls = response.doc('#live-list-contentbox li a').items() for host_name, num, title, url in zip(host_names,nums,titles,urls): data = { "网址": 'https://www.douyu.com/' + url.attr.href, "主播": host_name.text(), "标题": title.text().split('\n')[-1].strip(), "人气": float(num.text()[:-1]) if '万'in num.text() else float(num.text())/10000, } self.db['host'].insert(data)
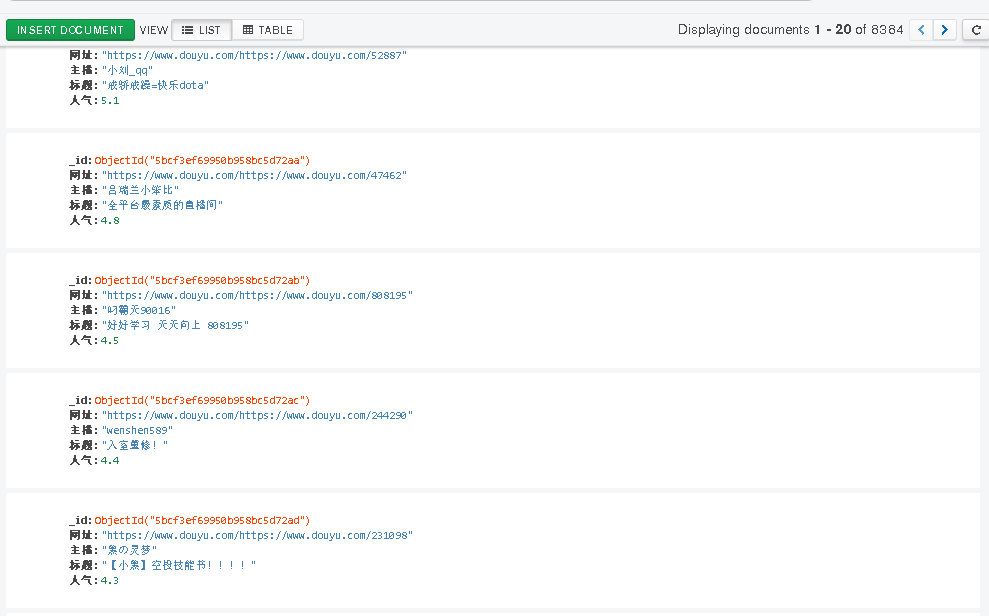
运行后的结果:

几分钟爬到了8000条信息
代码短了很多,简洁了很多,还不用自己写进程池。下一步尝试进入主播房间获取贵族人数,礼物排行等更详细的信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号