
曼城新闻情报站(一)爬取3大网站的曼城新闻
想完成一个Django框架的爬虫,将曼城的新闻内容爬到并放入数据库,然后通过Django框架用网页显示出来。现在第一步是爬新浪、网易、腾讯的曼城新闻内容并放入Mongodb中。本来搜狐也是一个计划中的门户网站,但是爬出来的内容中文不能正常显示,不像是编码的问题,于是就直接跳过了。
这个程序关键的地方是新浪和网易的球队新闻都是js动态显示的,新浪还是json格式的网页,要找到真正的目的网页还是费了一些周章的。由于新闻具有时效性,所以只抓了首页的新闻内容,避开了逐个翻页的麻烦。
来看看网易的真实网址。查看元素,选JS,然后鼠标指到曼城可以看到多了个js地址,点进去找到URL打开。
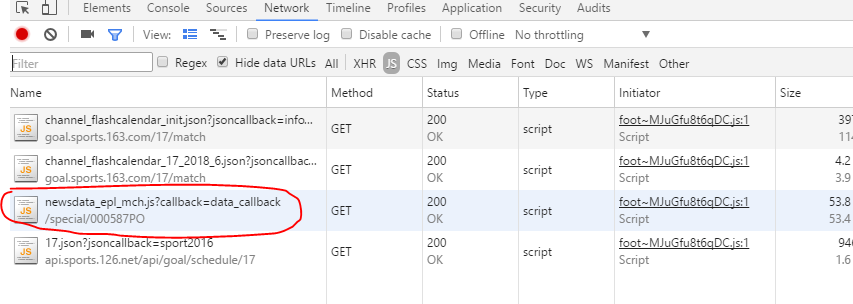
这样的网页内容看似一个字典的样子,但我没找到简单的方法把想要的数据取出来,直接用的正而表达式取数据。

新浪的方法一样,不过新浪用的js翻页,用正则取出了一个json文件,再抓数据。
现在上代码
#-*- coding:utf-8 -*- #_author:John #date:2018/9/10 19:37 #softwave: PyCharm from bs4 import BeautifulSoup from datetime import datetime import requests import re, json import pymongo class Man_City(): def __init__(self): self.header = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36', 'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8', } def news_man(self): #这是js动态生成的页面,需要找到对应的js网页,再用正则表达式找到所需内容 man_163_url = 'http://sports.163.com/special/000587PO/newsdata_epl_mch.js?callback=data_callback' man_163_data = requests.get(man_163_url, headers=self.header) man_163_soup = BeautifulSoup(man_163_data.text, 'lxml').get_text() title_re = re.compile('title\":\"(.*?)\",') url_re = re.compile('docurl\":\"(.*?)\",') tienum_re = re.compile('tienum\":(\d+),') pub_date_re = re.compile('time\":\"(.*?)\",') titles = title_re.findall(man_163_soup) urls = url_re.findall(man_163_soup) tienums = tienum_re.findall(man_163_soup) pub_dates = pub_date_re.findall(man_163_soup) for title, url, tienum, pub_date in zip(titles, urls, tienums, pub_dates): data = { 'title': title, 'url': url, # 'tienum': tienum, #将字符串的时间转换成时间模式再传入数据库,以便之后以时间进行排序 'pub_date': datetime.strftime(datetime.strptime(pub_date, '%m/%d/%Y %H:%M:%S'), '%Y-%m-%d %H:%M:%S') } print(data) self.add_to_mongodb(db_name='163', data=data) def sina_man_news(self): #跟163一样先找到真正的网页,得到的是一个json格式的页面,转换一下再取内容 url = 'http://interface.sina.cn/pc_zt_api/pc_zt_press_news_doc.d.json?subjectID=68265&cat=&size=40&page=1&channel=sports&callback=jsonpcallback1536942563301' data_get = requests.get(url, headers= self.header) #获取的网页内容大括号里面的是json数据,用正则表达式获取大括号里面的内容得到json格式数据 data_re = re.compile('\((.*?)\)') soup_data = data_re.findall(data_get.text)[0] soup = json.loads(soup_data) for i in soup['result']['data']: # 观察发现日期是放在url中的,把日期分离出来 pub_date_soup = i['url'].split('/')[-2] data = { 'title': i['title'], 'url': i['url'], #转换时间格式 'pub_date':datetime.strftime(datetime.strptime(pub_date_soup, '%Y-%m-%d'), '%Y-%m-%d') } print(data) self.add_to_mongodb(db_name='sina', data=data) def qq_man_news(self): #腾讯里面的曼城新闻没有用js生成,是静态的网页,直接用bs4获取 url='http://sports.qq.com/premierleague/' data_get=requests.get(url, headers=self.header) soup = BeautifulSoup(data_get.text, 'lxml') titels = soup.select('.newsul.newsCont3 .news_txt a') for i in titels: # 跟新浪一样的,日期包含在url中 pub_date_soup = i.get('href').split('/')[-2] data = { 'title': i.get_text(), 'url': 'http://sports.qq.com/'+ i.get('href'), #转换时间格式 'pub_date':datetime.strftime(datetime.strptime(pub_date_soup, '%Y%m%d'), '%Y-%m-%d') } self.add_to_mongodb(db_name='qq', data=data) print(data) def add_to_mongodb(self, db_name, data): #分别命名存入数据库 client = pymongo.MongoClient('localhost', 27017) Man_City = client['Man_City'] db_name = Man_City[db_name] #用日期倒序排列,取出60个标题放到列表,如果新获取的数据标题不在这60个标题列表中就加入数据库中,避免同一个新闻多次存入数据库 pipeline= [ {'$sort':{'pub_date':-1}}, {'$limit':60,}, ] titel_list = [db['title'] for db in db_name.aggregate(pipeline)] if data['title'] not in titel_list: db_name.insert_one(data) if __name__ == '__main__': M = Man_City() M.news_man() M.sina_man_news() M.qq_man_news() # M.add_to_mongodb(db_name='sina')
为了后面按新闻日期排序,所以在把数据存入数据库前把新闻日期一栏全部转换成了日期格式。存入数据库前取最近存入的60条新闻来比对获得的新闻是不是已经在数据库中了,避免多次存入同一条新闻。
最后的成果如下
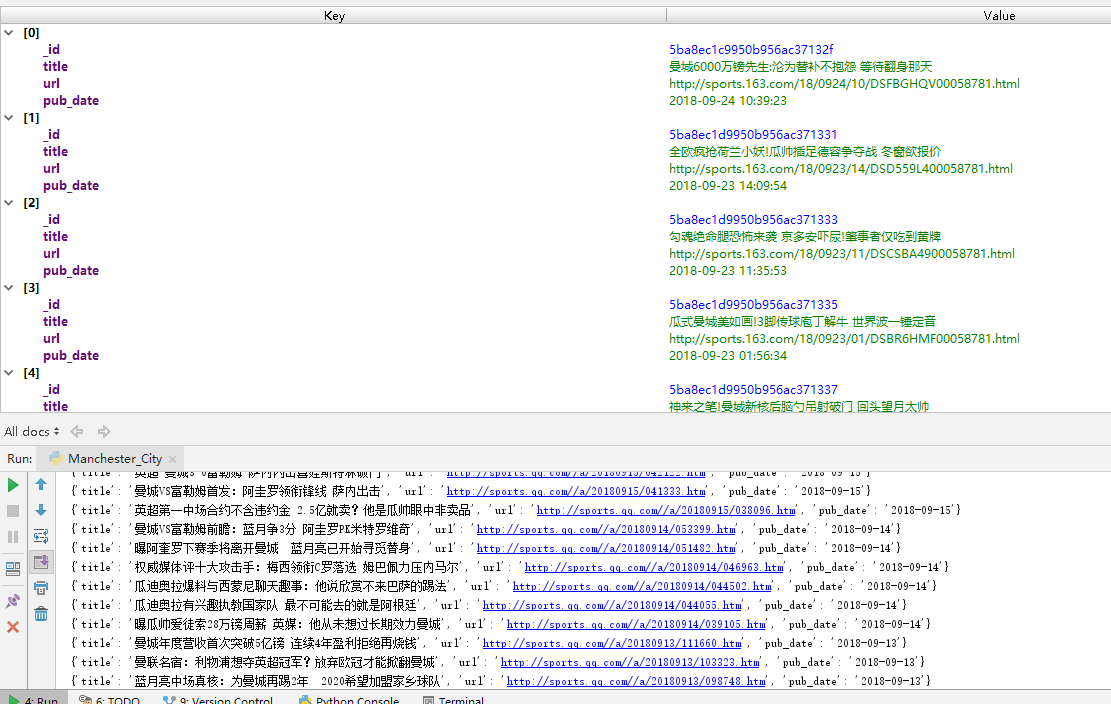
现在只是完成了获取数据的第一步,后面还需要用到Django框架,把获取到的数据在网页中显示出来。

