
redis操作
一、连接池
redis-py使用connection pool来管理对一个redis server的所有连接,避免每次建立、释放连接的开销。默认,每个Redis实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为参数Redis,这样就可以实现多个Redis实例共享一个连接池。
import redis
pool = redis.ConnectionPool(host='localhost',port=6379)r = redis.Redis(connection_pool=pool)r.set('name2','alex')print(r.get('name2'))
安装:redis-server --service-install redis.windows.conf
卸载:redis-server --service-uninstall
启动:redis-server --service-start
停止:redis-server --service-stop
二、str操作
redis中的String在在内存中按照一个name对应一个value来存储。
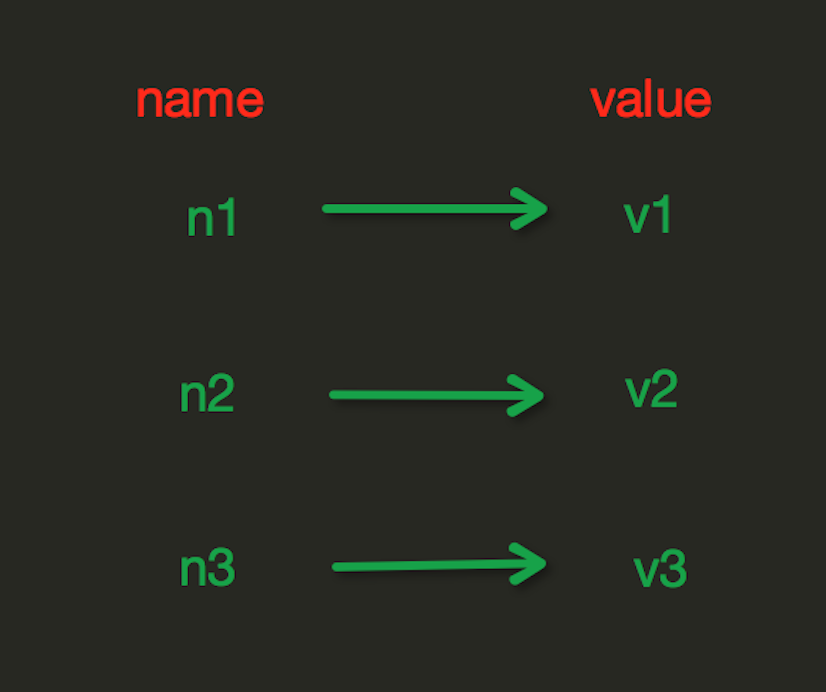
set(name, value)
例子:设置key为k1,值为1的一个键值对
set k1 1
在Redis中设置值,默认,不存在则创建,存在则修改
expire key seconds
给key设置过期时间
setnx(name, value)
例子:
127.0.0.1:6379[7]> setnx kk 2
(integer) 1
127.0.0.1:6379[7]> get kk
"2"
设置值,只有name不存在时,执行设置操作(添加)
setex(name, time, value)
# 设置值
# 参数:
# time,过期时间(数字秒 或 timedelta对象)
例子:
127.0.0.1:6379[7]> setex kk 30 22
OK
127.0.0.1:6379[7]> get kk
"22"
psetex(name, time_ms, value)
# 设置值
# 参数:
# time_ms,过期时间(数字毫秒 或 timedelta对象)
mset(*args, **kwargs)
批量设置值
如:
mset(k1='v1', k2='v2')
或
mget({'k1': 'v1', 'k2': 'v2'})
例子:
存(设置):mset k1 1 k2 2k k3 3 k4 8
取: mget k1 k2 k3
127.0.0.1:6379[7]> mset k1 1 k2 2k k3 3 k4 8
OK
127.0.0.1:6379[7]> mget k1 k2 k3
1) "1"
2) "2k"
3) "3"
get(name)
获取值
get name
mget(keys, *args)
批量获取
getset(name, value)
设置新值并获取原来的值
getrange(key, start, end)
# 获取子序列(根据字节获取,非字符)
# 参数:
# name,Redis 的 name
# start,起始位置(字节)(索引开始的下标)
# end,结束位置(字节)(索引结束的下标)
闭区间
# 如: "wusir" ,0-3表示 "wusi"
setrange(name, offset, value)
# 修改字符串内容,从指定字符串索引开始向后替换(新值太长时,则向后添加)
# 参数:
# offset,字符串的索引,字节(一个汉字三个字节)
# value,要设置的值
(去看菜鸟教程)
setbit(name, offset, value)

# 对name对应值的二进制表示的位进行操作
# 参数:
# name,redis的name
# offset,位的索引(将值变换成二进制后再进行索引)
# value,值只能是 1 或 0
# 注:如果在Redis中有一个对应: n1 = "foo",
那么字符串foo的二进制表示为:01100110 01101111 01101111
所以,如果执行 setbit('n1', 7, 1),则就会将第7位设置为1,
那么最终二进制则变成 01100111 01101111 01101111,即:"goo"
特别的,如果source是汉字,对于utf-8,每一个汉字占 3 个字节,那么 "博客园" 则有 9个字节
对于汉字,for循环时候会按照 字节 迭代,那么在迭代时,将每一个字节转换 十进制数,然后再将十进制数转换成二进制
getbit(name, offset)
# 获取name对应的值的二进制表示中的某位的值 (0或1)
bitcount(key, start=None, end=None)
# 获取name对应的值的二进制表示中 1 的个数
# 参数:
# key,Redis的name
# start,位起始位置
# end,位结束位置
strlen(name)
# 返回name对应值的字节长度(一个汉字3个字节)
append(key, value)
# 在redis name对应的值后面追加内容
# 参数:
key, redis的name
value, 要追加的字符串
三、hash操作
hash表现形式上有些像pyhton中的dict,可以存储一组关联性较强的数据 , redis中Hash在内存中的存储格式如下图:

hset(name, key, value)
# name对应的hash中设置一个键值对(不存在,则创建;否则,修改)
# 参数:
# name,redis的name
# key,name对应的hash中的key
# value,name对应的hash中的value
# 注:
# hsetnx(name, key, value),当name对应的hash中不存在当前key时则创建(相当于添加)
例子:
127.0.0.1:6379[7]> hmset python1806 name1 xukai name2 wangsheng name3 wujun
OK
127.0.0.1:6379[7]> hmget python1806 name1
1) "xukai"
127.0.0.1:6379[7]> hmget python1806 name1 name2 name3
1) "xukai"
2) "wangsheng"
3) "wujun"
hmset(name, mapping)
# 在name对应的hash中批量设置键值对
# 参数:
# name,redis的name
# mapping,字典,如:{'k1':'v1', 'k2': 'v2'}
# 如:
# r.hmset('xx', {'k1':'v1', 'k2': 'v2'})
hget(name,key)
# 在name对应的hash中获取根据key获取value
hmget(name, keys, *args)
# 在name对应的hash中获取多个key的值
# 参数:
# name,reids对应的name
# keys,要获取key集合,如:['k1', 'k2', 'k3']
# *args,要获取的key,如:k1,k2,k3
# 如:
# r.mget('xx', ['k1', 'k2'])
# 或
# print r.hmget('xx', 'k1', 'k2')
hgetall(name)
获取name对应hash的所有键和值
例子:
127.0.0.1:6379[7]> hgetall python1806
1) "name"
2) "wujun"
3) "name1"
4) "xukai"
5) "name2"
6) "wangsheng"
7) "name3"
8) "wujun"
hlen(name)
# 获取name对应的hash中键值对的个数
例子:
127.0.0.1:6379[7]> hlen python1806
(integer) 4
hkeys(name)
# 获取name对应的hash中所有的key的值
例子:
127.0.0.1:6379[7]> hkeys python1806
1) "name"
2) "name1"
3) "name2"
4) "name3"
hvals(name)
# 获取name对应的hash中所有的value的值
例子:
127.0.0.1:6379[7]> hvals python1806
1) "wujun"
2) "xukai"
3) "wangsheng"
4) "wujun"
hdel(name,*keys)
# 将name对应的hash中指定key的键值对删除
例子:
删
127.0.0.1:6379[7]> hdel python1806 name name1
(integer) 2
查询所有key value
127.0.0.1:6379[7]> hgetall python1806
1) "name2"
2) "wanglin"
3) "name3"
4) "wuzhengjun"
查看值父级长度
127.0.0.1:6379[7]> hlen python1806
(integer) 2
查看存在的总个数
127.0.0.1:6379[7]> exists python1806 name name1 name2 name3
(integer) 2
四、list操作
List操作,redis中的List在在内存中按照一个name对应一个List来存储。如图:
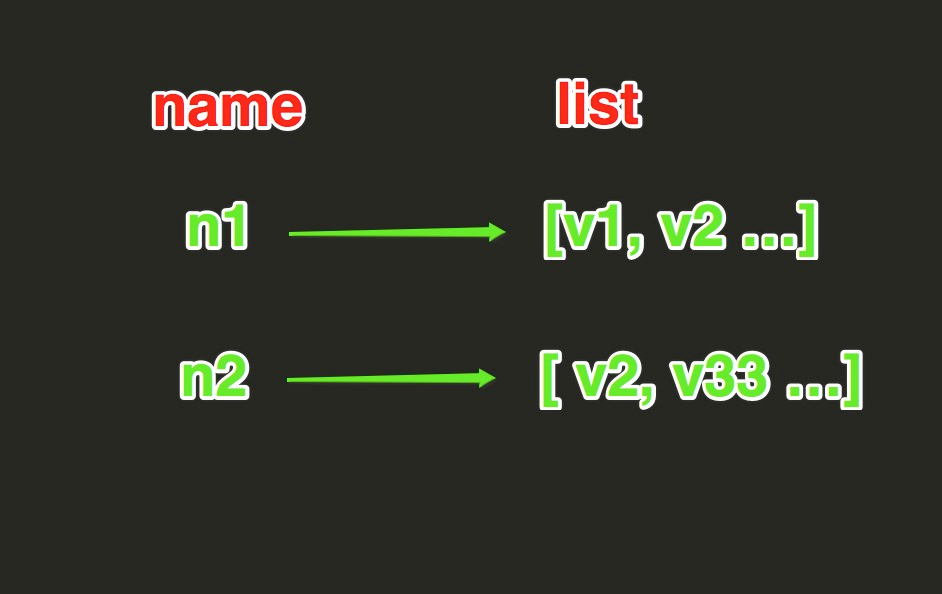
lpush(name,values)
# 在name对应的list中添加元素,每个新的元素都添加到列表的最左边
# 如:
# r.lpush('oo', 11,22,33)
# 保存顺序为: 33,22,11
# 扩展:
# rpush(name, values) 表示从右向左操作
例子:
存值:
lpush h5 zhangsan lisi wanger zhaoliu
(integer)
取值:
1.取单个值 :
127.0.0.1:6379[7]> lindex h5 2
"lisi"
2.取多个值:
127.0.0.1:6379[7]> lrange h5 0 -1
1) "zhaoliu"
2) "wanger"
3) "lisi"
4) "zhangsan"
5) "zhaoliu"
6) "wanger"
7) "lisi"
8) "zhangsan"
llen(name)
# name对应的list元素的个数
linsert(name, where, refvalue, value))
# 在name对应的列表的某一个值前或后插入一个新值
# 参数:
# name,redis的name
# where,BEFORE或AFTER
# refvalue,标杆值,即:在它前后插入数据
# value,要插入的数据
例子:
127.0.0.1:6379[7]> linsert h5 before lisi 10
(integer) 9
127.0.0.1:6379[7]> lrange h5 0 -1
1) "zhaoliu"
2) "wanger"
3) "10"
4) "lisi"
5) "zhangsan"
6) "zhaoliu"
7) "wanger"
8) "lisi"
9) "zhangsan"
lset(name, index, value)
索引之后重新赋值
# 对name对应的list中的某一个索引位置重新赋值
# 参数:
# name,redis的name
# index,list的索引位置
# value,要设置的值
例子:
127.0.0.1:6379[7]> lset h5 1 11
OK
127.0.0.1:6379[7]> lrange h5 0 -1
1) "zhaoliu"
2) "11"
3) "10"
4) "lisi"
5) "zhangsan"
6) "zhaoliu"
7) "wanger"
8) "lisi"
9) "zhangsan"
lrem(name, num, value)
# 在name对应的list中删除指定的值
# 参数:
# name,redis的name
# value,要删除的值
# num, num=0,删除列表中所有的指定值;
# num=2,从前到后,删除2个;
# num=-2,从后向前,删除2个
例子:
127.0.0.1:6379[7]> lrem h5 1 11
(integer) 1
127.0.0.1:6379[7]> lrange h5 0 -1
1) "zhaoliu"
2) "10"
3) "lisi"
4) "zhangsan"
5) "zhaoliu"
6) "wanger"
7) "lisi"
8) "zhangsan"
lpop(name)
# 在name对应的列表的左侧获取第一个元素并在列表中移除,返回值则是第一个元素
# 更多:
# rpop(name) 表示从右向左操作
lindex(name, index)
在name对应的列表中根据索引获取列表元素
lrange(name, start, end)
# 在name对应的列表分片获取数据
# 参数:
# name,redis的name
# start,索引的起始位置
# end,索引结束位置
ltrim(name, start, end)
# 在name对应的列表中移除没有在start-end索引之间的值
# 参数:
# name,redis的name
# start,索引的起始位置
# end,索引结束位置
五、set操作
Set操作,Set集合就是不允许重复的列表
sadd(name,values)
# name对应的集合中添加元素 127.0.0.1:6379[7]> sadd java 12 113 14 15 (integer) 4 127.0.0.1:6379[7]> sadd python 12 15 113 11 (integer) 4
scard(name)
获取name对应的集合中元素个数 127.0.0.1:6379[7]> scard java (integer) 4
sdiff(keys, *args)
在第一个name对应的集合中且不在其他name对应的集合的元素集合
sinter(keys, *args)
# 获取多个name对应集合的交集 127.0.0.1:6379[7]> sinter java python 1) "12" 2) "15" 3) "113"
sunion(keys, *args)
# 获取多一个name对应的集合的并集 127.0.0.1:6379[7]> sunion java python 1) "11" 2) "12" 3) "14" 4) "15" 5) "113"
有序集合,在集合的基础上,为每元素排序;元素的排序需要根据另外一个值来进行比较,所以,对于有序集合,每一个元素有两个值,即:值和分数,分数专门用来做排序。
zadd(name, *args, **kwargs)
# 在name对应的有序集合中添加元素
# 如:
# zadd('zz', 'n1', 1, 'n2', 2)
# 或
# zadd('zz', n1=11, n2=22)
zcard(name)
# 获取name对应的有序集合元素的数量
zcount(name, min, max)
# 获取name对应的有序集合中分在 [min,max] 之间的个数
r.zrange( name, start, end, desc=False, withscores=False, score_cast_func=float)
# 按照索引范围获取name对应的有序集合的元素
# 参数:
# name,redis的name
# start,有序集合索引起始位置(非分数)
# end,有序集合索引结束位置(非分数)
# desc,排序规则,默认按照分数从小到大排序
# withscores,是否获取元素的分数,默认只获取元素的值
# score_cast_func,对分数进行数据转换的函数
# 更多:
# 从大到小排序
# zrevrange(name, start, end, withscores=False, score_cast_func=float)
# 按照分数范围获取name对应的有序集合的元素
# zrangebyscore(name, min, max, start=None, num=None, withscores=False, score_cast_func=float)
# 从大到小排序
# zrevrangebyscore(name, max, min, start=None, num=None, withscores=False, score_cast_func=float)
zrank(name, value)
# 获取某个值在 name对应的有序集合中的排行(从 0 开始)
# 更多:
# zrevrank(name, value),从大到小排序
综合实例:
127.0.0.1:6379[7]> sadd java 12 113 14 15(integer) 1127.0.0.1:6379[7]> scard java(integer) 4127.0.0.1:6379[7]> SMEMBERS java1) "12"2) "14"3) "15"4) "113"
127.0.0.1:6379[7]> sadd python 12 15 113 11(integer) 4
做差集
127.0.0.1:6379[7]> sdiff java python1) "14"127.0.0.1:6379[7]> smembers java1) "12"2) "14"3) "15"4) "113"127.0.0.1:6379[7]> smembers python1) "11"2) "12"3) "15"4) "113"
六、其他常用操作
del (*names)
# 根据删除redis中的任意数据类型
exists(name)
# 检测redis的name是否存在
keys(pattern='*')
# 根据模型获取redis的name
# 更多:
# KEYS * 匹配数据库中所有 key 。
# KEYS h?llo 匹配 hello , hallo 和 hxllo 等。
# KEYS h*llo 匹配 hllo 和 heeeeello 等。
# KEYS h[ae]llo 匹配 hello 和 hallo ,但不匹配 hillo
rename(src, dst)
# 对redis的name重命名为 rename(原名字,新名字)
type(name)
# 获取name对应值的类型
keys *
查看当前db下所有的key
select num 注:num为0-15的数字
切换到指定的数据库
help 指令
查看该指令的帮助 很方便 不会看它 一切尽在掌握
七、小结
-
redis 基本写法基本上是:
key空格value的形式
-
redis 的各种类型的操作基本都会在对应方法前面加上该类型的首写字母,如
1.list类型求长度 llen(name)
2. hash 类型求长度 hlen(name) 等等
-
不知道哪个命令怎么用时可以多看help

 浙公网安备 33010602011771号
浙公网安备 33010602011771号