数据结构与算法——二叉树
为什么需要树这种数据结构?
数组存储方式的分析
- 优点:
- 通过 下标 方式访问元素,速度快
- 对于 有序数组,还可以使用二分查找提高检索速度
- 缺点:如果无序数组要检索具体某个值,或插入值(按一定顺序)会整体移动,并且数组的大小固定,如果该数组已经满了但又想插入数据,那就必须对该数组进行扩容,效率较低,如下的示意图

链表存储方式的分析
-
优点:在一定程度上对数组存储方式有优化
例如:插入一个数值节点,只需要将插入节点,链接到链表中即可,同理,删除效率也很好
-
缺点:检索效率较低
需要从头结点开始遍历查找。
简单说:
- 数组访问快,增删慢
- 链表增删快,访问慢
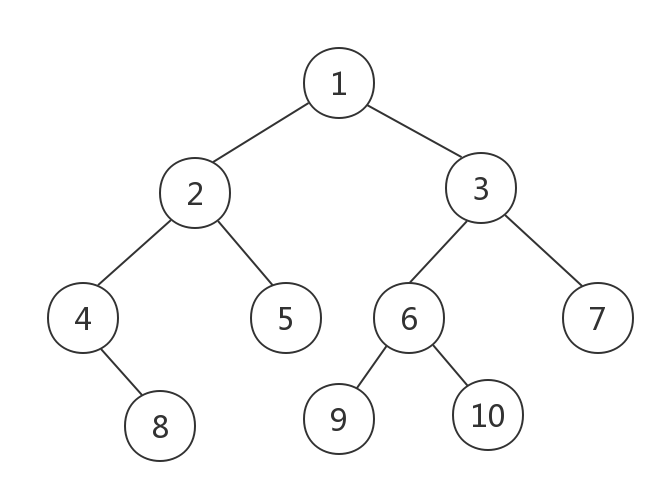
所以就出现了 树 这种数据结构。如下图就是二叉树模型

树 存储数据方式分析
提供数据 存储 、读取 效率。
例如:利用 二叉排序树(Binary Sort Tree),既可以保证数据的检索速度,同时也可以保证数据的插入、删除、修改 的速度
如图所示:
- 插入时,小的数在 左节点、大的数在 右节点
- 查找时:根据插入事的特性,基本上就类似折半查找了,每次都过滤一半的节点
- 删除时:只需要移动相邻的节点的引用
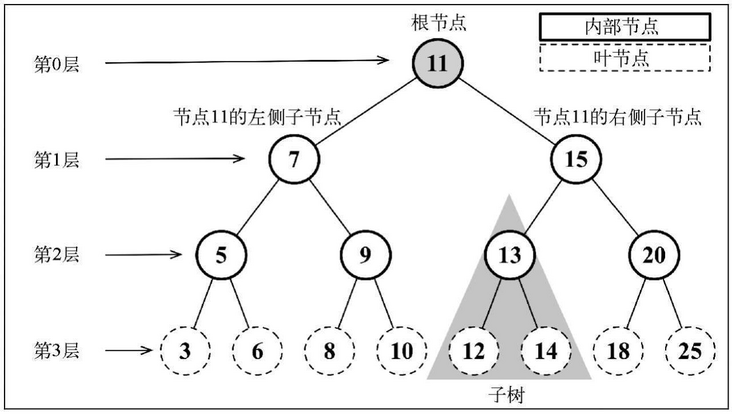
树 的常用术语
-
节点:每一个圆圈表示一个节点,也称节点对象 -
根节点:最上面,最顶部的那个节点,也就是一棵树的入口 -
父节点:有子节点的节点 -
子节点:看图 -
兄弟节点:具有相同父节点的节点互称为兄弟节点 -
叶子节点:没有子节点的节点 -
非终端节点或分支节点:度不为零的节点 -
节点的度:一个节点含有的子树的个数称为该节点的度 -
树的度:一棵树中,最大的节点度称为树的度 -
节点的权:可以简单的理解为节点值有时候也用 路径 来表示
-
路径:从 root 节点找到该节点的路线 -
层:看图 -
子树:有子节点的父子两层就可以称为是一个子树 -
树的高度:最大层数 -
森林:多棵子树构成森林
二叉树的概念
二叉树(Binary tree)是树形结构的一个重要类型。许多实际问题抽象出来的数据结构往往是二叉树形式,即使是一般的树也能简单地转换为二叉树,而且二叉树的存储结构及其算法都较为简单,因此二叉树显得特别重要。二叉树特点是每个结点最多只能有两棵子树,且有左右之分 。
二叉树是n个有限元素的集合,该集合或者为空、或者由一个称为根(root)的元素及两个不相交的、被分别称为左子树和右子树的二叉树组成,是有序树。当集合为空时,称该二叉树为空二叉树。在二叉树中,一个元素也称作一个结点 (节点)。
定义:
二叉树(binary tree)是指树中节点的度不大于2的有序树,它是一种最简单且最重要的树。二叉树的递归定义为:二叉树是一棵空树,或者是一棵由一个根节点和两棵互不相交的,分别称作根的左子树和右子树组成的非空树;左子树和右子树又同样都是二叉树。
-
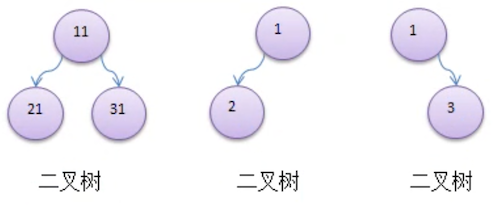
二叉树的子节点分为 左节点 和 右节点
-
如果该二叉树的所有 叶子节点 都在 最后一层,并且 节点总数 =
2^n -1(n 为层数),则我们称为 满二叉树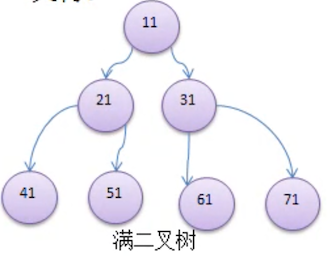
-
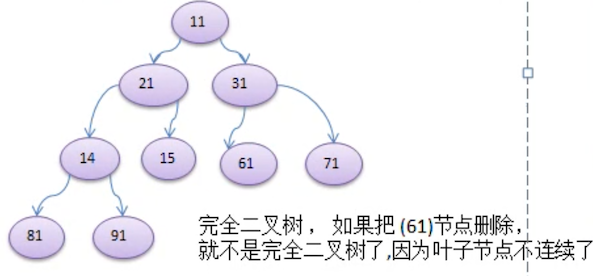
如果该二叉树的所有叶子节点都在最 后一层或倒数第二层,而且 最后一层的叶子节点在左边连续,倒数第二层的叶子节点在右边连续,我们称为 完全二叉树
详细点的解析:
一棵深度为k且有

个结点的二叉树称为满二叉树。
根据二叉树的性质2, 满二叉树每一层的结点个数都达到了最大值, 即满二叉树的第i层上有

个结点 (i≥1) 。
如果对满二叉树的结点进行编号, 约定编号从根结点起, 自上而下, 自左而右。则深度为k的, 有n个结点的二叉树, 当且仅当其每一个结点都与深度为k的满二叉树中编号从1至n的结点一一对应时, 称之为完全二叉树。 [2]
从满二叉树和完全二叉树的定义可以看出, 满二叉树是完全二叉树的特殊形态, 即如果一棵二叉树是满二叉树, 则它必定是完全二叉树。
完全二叉树的特点:叶子结点只能出现在最下层和次下层,且最下层的叶子结点集中在树的左部。需要注意的是,满二叉树肯定是完全二叉树,而完全二叉树不一定是满二叉树。
二叉树的遍历
有三种:
前序遍历:先输出父节点,再遍历左子树(递归)和右子树(递归)中序遍历:先遍历左子树(递归),再输出父节点,再遍历右子树(递归)后序遍历:先遍历左子树(递归),再遍历右子树(递归),最后输出父节点
看上述粗体部分:前中后说的就是父节点的输出时机。
注意理清楚描述中的递归,这关乎着你如何找到下一个输出节点
关于递归,请看 数据结构与算法——初谈递归
二叉树遍历思路分析
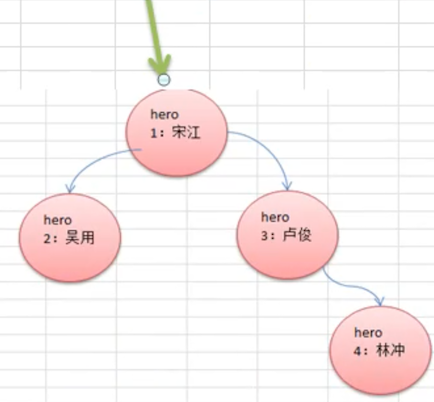
-
前序遍历:
- 先输出当前节点(初始节点是 root 节点)
- 如果左子节点不为空,则递归继续前序遍历
- 如果右子节点不为空,则递归继续前序遍历
上图的输出顺序为:1、2、3、4
-
中序遍历:
- 如果当前节点的左子节点不为空,则递归中序遍历
- 输出当前节点
- 如果当前节点的右子节点不为空,则递归中序
上图的输出顺序为:2、1、3、4
-
后序遍历:
- 如果左子节点不为空,则递归继续前序遍历
- 如果右子节点不为空,则递归继续前序遍历
- 输出当前节点
上图的输出顺序为:2、4、3、1
如果不理解,就结合下面的代码进行理解。
二叉树遍历代码实现
注意这里
this的含义。
/**
* 二叉树测试
*/
public class BinaryTreeTest {
// 先编写二叉树节点
class HeroNode {
public int id;
public String name;
public HeroNode left;
public HeroNode right;
public HeroNode(int id, String name) {
this.id = id;
this.name = name;
}
@Override
public String toString() {
return "HeroNode{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
/**
* 前序遍历
*/
public void preOrder() {
// 1. 先输出当前节点
System.out.println(this);
// 2. 如果左子节点不为空,则递归继续前序遍历
if (this.left != null) {
this.left.preOrder();
}
// 3. 如果右子节点不为空,则递归继续前序遍历
if (this.right != null) {
this.right.preOrder();
}
}
/**
* 中序遍历
*/
public void infixOrder() {
// 1. 如果左子节点不为空,则递归继续前序遍历
if (this.left != null) {
this.left.infixOrder();
}
// 2. 先输出当前节点
System.out.println(this);
// 3. 如果右子节点不为空,则递归继续前序遍历
if (this.right != null) {
this.right.infixOrder();
}
}
/**
* 后序遍历
*/
public void postOrder() {
// 1. 如果左子节点不为空,则递归继续前序遍历
if (this.left != null) {
this.left.postOrder();
}
// 2. 如果右子节点不为空,则递归继续前序遍历
if (this.right != null) {
this.right.postOrder();
}
// 3. 先输出当前节点
System.out.println(this);
}
}
// 编写 二叉树 类
class BinaryTree {
public HeroNode root;//树根
/**
* 前序遍历
*/
public void preOrder() {
//判断二叉树是否为空
if (root == null) {
System.out.println("二叉树为空");
return;
}
root.preOrder();
}
/**
* 中序遍历
*/
public void infixOrder() {
if (root == null) {
System.out.println("二叉树为空");
return;
}
root.infixOrder();
}
/**
* 后续遍历
*/
public void postOrder() {
if (root == null) {
System.out.println("二叉树为空");
return;
}
root.postOrder();
}
}
/**
* 前、中、后 遍历测试
*/
@Test
public void fun1() {
// 手动创建节点与构建二叉树
HeroNode n1 = new HeroNode(1, "宋江");
HeroNode n2 = new HeroNode(2, "无用");
HeroNode n3 = new HeroNode(3, "卢俊");
HeroNode n4 = new HeroNode(4, "林冲");
n1.left = n2;
n1.right = n3;
n3.right = n4;
BinaryTree binaryTree = new BinaryTree();
binaryTree.root = n1;
System.out.println("\n 前序遍历:");
binaryTree.preOrder();
System.out.println("\n 中序遍历:");
binaryTree.infixOrder();
System.out.println("\n 后序遍历:");
binaryTree.postOrder();
}
}
测试输出
前序遍历:
HeroNode{id=1, name='宋江'}
HeroNode{id=2, name='无用'}
HeroNode{id=3, name='卢俊'}
HeroNode{id=4, name='林冲'}
中序遍历:
HeroNode{id=2, name='无用'}
HeroNode{id=1, name='宋江'}
HeroNode{id=3, name='卢俊'}
HeroNode{id=4, name='林冲'}
后序遍历:
HeroNode{id=2, name='无用'}
HeroNode{id=4, name='林冲'}
HeroNode{id=3, name='卢俊'}
HeroNode{id=1, name='宋江'}
思考一下:
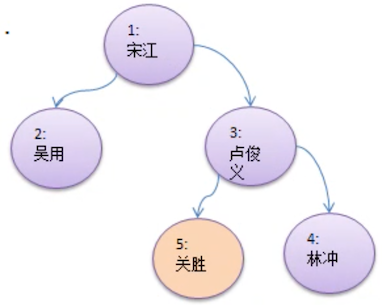
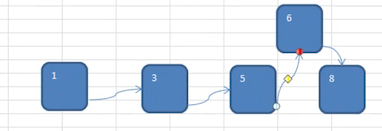
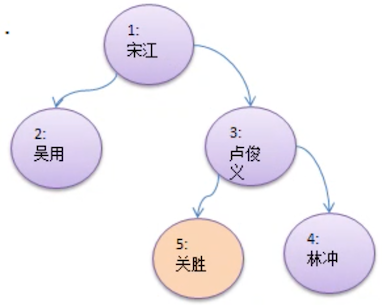
如上图,给 卢俊义 增加一个节点 关胜,写出他的前、中、后序的打印顺序:
注意:上面这个新增的节点,并不是按照顺序增加的,这里考的知识点是 前、中、后序的遍历规则
-
前序:1、2、3、5、4
-
中序:2、1、5、3,4
-
后序:2、5、4、3、1
那么下面通过程序来检测答案是否正确:
/**
* 考题:给卢俊新增一个 left 节点,然后打印前、中、后 遍历顺序
*/
@Test
public void fun2() {
// 创建节点与构建二叉树
HeroNode n1 = new HeroNode(1, "宋江");
HeroNode n2 = new HeroNode(2, "无用");
HeroNode n3 = new HeroNode(3, "卢俊");
HeroNode n4 = new HeroNode(4, "林冲");
HeroNode n5 = new HeroNode(5, "关胜");
n1.left = n2;
n1.right = n3;
n3.right = n4;
n3.left = n5;
BinaryTree binaryTree = new BinaryTree();
binaryTree.root = n1;
System.out.println("\n 前序遍历:");
binaryTree.preOrder();
System.out.println("\n 中序遍历:");
binaryTree.infixOrder();
System.out.println("\n 后序遍历:");
binaryTree.postOrder();
}
输出信息
前序遍历:
HeroNode{id=1, name='宋江'}
HeroNode{id=2, name='无用'}
HeroNode{id=3, name='卢俊'}
HeroNode{id=5, name='关胜'}
HeroNode{id=4, name='林冲'}
中序遍历:
HeroNode{id=2, name='无用'}
HeroNode{id=1, name='宋江'}
HeroNode{id=5, name='关胜'}
HeroNode{id=3, name='卢俊'}
HeroNode{id=4, name='林冲'}
后序遍历:
HeroNode{id=2, name='无用'}
HeroNode{id=5, name='关胜'}
HeroNode{id=4, name='林冲'}
HeroNode{id=3, name='卢俊'}
HeroNode{id=1, name='宋江'}
可以看到,后序是最容易弄错的规则,所以在后续上,一定要多多 debug,多多思考 ,看下他的调用轨迹。
二叉树的查找
要求:
- 编写前、中、后序查找方法(和上面的遍历类似,只是添加了一些东西,注意观察,细看代码,思想是一样的)
- 并分别使用三种查找方式,查找
id=5的节点 - 并分析各种查找方式,分别比较了多少次
由于二叉树的查找是遍历查找,所以就简单了,前面遍历规则已经写过了,改写成查找即可
/**
* 二叉树测试
*/
public class BinaryTreeTest {
// 先编写二叉树节点
class HeroNode {
public int id;
public String name;
public HeroNode left;
public HeroNode right;
public HeroNode(int id, String name) {
this.id = id;
this.name = name;
}
@Override
public String toString() {
return "HeroNode{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
/**
* 前序遍历
*/
public void preOrder() {
// 1. 先输出当前节点
System.out.println(this);
// 2. 如果左子节点不为空,则递归继续前序遍历
if (this.left != null) {
this.left.preOrder();
}
// 3. 如果右子节点不为空,则递归继续前序遍历
if (this.right != null) {
this.right.preOrder();
}
}
/**
* 中序遍历
*/
public void infixOrder() {
// 1. 如果左子节点不为空,则递归继续前序遍历
if (this.left != null) {
this.left.infixOrder();
}
// 2. 先输出当前节点
System.out.println(this);
// 3. 如果右子节点不为空,则递归继续前序遍历
if (this.right != null) {
this.right.infixOrder();
}
}
/**
* 后序遍历
*/
public void postOrder() {
// 1. 如果左子节点不为空,则递归继续前序遍历
if (this.left != null) {
this.left.postOrder();
}
// 2. 如果右子节点不为空,则递归继续前序遍历
if (this.right != null) {
this.right.postOrder();
}
// 3. 先输出当前节点
System.out.println(this);
}
/**
* 前序查找
*/
public HeroNode preOrderSearch(int id) {
System.out.println(" 进入前序遍历"); // 用来统计查找了几次
// 1. 判断当前节点是否相等,如果相等,则返回
if (this.id == id) {
return this;
}
// 2. 如果左子节点不为空,则递归继续前序遍历
if (this.left != null) {
HeroNode result = this.left.preOrderSearch(id);
if (result != null) {
return result;
}
}
// 3. 如果右子节点不为空,则递归继续前序遍历
if (this.right != null) {
HeroNode result = this.right.preOrderSearch(id);
if (result != null) {
return result;
}
}
return null;
}
/**
* 中序查找
*/
public HeroNode infixOrderSearch(int id) {
// System.out.println(" 进入中序遍历"); // 用来统计查找了几次,不能在这里打印,这里打印是进入了方法几次,看的是比较了几次
// 1. 如果左子节点不为空,则递归继续前序遍历
if (this.left != null) {
HeroNode result = this.left.infixOrderSearch(id);
if (result != null) {
return result;
}
}
System.out.println(" 进入中序遍历");// 用来统计查找了几次
// 2. 如果相等,则返回
if (this.id == id) {
return this;
}
// 3. 如果右子节点不为空,则递归继续前序遍历
if (this.right != null) {
HeroNode result = this.right.infixOrderSearch(id);
if (result != null) {
return result;
}
}
return null;
}
/**
* 后序查找
*/
public HeroNode postOrderSearch(int id) {
// System.out.println(" 进入后序遍历"); // 用来统计查找了几次,不能在这里打印,这里打印是进入了方法几次,看的是比较了几次
// 1. 如果左子节点不为空,则递归继续前序遍历
if (this.left != null) {
HeroNode result = this.left.postOrderSearch(id);
if (result != null) {
return result;
}
}
// 2. 如果右子节点不为空,则递归继续前序遍历
if (this.right != null) {
HeroNode result = this.right.postOrderSearch(id);
if (result != null) {
return result;
}
}
System.out.println(" 进入后序遍历");// 用来统计查找了几次
// 3. 如果相等,则返回
if (this.id == id) {
return this;
}
return null;
}
}
// 编写 二叉树 类
class BinaryTree {
public HeroNode root;
/**
* 前序遍历
*/
public void preOrder() {
if (root == null) {
System.out.println("二叉树为空");
return;
}
root.preOrder();
}
/**
* 中序遍历
*/
public void infixOrder() {
if (root == null) {
System.out.println("二叉树为空");
return;
}
root.infixOrder();
}
/**
* 后续遍历
*/
public void postOrder() {
if (root == null) {
System.out.println("二叉树为空");
return;
}
root.postOrder();
}
/**
* 前序查找
*/
public HeroNode preOrderSearch(int id) {
//判断树是否为空
if (root == null) {
System.out.println("二叉树为空");
return null;
}
return root.preOrderSearch(id);
}
/**
* 中序查找
*/
public HeroNode infixOrderSearch(int id) {
if (root == null) {
System.out.println("二叉树为空");
return null;
}
return root.infixOrderSearch(id);
}
/**
* 后序查找
*/
public HeroNode postOrderSearch(int id) {
if (root == null) {
System.out.println("二叉树为空");
return null;
}
return root.postOrderSearch(id);
}
}
/**
* 查找 id=5 的前、中、后序测试
*/
@Test
public void fun3() {
// 创建节点与构建二叉树
HeroNode n1 = new HeroNode(1, "宋江");
HeroNode n2 = new HeroNode(2, "无用");
HeroNode n3 = new HeroNode(3, "卢俊");
HeroNode n4 = new HeroNode(4, "林冲");
HeroNode n5 = new HeroNode(5, "关胜");
n1.left = n2;
n1.right = n3;
n3.right = n4;
n3.left = n5;
BinaryTree binaryTree = new BinaryTree();
binaryTree.root = n1;
System.out.println("找到测试:");
int id = 5;
System.out.println("\n前序遍历查找 id=" + id);
System.out.println(binaryTree.preOrderSearch(id));
System.out.println("\n中序遍历查找 id=" + id);
System.out.println(binaryTree.infixOrderSearch(id));
System.out.println("\n后序遍历查找 id=" + id);
System.out.println(binaryTree.postOrderSearch(id));
System.out.println("找不到测试:");
id = 15;
System.out.println("\n前序遍历查找 id=" + id);
System.out.println(binaryTree.preOrderSearch(id));
System.out.println("\n中序遍历查找 id=" + id);
System.out.println(binaryTree.infixOrderSearch(id));
System.out.println("\n后序遍历查找 id=" + id);
System.out.println(binaryTree.postOrderSearch(id));
}
}
测试输出
找到测试:
前序遍历查找 id=5 # 共查找 4 次
进入前序遍历
进入前序遍历
进入前序遍历
进入前序遍历
HeroNode{id=5, name='关胜'}
中序遍历查找 id=5 # 共查找 3 次
进入中序遍历
进入中序遍历
进入中序遍历
HeroNode{id=5, name='关胜'}
后序遍历查找 id=5 # 共查找 2 次
进入后序遍历
进入后序遍历
HeroNode{id=5, name='关胜'}
找不到测试:
前序遍历查找 id=15
进入前序遍历
进入前序遍历
进入前序遍历
进入前序遍历
进入前序遍历
null
中序遍历查找 id=15
进入中序遍历
进入中序遍历
进入中序遍历
进入中序遍历
进入中序遍历
null
后序遍历查找 id=15
进入后序遍历
进入后序遍历
进入后序遍历
进入后序遍历
进入后序遍历
null
可以看出:
- 找到的次数和 查找的顺序 有关,而查找顺序就是于遍历方式有关
- 找不到的次数则是相当于都遍历完成,所以是相等的次数
二叉树的删除
要求:
- 如果删除的节点是 叶子节点,则删除该节点
- 如果删除的节点是非叶子节点,则删除该子树
测试:删除 5 号叶子节点和 3 号子树。
说明:目前的二叉树不是规则的,如果不删除子树,则需要考虑哪一个节点会被上提作为父节点。这个后续讲解排序二叉树时再来实现。先实现简单的
思路分析:
-
由于我们的二叉树是单向的
-
所以我们判定一个节点是否可以删除,是判断它的 子节点 是否可删除,否则则没法回到父节点删除了,因为要判断被删除的节点满足前面的两点要求(因为链表的关系)
- 当前节点的 左子节点 不为空,并且左子节点就是要删除的节点,则 this.left = null,并且返回(结束递归删除)
- 当前节点的 右子节点 不为空,并且右子节点就是要删除的节点,则 this.right = null,并且返回(结束递归删除)
如果前面都没有删除,则继续递归,直到找到并删除,或者是找不到对应的节点,输出没有该节点即可。上面的要求是 2 点,实际上是,找到符合条件的节点则直接删除(因为不考虑是否有子树)
// BinaryTree 新增删除的方法
/**
* 删除节点
*
* @param id
* @return
*/
public HeroNode delete(int id) {
if (root == null) {
System.out.println("树为空");
return null;
}
HeroNode target = null;//保存要删除的目标节点
// 如果 root 节点就是要删除的节点,则直接置空
if (root.id == id) {
target = root;
root = null;
} else {
target = this.root.delete(id);
}
return target;
}
// HeroNode 中新增删除的方法
/**
* 删除节点,思路,先看左右,看完再递归,具体看代码
* @param id
* @return 如果删除成功,则返回删除的节点
*/
public HeroNode delete(int id) {
// 判断左子节点是否是要删除的节点
HeroNode target = null;
if (this.left != null && this.left.id == id) {
target = this.left;
this.left = null;
return target;
}
if (this.right != null && this.right.id == id) {
target = this.right;
this.right = null;
return target;
}
// 尝试左递归
if (this.left != null) {
target = this.left.delete(id);
if (target != null) {
return target;
}
}
// 尝试右递归
if (this.right != null) {
target = this.right.delete(id);
if (target != null) {
return target;
}
}
return null;
}
删除方法测试用例
/**
* 构建当前这个树
*
* @return
*/
private BinaryTree buildBinaryTree() {
HeroNode n1 = new HeroNode(1, "宋江");
HeroNode n2 = new HeroNode(2, "无用");
HeroNode n3 = new HeroNode(3, "卢俊");
HeroNode n4 = new HeroNode(4, "林冲");
HeroNode n5 = new HeroNode(5, "关胜");
n1.left = n2;
n1.right = n3;
n3.right = n4;
n3.left = n5;
BinaryTree binaryTree = new BinaryTree();
binaryTree.root = n1;
return binaryTree;
}
/**
* 不考虑子节点的删除
*/
@Test
public void delete() {
System.out.println("\n删除 3 号节点");
delete3();
System.out.println("\n删除 5 号节点");
delete5();
System.out.println("\n删除一个不存在的节点");
deleteFail();
System.out.println("\n删除 root 节点");
deleteRoot();
}
@Test
public void delete3() {
// 创建节点与构建二叉树
BinaryTree binaryTree = buildBinaryTree();
binaryTree.preOrder();
// 删除 3 号节点
HeroNode target = binaryTree.delete(3);
String msg = (target == null ? "删除失败,未找到" : "删除成功:" + target.toString());
System.out.println(msg);
binaryTree.preOrder();
}
@Test
public void delete5() {
// 创建节点与构建二叉树
BinaryTree binaryTree = buildBinaryTree();
binaryTree.preOrder();
// 删除 5 号节点
HeroNode target = binaryTree.delete(5);
String msg = (target == null ? "删除失败,未找到" : "删除成功:" + target.toString());
System.out.println(msg);
binaryTree.preOrder();
}
/**
* 删除一个不存在的节点
*/
@Test
public void deleteFail() {
// 创建节点与构建二叉树
BinaryTree binaryTree = buildBinaryTree();
binaryTree.preOrder();
// 删除 5 号节点
HeroNode target = binaryTree.delete(9);
String msg = (target == null ? "删除失败,未找到" : "删除成功:" + target.toString());
System.out.println(msg);
binaryTree.preOrder();
}
/**
* 删除 root 节点
*/
@Test
public void deleteRoot() {
// 创建节点与构建二叉树
BinaryTree binaryTree = buildBinaryTree();
binaryTree.preOrder();
// 删除 1 号节点
HeroNode target = binaryTree.delete(1);
String msg = (target == null ? "删除失败,未找到" : "删除成功:" + target.toString());
System.out.println(msg);
binaryTree.preOrder();
}
分别输出信息如下
删除 3 号节点
HeroNode{id=1, name='宋江'}
HeroNode{id=2, name='无用'}
HeroNode{id=3, name='卢俊'}
HeroNode{id=5, name='关胜'}
HeroNode{id=4, name='林冲'}
删除成功:HeroNode{id=3, name='卢俊'}
HeroNode{id=1, name='宋江'}
HeroNode{id=2, name='无用'}
删除 5 号节点
HeroNode{id=1, name='宋江'}
HeroNode{id=2, name='无用'}
HeroNode{id=3, name='卢俊'}
HeroNode{id=5, name='关胜'}
HeroNode{id=4, name='林冲'}
删除成功:HeroNode{id=5, name='关胜'}
HeroNode{id=1, name='宋江'}
HeroNode{id=2, name='无用'}
HeroNode{id=3, name='卢俊'}
HeroNode{id=4, name='林冲'}
删除一个不存在的节点
HeroNode{id=1, name='宋江'}
HeroNode{id=2, name='无用'}
HeroNode{id=3, name='卢俊'}
HeroNode{id=5, name='关胜'}
HeroNode{id=4, name='林冲'}
删除失败,未找到
HeroNode{id=1, name='宋江'}
HeroNode{id=2, name='无用'}
HeroNode{id=3, name='卢俊'}
HeroNode{id=5, name='关胜'}
HeroNode{id=4, name='林冲'}
删除 root 节点
HeroNode{id=1, name='宋江'}
HeroNode{id=2, name='无用'}
HeroNode{id=3, name='卢俊'}
HeroNode{id=5, name='关胜'}
HeroNode{id=4, name='林冲'}
删除成功:HeroNode{id=1, name='宋江'}
二叉树为空
一、顺序存储二叉树
基本说明-概念
从数据存储来看,数组存储 方式和 树 的存储方式可以 相互转换。即使数组可以转换成树,树也可以转换成数组。如下示意图
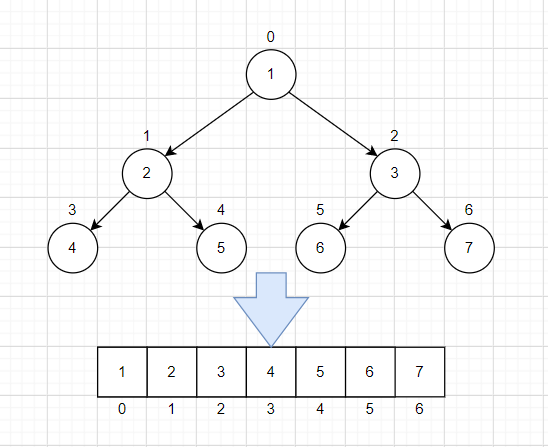
上图阅读说明:
- 圆圈顶部的数字对应了数组中的索引
- 圆圈内部的值对应的数数组元素的值
现在有两个要求:
- 上图的二叉树的节点,要求以数组的方式来存储
arr=[1,2,3,4,5,6,7] - 要求在遍历数组 arr 时,仍然可以以 前序、中序、后序的方式遍历
特点(思路)
想要 实现上面的两个要求,需要知道顺序存储二叉树的特点:
- 顺序二叉树 通常只考虑 完全二叉树(完全二叉树上面有解释)
- 第 n 个元素的 左子节点 为
2*n+1 - 第 n 个元素的 右子节点 为
2*n+2 - 第 n 个元素的 父节点 为
(n-1)/2
注:n 表示二叉树中的第几个元素(按 0 开始编号)
比如:
- 元素 2 的左子节点为:
2 * 1 + 1 = 3,对比上图去查看,的确是 3 - 元素 2 的右子节点为:
2 * 1 + 2 = 4,也 就是元素 5 - 元素 3 的左子节点为:
2 * 2 + 1 = 5,也就是元素 6 - 元素 3 的父节点为:
(2-1)/2= 1/2 = 0,也就是根节点 1
搞懂特点规律,下面进行代码实现。
前序遍历
使用如上的知识点,进行前序遍历,需求:将数组 arr=[1,2,3,4,5,6,7],以二叉树前序遍历的方式进行遍历,遍历结果为 1、2、4、5、3、6
前序遍历概念(上面有讲):
- 先输出当前节点(初始节点是 root 节点)
- 如果左子节点不为空,则递归继续前序遍历
- 如果右子节点不为空,则递归继续前序遍历
/**
* 顺序存储二叉树
*/
public class ArrBinaryTreeTest {
/**
* 前序遍历测试
*/
@Test
public void preOrder() {
int[] arr = new int[]{1, 2, 3, 4, 5, 6, 7};
ArrBinaryTree tree = new ArrBinaryTree(arr);
tree.preOrder(0); // 1,2,4,5,3,6,7
}
}
class ArrBinaryTree {
int[] arr;
public ArrBinaryTree(int[] arr) {
this.arr = arr;
}
/**
* 前序遍历
*
* @param index 就是知识点中的 n,从哪一个节点开始遍历
*/
public void preOrder(int index) {
/*
1. 顺序二叉树 通常只考虑 **完成二叉树**
2. 第 n 个元素的 **左子节点** 为 `2*n+1`
3. 第 n 个元素的 **右子节点** 为 `2*n+2`
4. 第 n 个元素的 **父节点** 为 `(n-1)/2`
*/
if (arr == null || arr.length == 0) {
System.out.println("数组为空,不能前序遍历二叉树");
return;
}
// 1. 先输出当前节点(初始节点是 root 节点)
System.out.println(arr[index]);
// 2. 如果左子节点不为空,则递归继续前序遍历
int left = 2 * index + 1;
if (left < arr.length) {
preOrder(left);
}
// 3. 如果右子节点不为空,则递归继续前序遍历
int right = 2 * index + 2;
if (right < arr.length) {
preOrder(right);
}
}
}
测试输出
1
2
4
5
3
6
7
中序、后序遍历
/**
* 中序遍历:先遍历左子树,再输出父节点,再遍历右子树
*
* @param index
*/
public void infixOrder(int index) {
if (arr == null || arr.length == 0) {
System.out.println("数组为空,不能前序遍历二叉树");
return;
}
int left = 2 * index + 1;
if (left < arr.length) {
infixOrder(left);
}
System.out.println(arr[index]);
int right = 2 * index + 2;
if (right < arr.length) {
infixOrder(right);
}
}
/**
* 后序遍历:先遍历左子树,再遍历右子树,最后输出父节点
*
* @param index
*/
public void postOrder(int index) {
if (arr == null || arr.length == 0) {
System.out.println("数组为空,不能前序遍历二叉树");
return;
}
int left = 2 * index + 1;
if (left < arr.length) {
postOrder(left);
}
int right = 2 * index + 2;
if (right < arr.length) {
postOrder(right);
}
System.out.println(arr[index]);
}
测试代码
/**
* 中序遍历测试
*/
@Test
public void infixOrder() {
int[] arr = new int[]{1, 2, 3, 4, 5, 6, 7};
ArrBinaryTree tree = new ArrBinaryTree(arr);
tree.infixOrder(0); // 4,2,5,1,6,3,7
}
/**
* 后序遍历测试
*/
@Test
public void postOrder() {
int[] arr = new int[]{1, 2, 3, 4, 5, 6, 7};
ArrBinaryTree tree = new ArrBinaryTree(arr);
tree.postOrder(0); // 4,5,2,6,7,3,1
}
应用案例
学会了顺序存储二叉树,那么它可以用来做什么呢?
八大排序算法中的 堆排序,就会使用到顺序存储二叉树。
二、线索化二叉树
为什么要线索化二叉树?
看如下问题:将数列 {1,3,6,8,10,14} 构成一颗二叉树

可以看到上图的二叉树为一颗 完全二叉树。对他进行分析,可以发现如下的一些问题:
- 当对上面的二叉树进行中序遍历时,数列为
8,3,10,1,14,6 - 但是
6,8,10,14这几个节点的左右指针,并没有完全用上
如果希望充分利用各个节点的左右指针,让各个节点可以 指向自己的前后节点,这个时候就可以使用 线索化二叉树 了
介绍
n 个节点的二叉树链表中含有 n + 1 个空指针域,他的推导公式为 2n-(n-1) = n + 1。
利用二叉树链表中的空指针域,存放指向该节点在 某种遍历次序下(前序,中序,后序)的 前驱节点 和 后继节点的指针,这种附加的指针称为「线索」
前驱:一个节点的前一个节点后继:一个节点的后一个节点
如下图,在中序遍历中,下图的中序遍历为 8,3,10,1,14,6,那么 8 的后继节点就为 3,8 没有前驱节点,10 的前驱节点是 3,10 的后继节点是 1 (主要是看遍历出来的数列的顺序来判定)
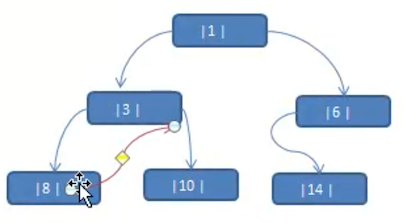
这种加上了线索的二叉树链表称为 线索链表(一般的二叉树本来就是用链表实现的),相应的二叉树称为 线索二叉树(Threaded BinaryTree)。根据线索性质的不同,线索二叉树可分为:前、中、后序线索二叉树。
思路分析
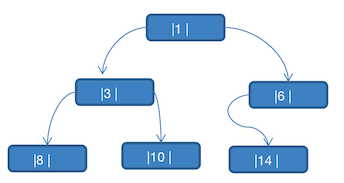
将上图的二叉树,进行 中序线索二叉树,中序遍历的数列为 8,3,10,1,14,6。
那么以上图为例,线索化二叉树后的样子如下图
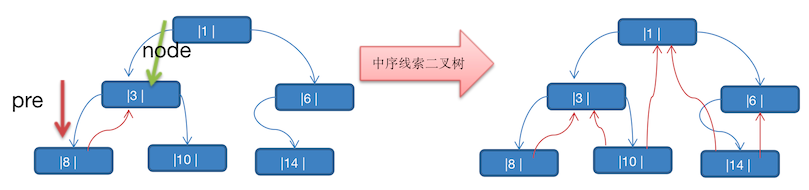
- 8 的后继节点为 3
- 3 由于 左右节点都有元素,不能线索化
- 10 的前驱节点为 3,后继节点为 1
- 1 不能线索化
- 14 的前驱节点为 1,后继节点为 6
- 6 有左节点,不能线索化
注意:当线索化二叉树后,那么一个 Node 节点的 left 和 right 属性,就有如下情况:
-
left 指向的是 左子树,也可能是指向 前驱节点
例如:节点 1 left 节点指向的是左子树,节点 10 的 left 指向的就是前驱节点
-
right 指向的是 右子树,也可能是指向 后继节点
例如:节点 3 的 right 指向的是右子树,节点 10 的 right 指向的是后继节点
代码实现
下面的代码,有几个地方需要注意:
-
HeroNode就是一个 简单的二叉树节点,不同的是多了两个type属性:leftType:左节点的类型:0:左子树,1:前驱节点rightType:右节点的类型:0:右子树,1:后继节点
为什么需要?上面原理讲解了,left 或则 right 会有两种身份,需要一个额外 的属性来指明
-
threadeNodes:线索化二叉树是将一棵二叉树,进行线索化标记。只是将可以线索化的节点进行赋值。
/**
* 线索化二叉树
*/
public class ThreadedBinaryTreeTest {
class HeroNode {
public int id;
public String name;
public HeroNode left;
public HeroNode right;
/**
* 左节点的类型:0:左子树,1:前驱节点
*/
public int leftType;
/**
* 右节点的类型:0:右子树,1:后继节点
*/
public int rightType;
public HeroNode(int id, String name) {
this.id = id;
this.name = name;
}
@Override
public String toString() {
return "HeroNode{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
}
class ThreadedBinaryTree {
public HeroNode root;
public HeroNode pre; // 保留上一个节点
/**
* 线索化二叉树:以 中序的方式线索化
*/
public void threadeNodes() {
// 从 root 开始遍历,然后 线索化
this.threadeNodes(root);
}
private void threadeNodes(HeroNode node) {
if (node == null) {
return;
}
// 中序遍历顺序:先左、自己、再右
threadeNodes(node.left);
// 难点就是在这里,如何线索化自己
// 当自己的 left 节点为空,则设置为前驱节点
if (node.left == null) {
node.left = pre;
node.leftType = 1;
}
// 因为要设置后继节点,只有回到自己(node)的后继节点的时候,才能把自己设置为前一个的后继节点 !!这里自己好好意会一下
// 当前一个节点的 right 为空时,则需要自己(node)是后继节点
if (pre != null && pre.right == null) {
pre.right = node;
pre.rightType = 1;
}
// 数列: 1,3,6,8,10,14
// 中序: 8,3,10,1,14,6
// 这里最好结合上面图示的二叉树来看,容易理解
// 因为中序遍历,先遍历左边,所以 8 是第一个输出的节点
// 当 node = 8 时,pre 还没有被赋值过,则为空。这是正确的,因为 8 就是第一个节点
// 当 8 处理完成之后,处理 3 时
// 当 node = 3 时,pre 被赋值为 8 了。
pre = node; //关键!!!!
threadeNodes(node.right);
}
}
@Test
public void threadeNodesTest() {
HeroNode n1 = new HeroNode(1, "宋江");
HeroNode n3 = new HeroNode(3, "无用");
HeroNode n6 = new HeroNode(6, "卢俊");
HeroNode n8 = new HeroNode(8, "林冲2");
HeroNode n10 = new HeroNode(10, "林冲3");
HeroNode n14 = new HeroNode(14, "林冲4");
n1.left = n3;
n1.right = n6;
n3.left = n8;
n3.right = n10;
n6.left= n14;
ThreadedBinaryTree tree = new ThreadedBinaryTree();
tree.root = n1;
tree.threadeNodes();
// 验证:
HeroNode left = n10.left;
HeroNode right = n10.right;
System.out.println("10 号节点的前驱节点:" + left.id);
System.out.println("10 号节点的后继节点:" + right.id);
}
}
测试输出
10 号节点的前驱节点:3
10 号节点的后继节点:1
如果看代码注释看不明白的话 ,现在来解释:
-
线索化的时候,就是要按照 中序遍历 的顺序,去找可以线索化的节点
中序遍历顺序:先左、自己、再右
我们主要的代码是在 自己这一块
-
确定前一个节点 pre
这个 pre 很难理解,对照下图进行理解
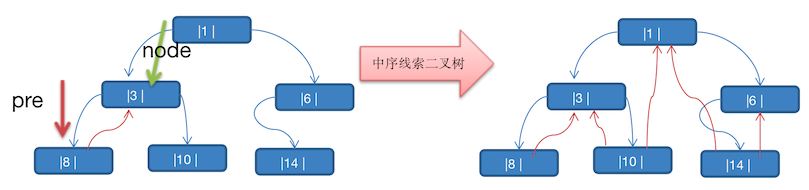
// 数列: 1,3,6,8,10,14 // 中序: 8,3,10,1,14,6 // 因为中序遍历,先遍历左边,所以 8 是第一个输出的节点 // 当 node = 8 时,pre 还没有被赋值过,则为空。这是正确的,因为 8 就是第一个节点 // 当 8 处理完成之后,处理 3 时 // 当 node = 3 时,pre 被赋值为 8 了。 -
设置前驱节点
难点的讲解在于 pre,解决了这里就简单了
如果当 node = 8 时,pre 还是 null,因为 8 就是中序的第一个节点。因此 8 没有前驱
如果当 node = 3 时,pre = 8,那么 3 是不符合线索化要求的,因为 8 是 3 的 left
-
设置后继节点
接上面的逻辑。
如果当 node = 8 时,本来 该给 8 设置他的后继节点,但是此时根本就获取不到节点 3,因为节点是单向的。
这里就得利用前一个节点 pre,
当 node=3 时,pre = 8,这时就可以为节点 8 处理它的后继节点了,因为根据中序的顺序,左、自己、后。那么自己(node)一定是前一个的后继。只要前一个的 right 为 null,就符合线索化了
上述最难的 3 个点说明,请对照上图看,先看一遍代码,再看说明。然后去 debug 你就了解了。
遍历线索化二叉树
结合图示来看思路说明最直观
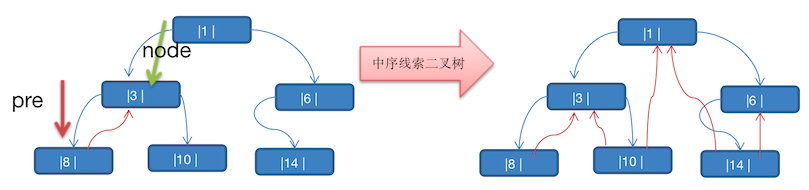
对于原来的中序遍历来说,无法使用了,因为左右节点再也不为空了。这里直接利用线索化节点提供的线索,找到他的后继节点遍历,思路如下:
-
首先找到它的第一个节点,并打印它
中序遍历,先左,所以一直往左找,直到 left 为 null 时,则是第一个节点
-
然后看它的 right节点是否为线索化节点,是的话则打印它
因为:如果 right 是一个线索化节点,也就是 right 是当前节点的 后继节点,可以直接打印。
这里判断是否为线索化节点就得用到新添加的那两个属性了,
leftType:左节点的类型:0:左子树,1:前驱节点rightType:右节点的类型:0:右子树,1:后继节点
-
right 如果是一个普通节点,那么就直接处理它的右侧节点
因为:按照中序遍历顺序,左、自己、右,这里就理所当然是右了
看描述索然无味,结合下面的代码来看,就比较清楚了
/**
* 遍历线索化二叉树
*/
public void threadedList() {
// 前面线索化使用的是中序,这里也同样要用中序的方式
// 但是不适合使用之前那种递归了
HeroNode node = root;
while (node != null) {
// 中序:左、自己、右
// 数列: 1,3,6,8,10,14
// 中序: 8,3,10,1,14,6
// 那么先找到左边的第一个线索化节点,也就是 8. 对照图示理解,比较容易
while (node.leftType == 0) {
node = node.left;
}
// 找到这个线索化节点之后,打印它
System.out.println(node);
// 如果该节点右子节点也是线索化节点,则打印它
while (node.rightType == 1) {
node = node.right;
System.out.println(node);
}
//否则
// 到达这里,就说明遇到的不是一个 线索化节点了
// 而且,按中序的顺序来看:这里应该处理右侧了
node = node.right;
}
}
测试
/**
* 线索化遍历测试
*/
@Test
public void threadedListTest() {
// 1,3,6,8,10,14
HeroNode n1 = new HeroNode(1, "宋江");
HeroNode n3 = new HeroNode(3, "无用");
HeroNode n6 = new HeroNode(6, "卢俊");
HeroNode n8 = new HeroNode(8, "林冲2");
HeroNode n10 = new HeroNode(10, "林冲3");
HeroNode n14 = new HeroNode(14, "林冲4");
n1.left = n3;
n1.right = n6;
n3.left = n8;
n3.right = n10;
n6.left = n14;
ThreadedBinaryTree tree = new ThreadedBinaryTree();
tree.root = n1;
tree.threadeNodes();
tree.threadedList(); // 8,3,10,1,14,6
}
输出信息
HeroNode{id=8, name='林冲2'}
HeroNode{id=3, name='无用'}
HeroNode{id=10, name='林冲3'}
HeroNode{id=1, name='宋江'}
HeroNode{id=14, name='林冲4'}
HeroNode{id=6, name='卢俊'}
前序线索化
public void preOrderThreadeNodes() {
preOrderThreadeNodes(root);
}
/**
* 前序线索化二叉树
*/
public void preOrderThreadeNodes(HeroNode node) {
// 前序:自己、左(递归)、右(递归)
// 数列: 1,3,6,8,10,14
// 前序: 1,3,8,10,6,14
if (node == null) {
return;
}
System.out.println(node);
// 当自己的 left 节点为空,则可以线索化
if (node.left == null) {
node.left = pre;
node.leftType = 1;
}
// 当前一个节点 right 为空,则可以把自己设置为前一个节点的后继节点
if (pre != null && pre.right == null) {
pre.right = node;
pre.rightType = 1;
}
// 因为是前序,因此 pre 保存的是自己
// 到下一个节点的时候,下一个节点如果是线索化节点 ,才能将自己作为它的前驱节点
pre = node;
// 那么继续往左,查找符合可以线索化的节点
// 因为先处理的自己,如果 left == null,就已经线索化了
// 再往左的时候,就不能直接进入了
// 需要判定,如果不是线索化节点,再进入
// 比如:当前节点 8,前驱 left 被设置为了 3
// 这里节点 8 的 left 就为 1 了,就不能继续递归,否则又回到了节点 3 上
// 导致死循环了。
if (node.leftType == 0) {
preOrderThreadeNodes(node.left);
}
if (node.rightType == 0) {
preOrderThreadeNodes(node.right);
}
}
这里代码相对于中序线索化来说,难点在于:什么时候该继续往左查找,什么时候该继续往右查找。
测试
/**
* 前序线索化
*/
@Test
public void preOrderThreadedNodesTest() {
// 1,3,6,8,10,14
HeroNode n1 = new HeroNode(1, "宋江");
HeroNode n3 = new HeroNode(3, "无用");
HeroNode n6 = new HeroNode(6, "卢俊");
HeroNode n8 = new HeroNode(8, "林冲2");
HeroNode n10 = new HeroNode(10, "林冲3");
HeroNode n14 = new HeroNode(14, "林冲4");
n1.left = n3;
n1.right = n6;
n3.left = n8;
n3.right = n10;
n6.left = n14;
ThreadedBinaryTree tree = new ThreadedBinaryTree();
tree.root = n1;
tree.preOrderThreadeNodes();
// 验证: 前序顺序: 1,3,8,10,6,14
HeroNode left = n10.left;
HeroNode right = n10.right;
System.out.println("10 号节点的前驱节点:" + left.id); // 8
System.out.println("10 号节点的后继节点:" + right.id); // 6
left = n6.left;
right = n6.right;
System.out.println("6 号节点的前驱节点:" + left.id); // 14, 普通节点
System.out.println("6 号节点的后继节点:" + right.id); // 14,线索化节点
}
输出
HeroNode{id=1, name='宋江'}
HeroNode{id=3, name='无用'}
HeroNode{id=8, name='林冲2'}
HeroNode{id=10, name='林冲3'}
HeroNode{id=6, name='卢俊'}
HeroNode{id=14, name='林冲4'}
10 号节点的前驱节点:8
10 号节点的后继节点:6
6 号节点的前驱节点:14 注意:这里不是前驱,而是正常的一个left节点
6 号节点的后继节点:14
可以看到,我们线索化二叉树的时候,是按照前序的顺序 1,3,8,10,6,14 的顺序遍历查找处理的。处理之后的 6 号节点两个都是一样的,但是 left 是正常的节点 14,right 是线索化节点 14,不明白可以结合下图想一下

前序线索化遍历
前序线索化遍历,还是要记住它的特点是:自己、左(递归)、右(递归),那么遍历思路如下:
- 先打印自己
- 再左递归打印
- 直到遇到一个节点有 right 且是后继节点,则直接跳转到该后继节点,继续打印
- 如果遇到的是一个普通节点,则打印该普通节点,完成一轮循环,进入到下一轮,从第 1 步开始
/**
* 前序线索化二叉树遍历
*/
public void preOrderThreadeList() {
HeroNode node = root;
// 最后一个节点无后继节点,就会退出了
// 前序:自己、左(递归)、右(递归)
while (node != null) {
// 先打印自己
System.out.println(node);
while (node.leftType == 0) {
node = node.left;
System.out.println(node);
}
while (node.rightType == 1) {
node = node.right;
System.out.println(node);
}
node = node.right;
}
}
测试代码
@Test
public void preOrderThreadeListTest() {
ThreadedBinaryTree tree = buildTree();
tree.preOrderThreadeNodes();
System.out.println("前序线索化遍历");
tree.preOrderThreadeList(); // 1,3,8,10,6,14
}
测试输出
HeroNode{id=1, name='宋江'}
HeroNode{id=3, name='无用'}
HeroNode{id=8, name='林冲2'}
HeroNode{id=10, name='林冲3'}
HeroNode{id=6, name='卢俊'}
HeroNode{id=14, name='林冲4'}
前序线索化遍历
HeroNode{id=1, name='宋江'}
HeroNode{id=3, name='无用'}
HeroNode{id=8, name='林冲2'}
HeroNode{id=10, name='林冲3'}
HeroNode{id=6, name='卢俊'}
HeroNode{id=14, name='林冲4'}
总结
还有一个后序线索化,这里不写了,从前序、中序获取到几个重要的点:
-
线索化时:
-
根据不同的「序」,如何进行遍历的同时,处理线索化节点
对于中序来说:
- 先递归到最左节点
- 开始线索化
- 再递归到最右节点
它的顺序:先左(递归)、自己(node)、再右(递归)
对于前序来说:
- 开始线索化
- 一直往左递归
- 一直往右递归
它的顺序:自己(node)、左(递归)、右(递归)
-
根据不同的「序」,考虑如何跳过或进入下一个节点,因为要考虑前驱和后继
「序」:前、中、后序
- 中序:由于它的顺序,第一个线索化节点,就是他的顺序的第一个节点,不用管接下来遇到的节点是否已经线索化过了,这是由于它天然的顺序,已经线索化过的节点,不会在下一次处理
- 前序:由于它的顺序,第一个顺序输出的节点,并不是第一个线索化节点。所以它需要对他的 左右节点进行类型判定,是普通节点的话,再按:自己、左、右的顺序进行左、右进行递归,因为下一次出现的节点有可能是已经线索化过的节点,如果不进行判定,就会导致又回到了已经遍历过的节点。就会导致死循环了。这里可以结合上图思考一下。
-
-
遍历线索化时:基本上和线索化时的「序」一起去考虑,何时该进行输出?什么时候遇到后继节点时,跳转到后继节点处理。最重要的一点是:遍历时,不用考虑前驱节点,之后考虑何时通过后继节点进行跳转输出(看遍历代码就懂)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号