MySQL数据类型和约束条件
存储引擎
现实生活中我们用来存储数据的文件有不同的类型,每种文件类型对应各自不同的处理机制:比如处理文本用txt类型,处理表格用excel,处理图片用png等。
数据库中的表也应该有不同的类型,表的类型不同,会对应mysql不同的存取机制,表类型又称为存储引擎,mysql根据不同的表类型会有不同的处理机制 存储引擎说白了就是如何存储数据、如何为存储的数据建立索引和如何更新、查询数据等技术的实现方 法。因为在关系数据库中数据的存储是以表的形式存储的,所以存储引擎也可以称为表类型(即存储和 操作此表的类型)。
在Oracle 和SQL Server等数据库中只有一种存储引擎,所有数据存储管理机制都是一样的。而MySql 数据库提供了多种存储引擎。用户可以根据不同的需求为数据表选择不同的存储引擎,用户也可以根据自己的需要编写自己的存储引擎。
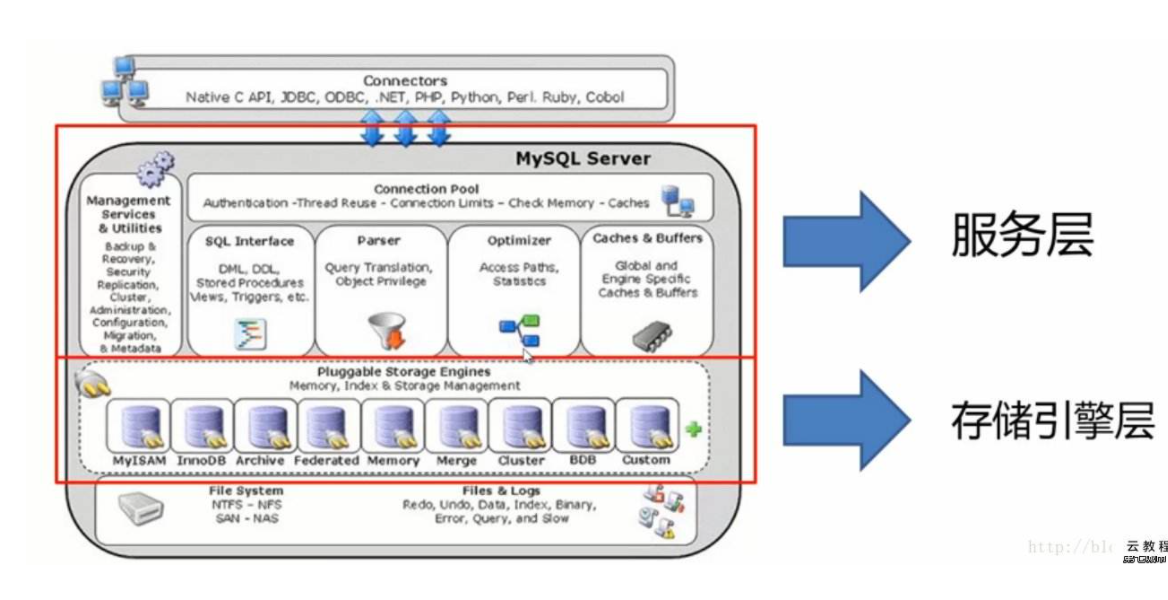
MySQL主要存储引擎
-
-
-
Innodb
是MySQL5.5版本及之后默认的存储引擎
存储数据更加的安全
-
myisam
是MySQL5.5版本之前默认的存储引擎
速度要比Innodb更快 但是数据不够安全
-
memory
内存引擎(数据全部存放在内存中) 断电数据丢失
-
blackhole
无论存什么,都立刻消失(黑洞)
-
-
存储结果的异同
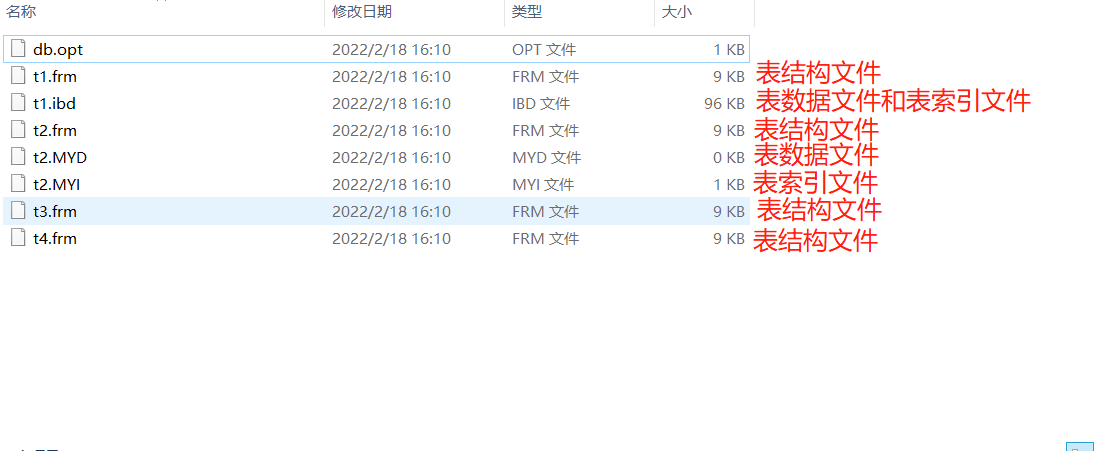
# 查看所有的存储引擎 show engines; # 不同的存储引擎在存储表的时候 异同点 create table t1(id int) engine=innodb; create table t2(id int) engine=myisam; create table t3(id int) engine=blackhole; create table t4(id int) engine=memory; # 存数据 insert into t1 values(1); insert into t2 values(1); insert into t3 values(1); insert into t4 values(1);
MyISAM会创建三个文件
.frm 表结构文件
.MYD 表数据文件
.MYI 表索引文件(索引是用来加快数据查询的)
InnoDB会创建两个文件
.frm 表结构文件
.ibd 表数据和表索引文件
memory
.frm 表结构文件
blackhole
.frm 表结构文件
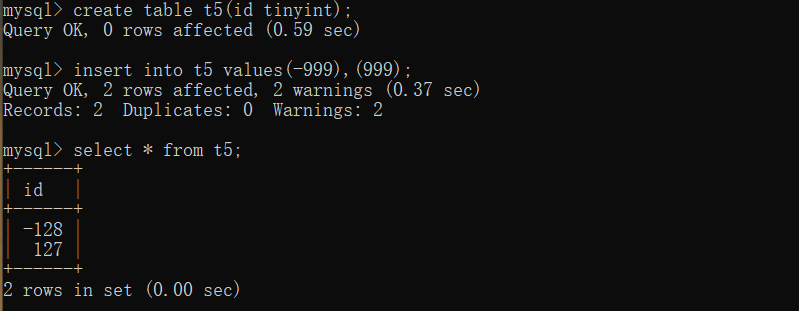
1.整型
分类:
tinyint smallint int bigint
不同的int类型能够存储的数字范围是不一样的
1.要注意是否存负数(正负号需要占一个比特位)
2.针对手机号码只能用bigint
所有的int类型默认都需要正负号
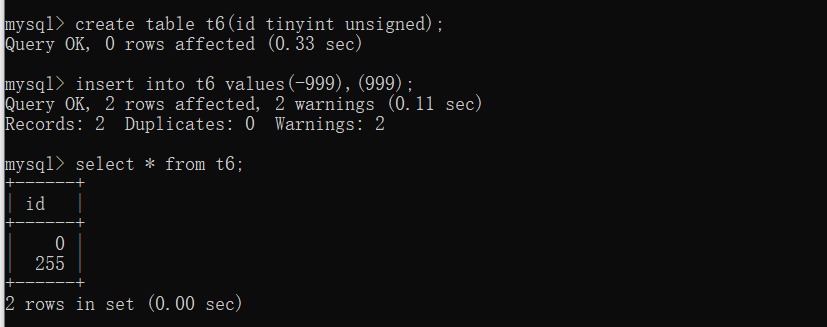
可以修改设置默认不加正负号。
在字段后加unsigned
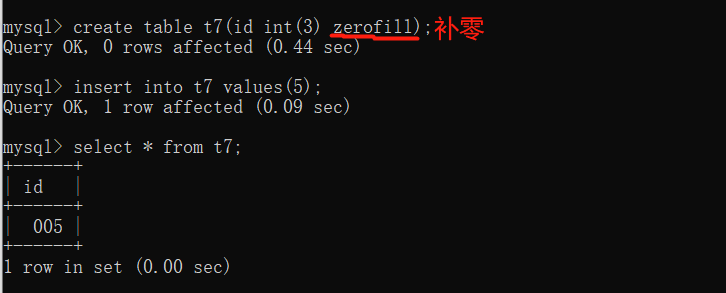
2.浮点型
分类:
float double decimal
存储限制:
float(255,30) # 总共255位 小数位占30位
double(255,30) # 总共255位 小数位占30位
decimal(65,30) # 总共65位 小数位占30位
精确度对比:
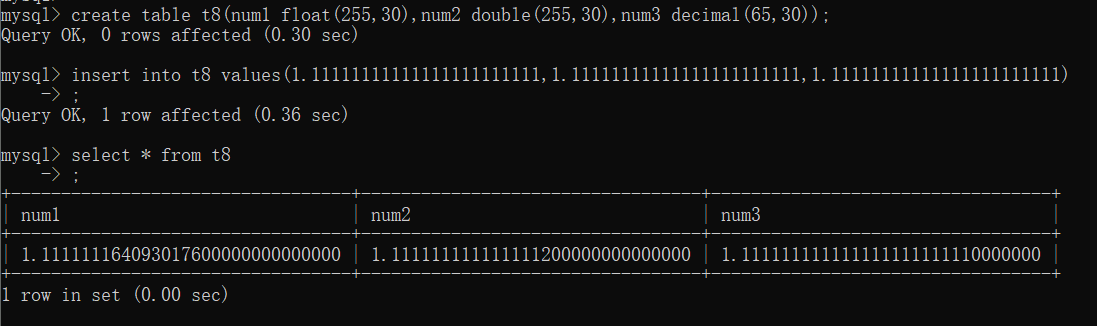
可见精确度float<double<decimmal。
3.字符类型
字符类型分两类:
char(4):
定长类型 最多只能存四个字符 多了报错少了自动空格填充至四个。
varchar(4)
变长类型 最多只能存四个字符 多了报错少了有几个则存几个。
注:针对5.6版本超出范围不会报错 而是自动帮你截取并保存,若要修改此行为需要更改设置。
方式1:修改配置文件(永久)
方式2:命令修改(暂时)
show variables like '%mode%'
set session # 当前窗口有效
set global # 当前服务端有效
set gloabl sql_mode = 'strict_trans_tables'
修改完毕后退出客户端重新进入即可
研究定长与变长特性
insert into t10 values(1,'j');
insert into t11 values(1,'t');
统计某个字段数据的长度 char_length()
底层确实会填充 但是取出来的时候又会自动去除,因此需要修改设置取消自动去除。
set global sql_mode = 'strict_trans_tables,pad_char_to_full_length'
create table user( id int, name char(16), gender enum('male','female','others') ); insert into user values(1,'tom','male'); #正常 insert into user values(2,'jerry','xxxxooo'); #报错 # 枚举字段 后期在存数据的时候只能从枚举里面选择一个存储 create table people( id int, name char(16), gender enum('male','female','others'), hobby set('read','play','music') ); insert into people values(1,'tom','male','read'); #正常 insert into people values(2,'jerry','female','play,music'); #正常 insert into people values(3,'marry','others','movie'); #报错 # 集合可以只写一个 但是不能写没有列举的
5.时间类型
分类:
date 年月日
datetime 年月日时分秒
time 时分秒
year 年份
create table client( id int, name varchar(32), reg_time date, birth datetime, study_time time, join_time year ); insert into client values(1,'tom','2000-11-11','2000-1-21 11:11:11','11:11:11',1995);
创建表的完整语法
create table 表名( 字段名1 字段类型(数字) 约束条件, 字段名2 字段类型(数字) 约束条件, 字段名3 字段类型(数字) 约束条件 ); """ 1.字段名和字段类型是必须的 2.数字和约束条件是可选的 并且 约束条件可以有多个空格隔开即可 3.最后一个语句的结尾不要加逗号 """
约束条件
约束条件相当于在字段类型的基础上添加额外的约束。
-
-
-
UNSIGNED 数字无符号,即0开始
-
ZEROFILL 展示数字长度小于设置的大小用0填充
-
NOT NULL 或 NULL(默认) 非空或允许为空。使用NULL约束条件的字段不传值时默认为NULL,设置为NOT NULL不传值便会报错。
-
DEFAULT 默认值,即插入数据不给该字段传值时的默认值。
-
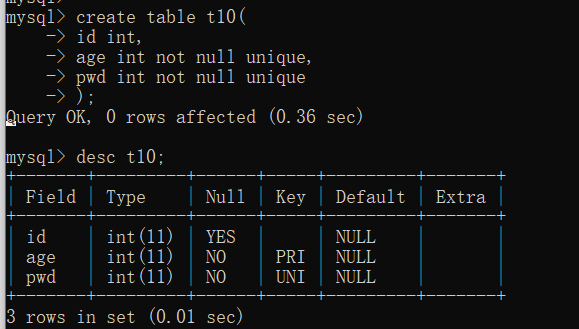
UNIQUE
-
-
# 单列唯一 # 设置约束条件unique的字段其值只能唯一,不能重复 create table t1( id int, name varchar(32) unique ); # 联合唯一(必须放在最后) # 联合的字段其值的组合只能唯一,不能重复 create table t2( id int, host varchar(32), port int, unique(host,port) );
主键
PRIMARY KEY(主键)
primary key从约束层面上来说,相当于是NOT NULL+UNIQUE。且在此基础上查询速度更快。
InnoDB存储引擎规定表有且只有一个主键。InnoDB是通过主键来构建表的,如果未设置主键和约束条件,InnoDB会采用隐藏的字段作为主键,但不再加快查询速度。如果未设置主键,但是设置了 NOT NULL和UNIQUE的字段将自动升级为主键。
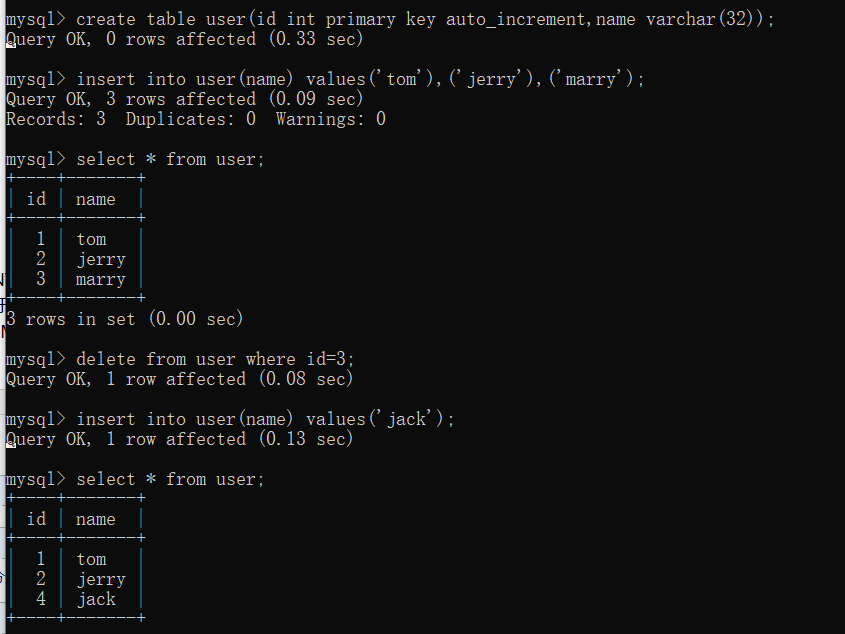
AUTO_INCREMENT(自增)
自增,只能用于数字类型。一般配合主键使用,设置此约束条件的字段在我们插入新行后会自动+1。
AUTO_INCREMENT设置的字段在我们删除一条数据再插入一条数据后,其自增数不会自减。
如果想要重置需需要使用truncate关键字
truncate 表名 # 清空表数据并且重置主键值
外键(foreign key)
外键的作用
在建立一张表的时候,如果一张表的字段过多,那没就有可能存在以下问题:
1 该表的组织结构不是很清晰(可忽视)
2 浪费硬盘空间(可忽视)
3 数据的扩展性极差(无法忽视的)
解决上述问题的方式是将表拆分,但是拆分之后又无法判断拆分之后的表之间的关系,此时就需要用到外键。
外键就是用来帮助我们建立表与表之间关系的,简单的理解为该字段可以让你去到其他表中查找数据。
句式:
foreign key(外键字段) references 被关联表名(要绑定的字段字段)
外键的约束条件
1.在创建表的时候 需要先创建被关联表(没有外键字段的表)
2.在插入新数据的时候 应该先确保被关联表中有数据
3.在插入新数据的时候 外键字段只能填写被关联表中已经存在的数据
4.在修改和删除被关联表中的数据的时候 无法直接操作
如果想要数据之间自动修改和删除需要添加额外的配置:
on update cascade # 级联更新 on delete cascade # 级联删除
注:由于外键有实质性的诸多约束 当表特别多的时候外键的增多反而会增加耦合程度。
所以在实际开发项目中 有时候并不会使用外键创建表关系。
而是通过SQL语句层面 人为实现类似外键的效果。
表与表之间建关系
表与表之间的关系只有4种:
1.一对多
2.多对多
3.一对一
4.没有关系
判断表之间关系建议使用换位思考的方式。
一对多表关系
# 部门表 create table dep( id int primary key auto_increment, dep_name varchar(32), dep_desc varchar(300) ); # 员工表 create table emp( id int primary key auto_increment, name varchar(32), age int, dep_id int, foreign key(dep_id) references dep(id) #建立外键 on update cascade #级联更新 on delete cascade #级联删除 ); insert into dep(dep_name,dep_desc) values('开发部','数据开发'),('财务部','发工资'),('销售部','对外销售'); insert into emp(name,age,dep_id) values('tom',18,1),('jerry',19,1),('marry',58,2);
多对多表关系
create table book( id int primary key auto_increment, book_name varchar(32), price float(6,2) ); create table author( id int primary key auto_increment, author_name varchar(32), age int ); create table writings( id int primary key auto_increment, book_id int,author_id int, foreign key(book_id) references book(id) on update cascade on delete cascade, foreign key(author_id) references author(id) on update cascade on delete cascade ); insert into book(book_name,price) values('python',200),('linux',300),('js',100); insert into author(author_name,age) values('tom',18),('jerry',36); insert into writings(book_id,author_id) values(1,1),(2,2),(3,1),(3,2);
一对一表关系
create table author_detail( id int primary key auto_increment, age int, adress varchar(50), phone bigint ); create table author_brief( id int primary key auto_increment, name varchar(32), author_id int unique, foreign key(author_id) references author_detail(id) on update cascade on delete cascade ); insert into author_detail(age,adress,phone) values(18,'xx省xx市',1234567910); insert into author_brief(name,author_id) values('tom',1);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号