

Flink sql 之 两阶段聚合与 TwoStageOptimizedAggregateRule(源码分析)
本文源码基于flink1.14
上一篇文章分析了《flink的minibatch微批处理》的源码
乘热打铁分析一下两阶段聚合的源码,因为使用两阶段要先开启minibatch,至于为什么后面会分析到
两阶段聚合的原理,还是简单提一下
如下图,当聚合发生热点的时候,可以在聚合前,先进行一个本地的聚合,先减小数据量,后接正常的数据交换以后聚合,来达到一个解热点的目的,
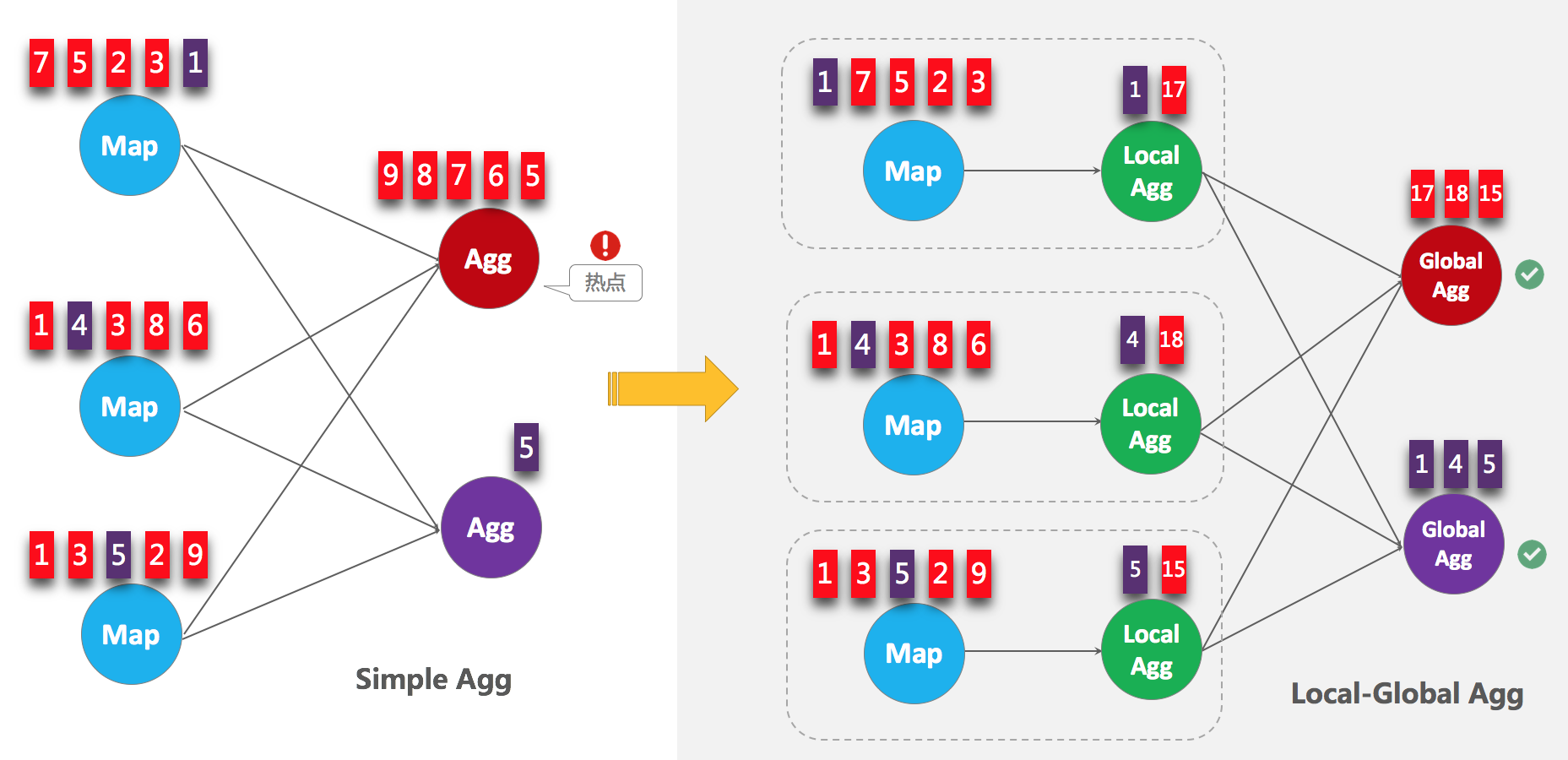
先来看下两阶段聚合的Calcite优化rule

看下什么情况会匹配上

并且在onmatch方法中会判断开启了minibatch,以及二阶段聚合的时候会调用
来看下具体逻辑match方法
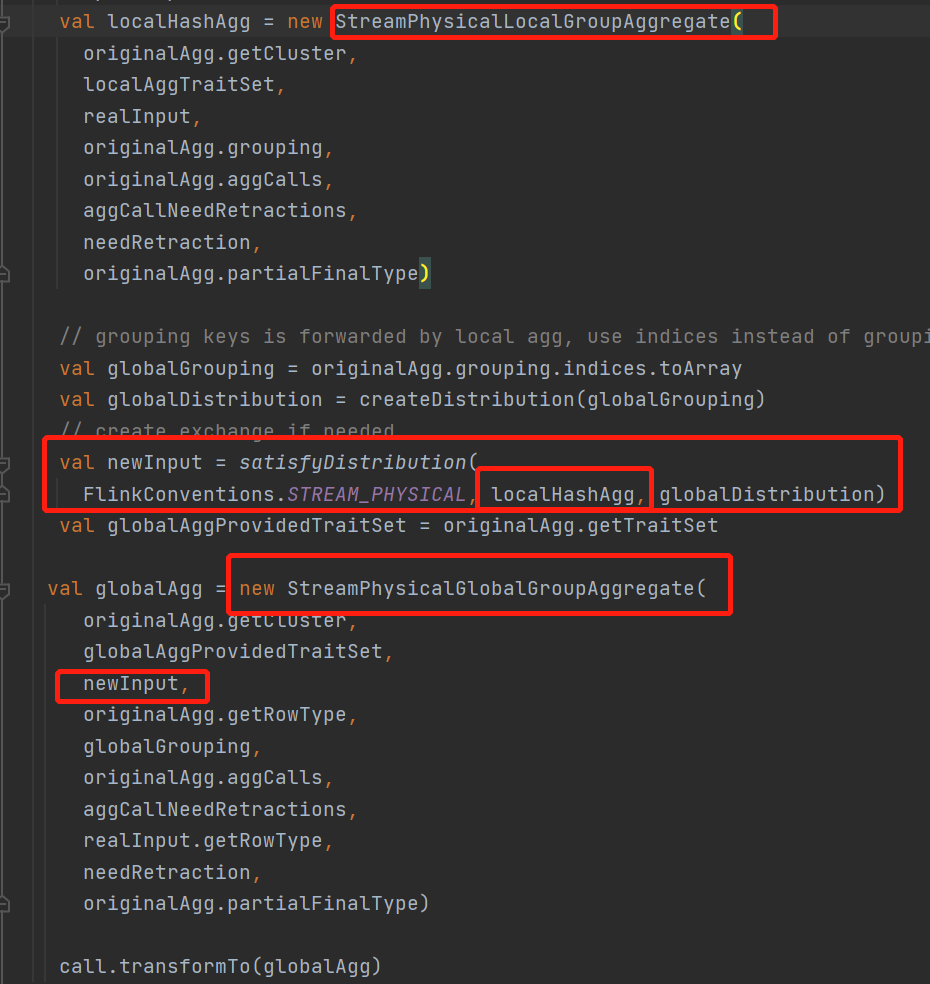
整个两阶段聚合会将原来的一个StreamPhysicalGroupAggregate物理节点,转换成一个
StreamPhysicalLocalGroupAggregate本地聚合节点 + StreamPhysicalGlobalGroupAggregate聚合节点
来看下这个新添加的StreamPhysicalLocalGroupAggregate本地聚合算子的计算逻辑是什么样子的
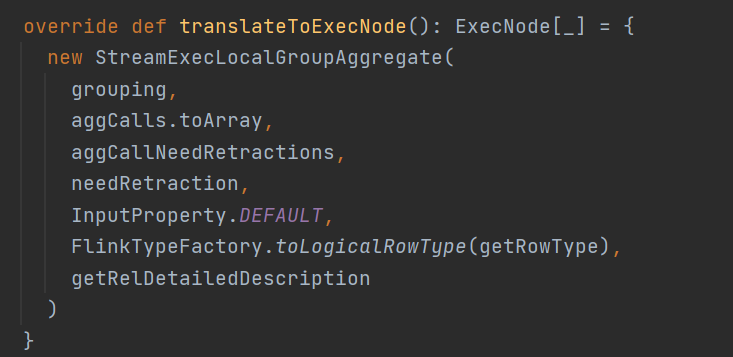
StreamExecLocalGroupAggragate就是StreamPhysicalLocalGroupAggregate本地聚合具体的ExecNode节点了
来看下具体的operator
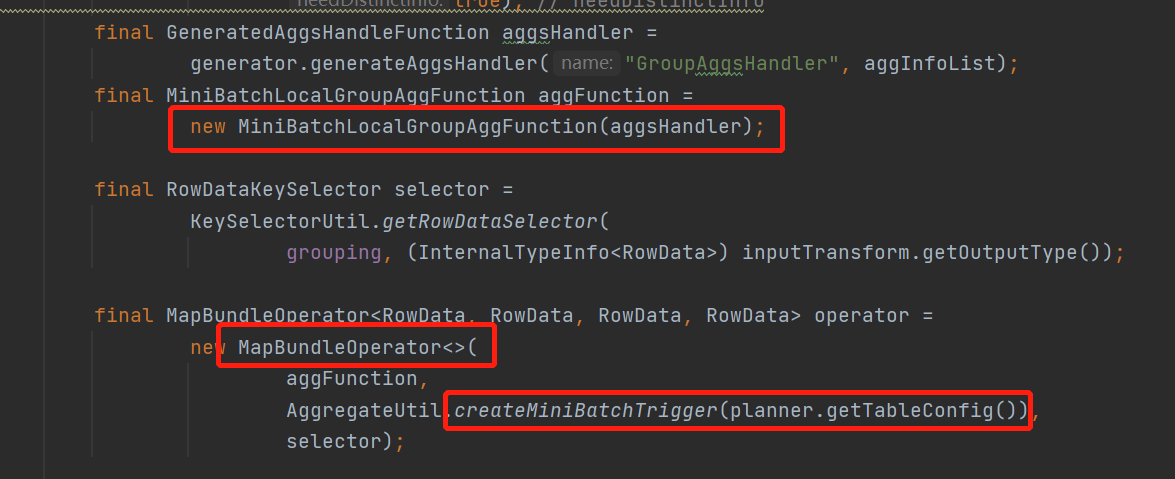
看到这里是不是看到了熟悉的 MapBundleOperator ,如果看过上一篇minibatch优化的就知道,两阶段提交也是使用的这个有界operator作为抽象
在了解一下这个MapBundleOperator
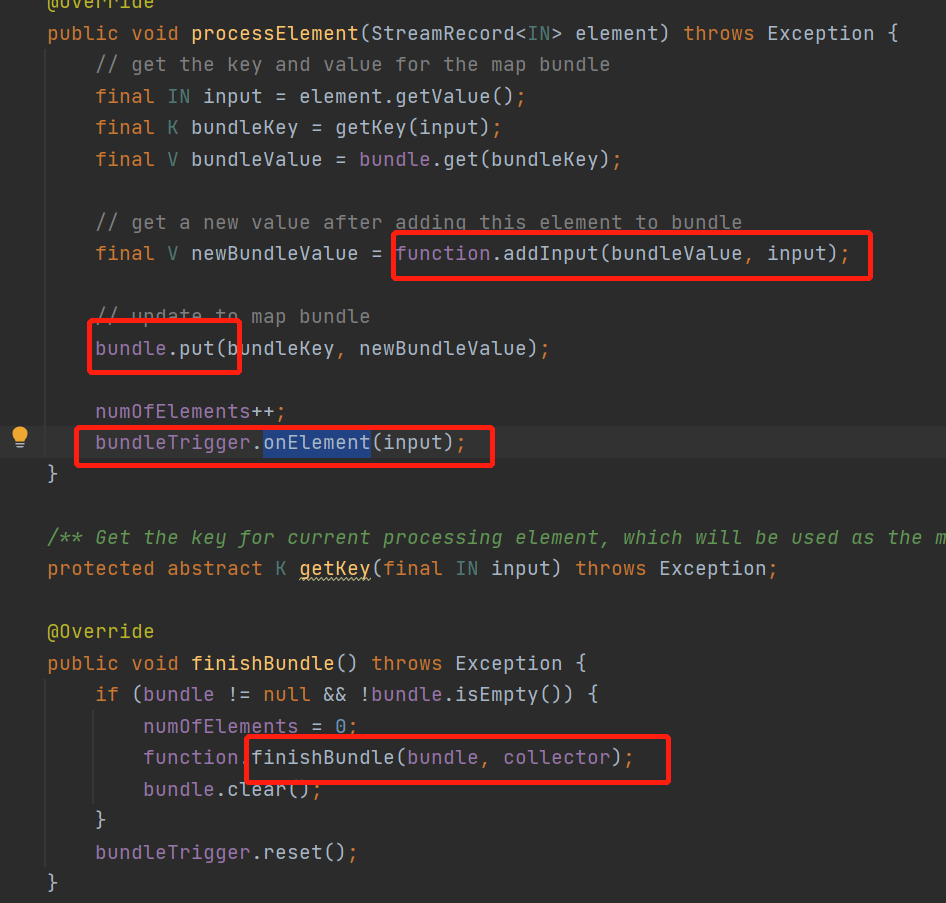
就是每来一条数据,都会调用传入的fun的addInput方法
然后把每个key的结果put保存在一个本地变量,就是个map<Rowdata,Rowdata>里面
然后调用自己的trigger触发器,当这条数据可以触发触发器就会调用finishBundle
这里说到触发器,回到初始化mapBundle的时候通过createMiniBatchTrigger创建的一个minibatch的触发器,看看具体逻辑
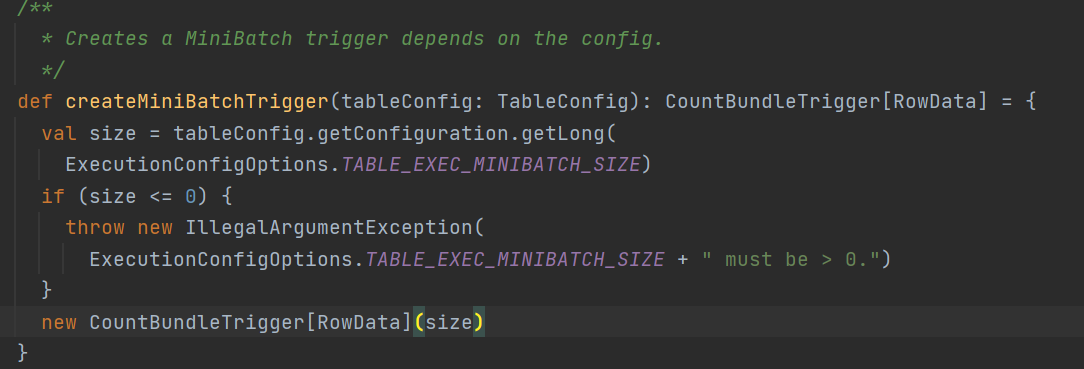
其实就是一个普通的count触发器,触发条件就是直接使用的minibatch配置的size参数, 所以这里知道了为什么两阶段提交要先开minibatch了
先看下每来一条数据会触发的addInput方法,在来看看攒一个批次后触发的finishBundle
minibatch会包装成一个MiniBatchLocalGroupAggFunction这个funtion的addInput来看看
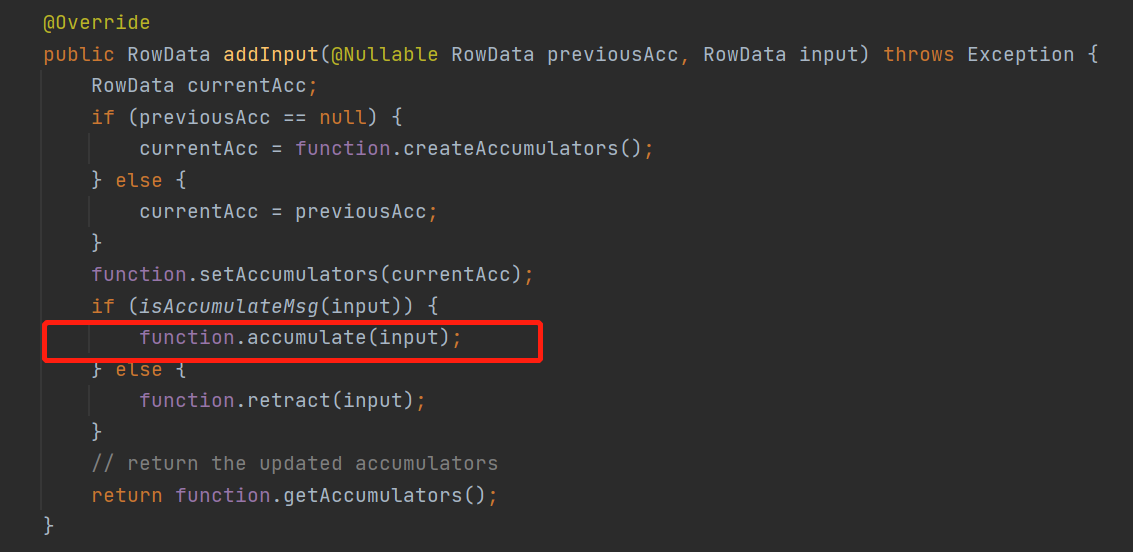
就是来一条数据直接调用聚合函数的accumulate直接计算结果了,虽然计算结果但是还没有往下游发送
来看下当攒一批后,集体是怎么往下游发送的 finishBundle 方法
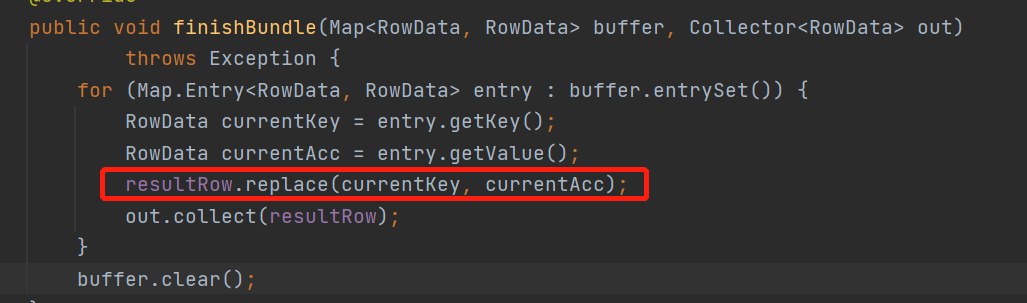
结果都已经计算好了,攒一个批次还能干嘛,就是把当前的计算结果往下游发送呗
那整个二次聚合的优化就讲完了
总结一下
sql会将agg拆成 localminiagg + agg
先在本地聚合localConbine一遍,再往下游发送
下游就正常聚合,优化了热点的问题

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步