

Flink sql 之 微批处理与MiniBatchIntervalInferRule (源码分析)
本文源码基于flink1.14
平台用户在使用我们的flinkSql时经常会开启minaBatch来优化状态读写
所以从源码的角度具体解读一下miniBatch的原理
先看一下flinksql是如何触发miniBatch的优化的
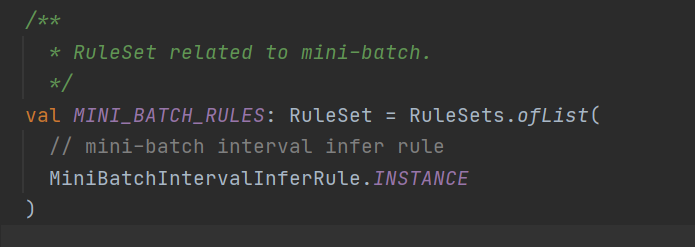
主要就是这个Calcite的rule了,来具体看一下
在对应的match方法中
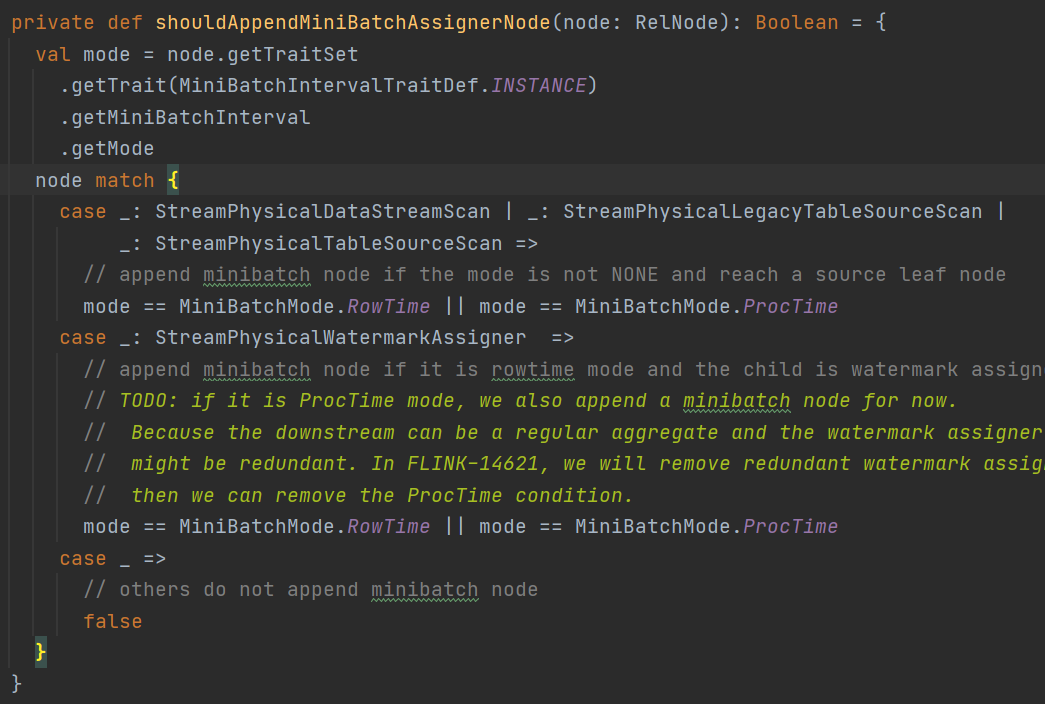
会根据miniBatch的类型判断,是否需要添加一个Assigner的节点
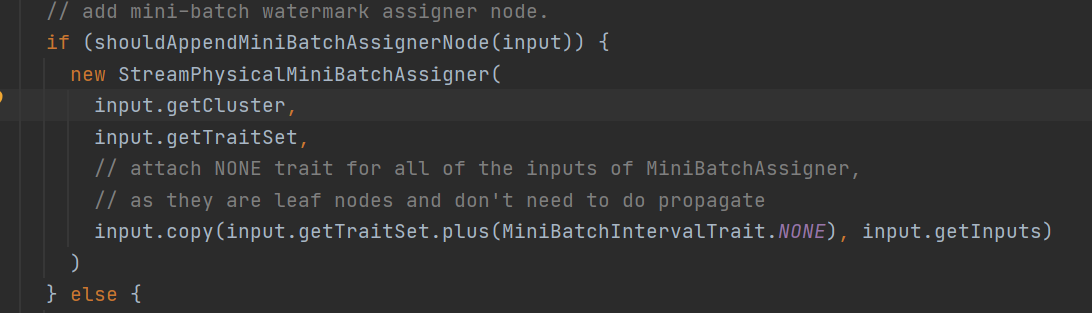
这个assigner是干嘛的呢?这个Assinger是一个execNode和窗口的assigner是不一样的,这里主要是为了发送水印的
没错,miniBatch攒一批的实现原理就是通过水印,来作为一批的标识
来具体看看

分为处理时间和事件时间
先看看处理时间
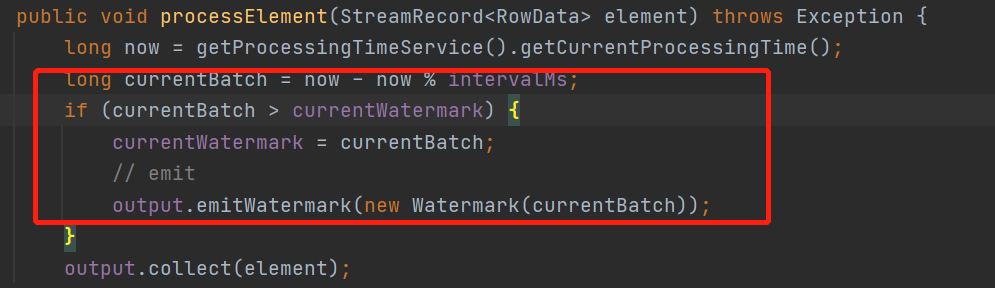
逻辑比较简单,就是当前微批的开始时间大于当前水印,就发送一个当前的微批的开始时间的水印
然后,事件时间的没什么意思,就是水印直接往下游转发了
接着,攒微批已经将完了,来看下具体聚合算子怎么优化微批计算的吧
来看个StreamExecGroupAggregate这个聚合ExecNode的逻辑
既然是execNode来直接看它的translateToPlanInternal()方法
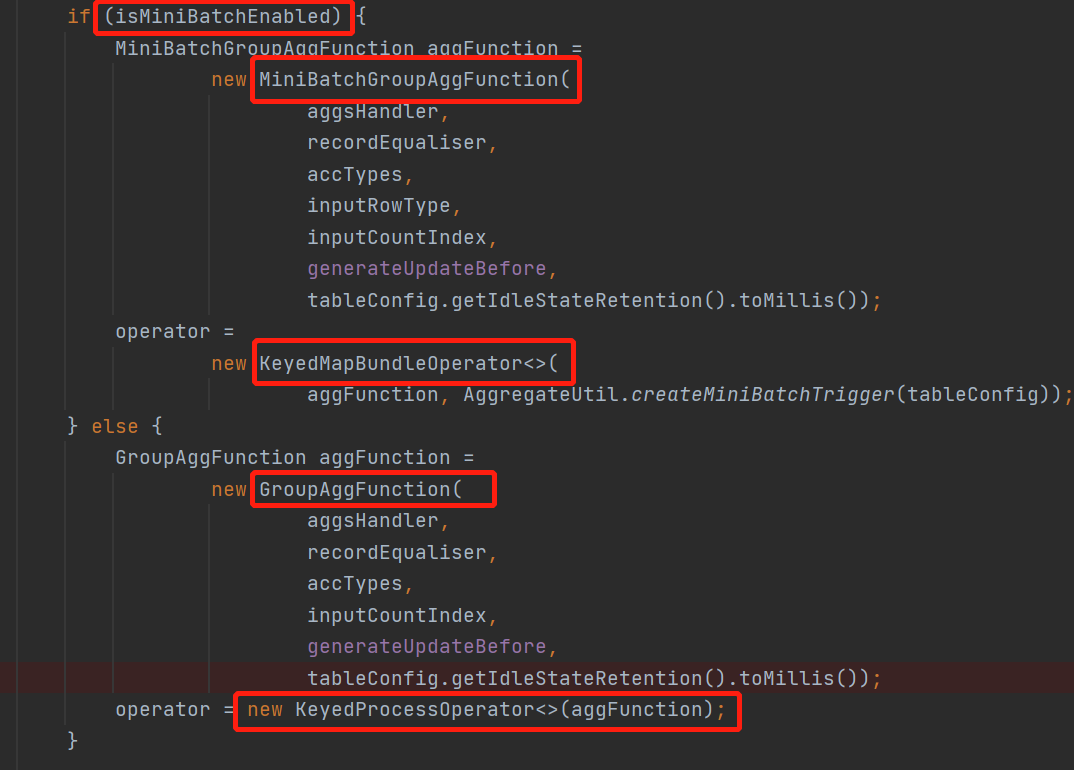
原来是直接在execNode里面做了特殊处理,不过也是,每个算子的优化都不一样也不太好抽象出来
这里还是 先看看不使用微批的时候是怎么处理的,然后来对比一下
没用微批这里是封装成了一个KeyedProcessOperator的算子,里面传的aggFunction直接就是一个KeyedProcessFunction
看下具体处理groupAggFunction
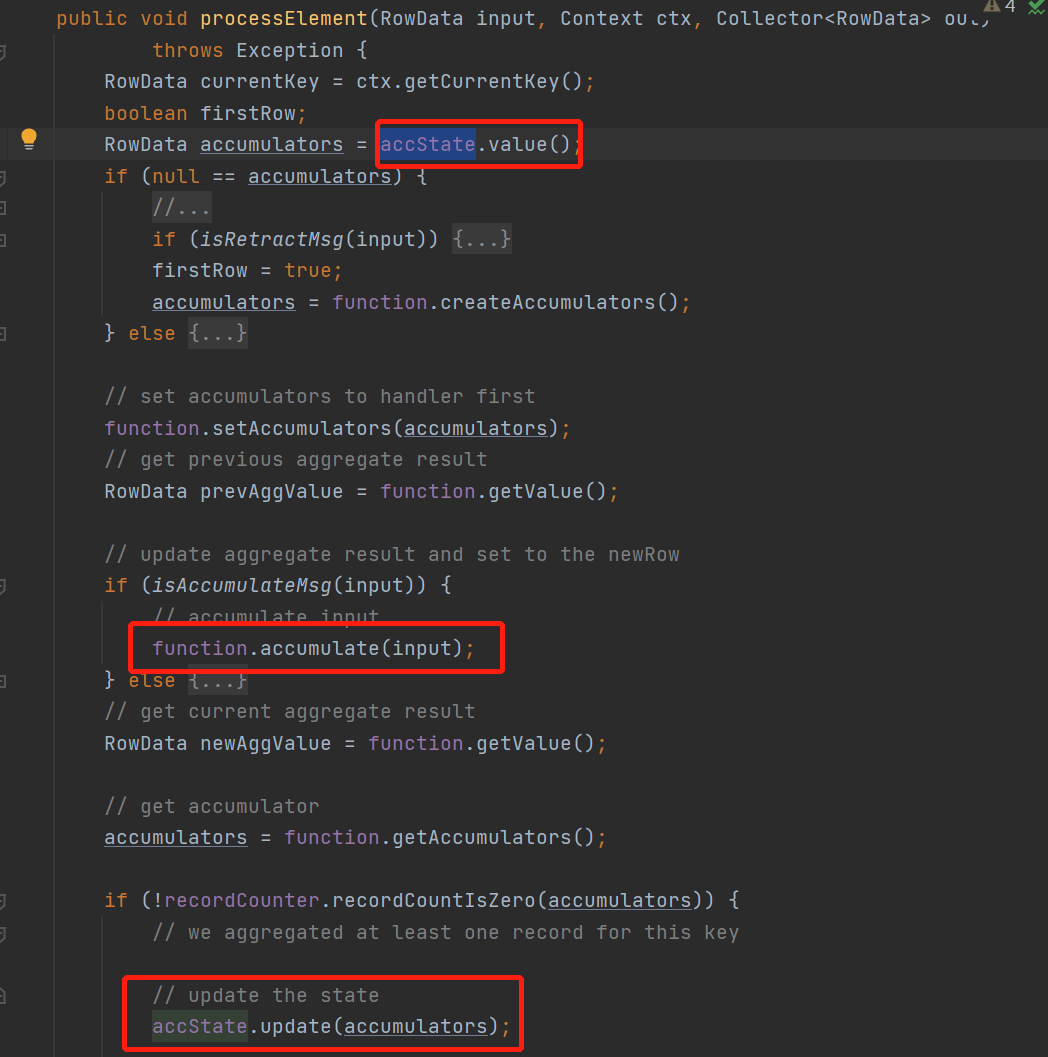
这里没有开minibatch的逻辑比较简单
每来一条数据,先读状态accState是一个valueState然后,调用聚合函数的accumlate来计算,然后用新得到的累加器更新状态
可以看到这样做的问题还是比较大的
第一,每一条数据都要读写状态开销很大
第二,每条数据都要调用计算,有很多虚函数的调用
因此,让我们看看MIniBatch是如何做的吧
回到上面,我们看到MiniBatch是创建的一个KeyedMapBundleOperator,里面的参数是MiniBatchGroupAggFunction
看下KeyedMapBundleOperator
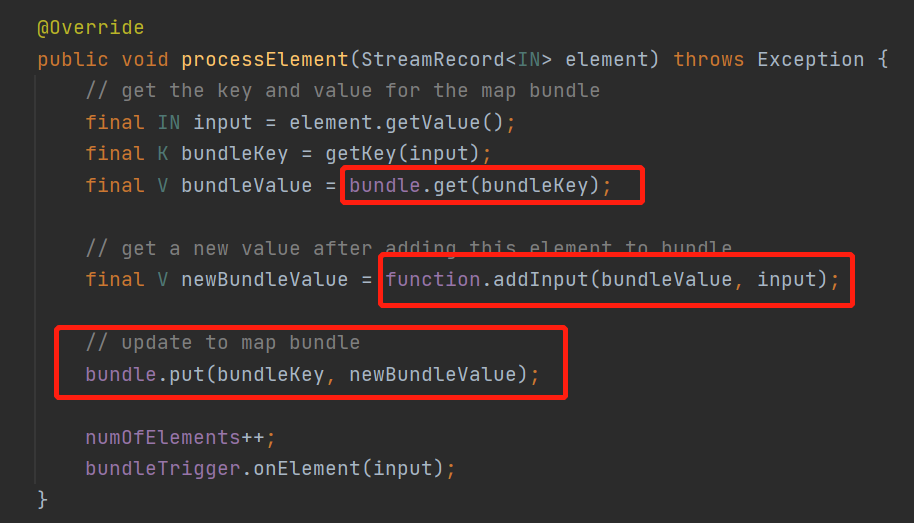
先从一个bundle获取和数据同key的数据,来看下这个bundle是什么

ok,就是一个本地map,然后走addInput()
来看下MiniBatchGroupAggFunction的addInput方法

其实就是把,来的数据加到map对应key的Value是一个list里面去了
最后来看当微批攒够触发onTrigger会走到finishBundle()方法

先从buffer获取每一个key对应的value是一个list
然后读取状态state数据
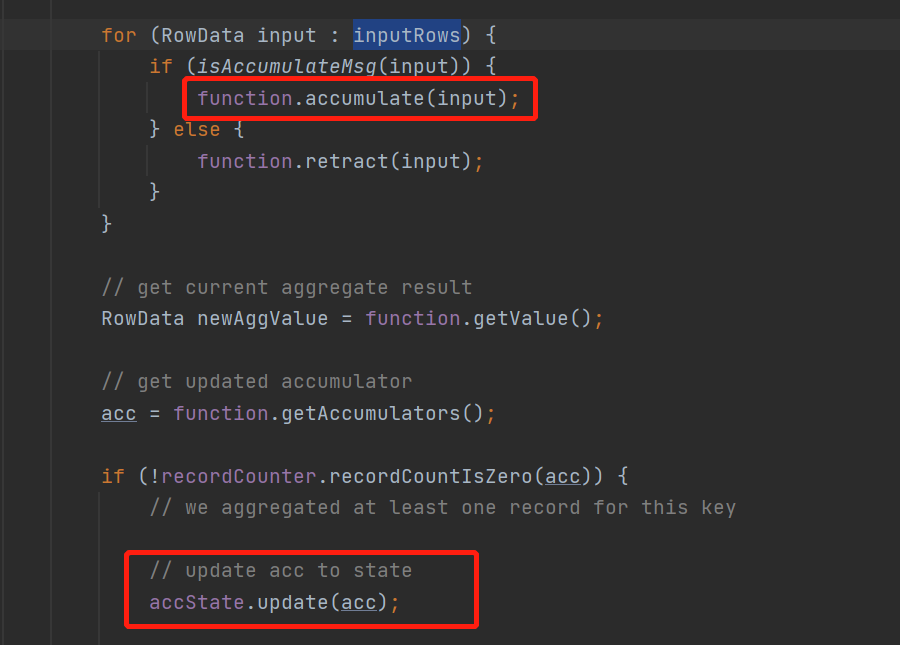
直接for循环遍历微批的数据
然后调用聚合函数的accumulate不停计算
最后将计算好的累加器accumulator存到状态里面去
是不是很简单
这样微批处理就完成了,减少了状态的频繁访问,是一个很不错的优化

