
Flink sql 之 join 与 StreamPhysicalJoinRule (源码解析)
源码分析基于flink1.14
Join是flink中最常用的操作之一,但是如果滥用的话会有很多的性能问题,了解一下Flink源码的实现原理是非常有必要的
本文的join主要是指flink sql的Regular join 也就是平时我们的双流join中普通的full join ,left join,right join
先找到calcite的relNode转换rule
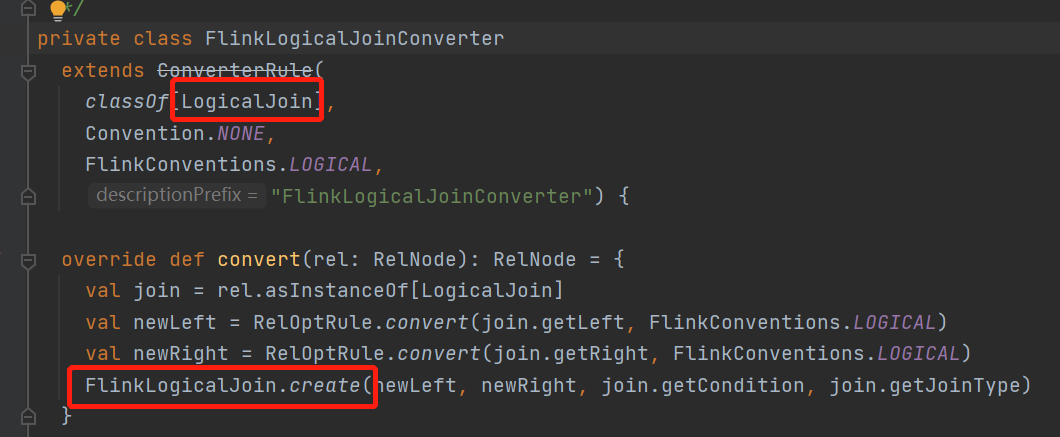
会将逻辑节点logiceJoin转换成flink的FlinkLogicalJoin
接着看下哪里Rule会转换这个FlinkLogicalJoin
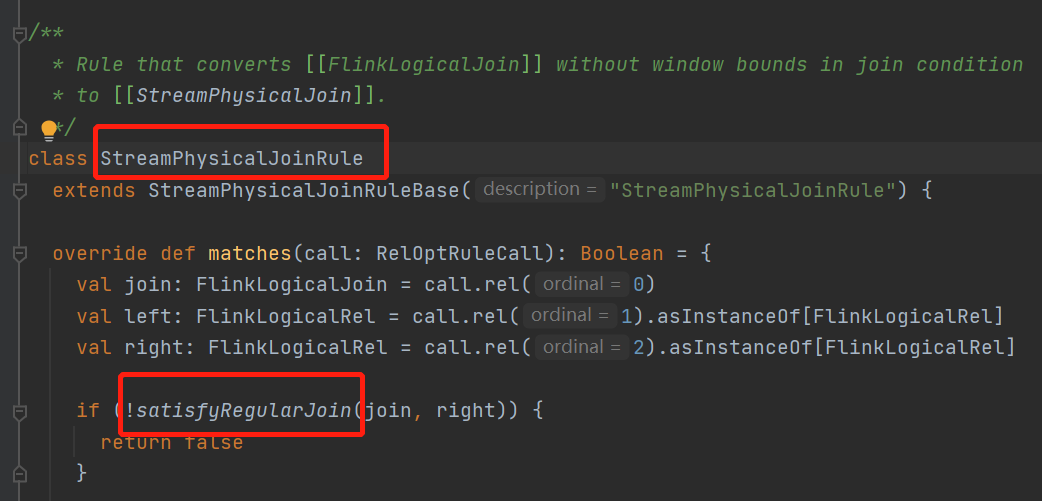
这里会将这种普通join也就是regularJoin给匹配上
条件是

不是这三种join,并且
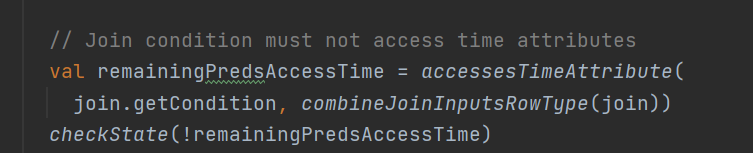
也不能join表达式包含时间属性
匹配上次rule以后,接着

返回了StreamPhysicalJoin这个StreamPhysicalRel是个物理节点
他的translateToExecNode方法会返回StreamExecJoin,这个类就是我们具体的逻辑了
来看一下
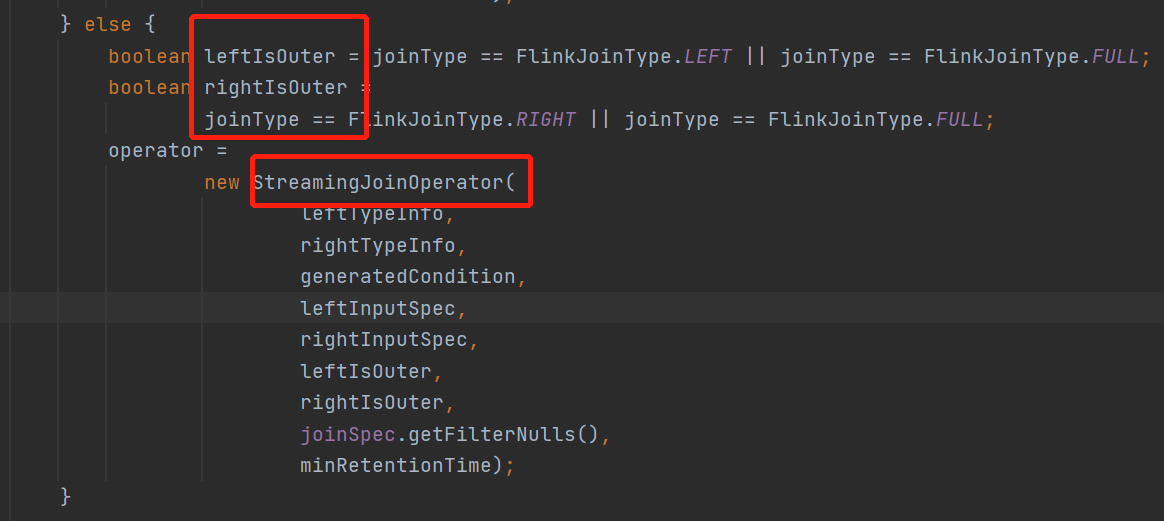
首先会根据会join的类型,确定两个流那个需要输出,如果是fulljoin两个流都会输出,left join就是左流需要outer,right join就是right流需要outer
之后创建了具体的Operator,来看下这个StreamingJoinOperator
先看一下这个类里面两个比较重要的状态

可以看到,左右流都会保存一个状态
看下状态包装类的描述
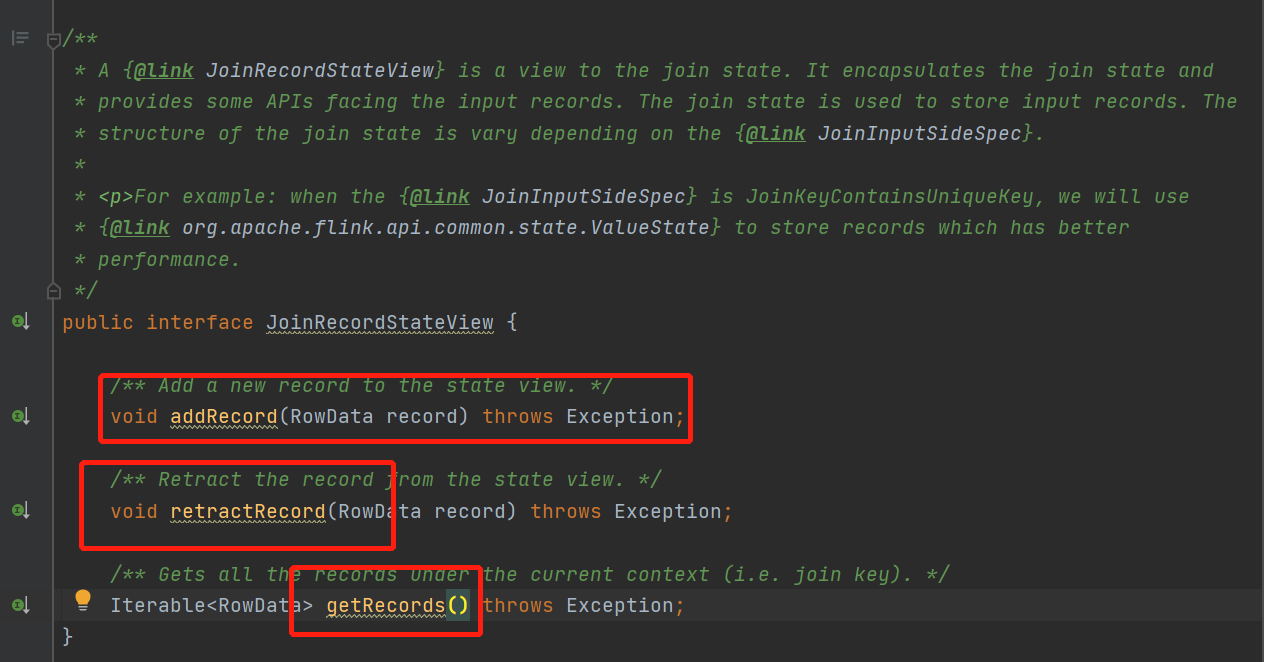
总共就三,方法,分别是加入数据,撤回数据,获取这个数据关联上的所有数据
在open方法里面会根据上面计算的左右流是否需要输出来初始化这个两个状态

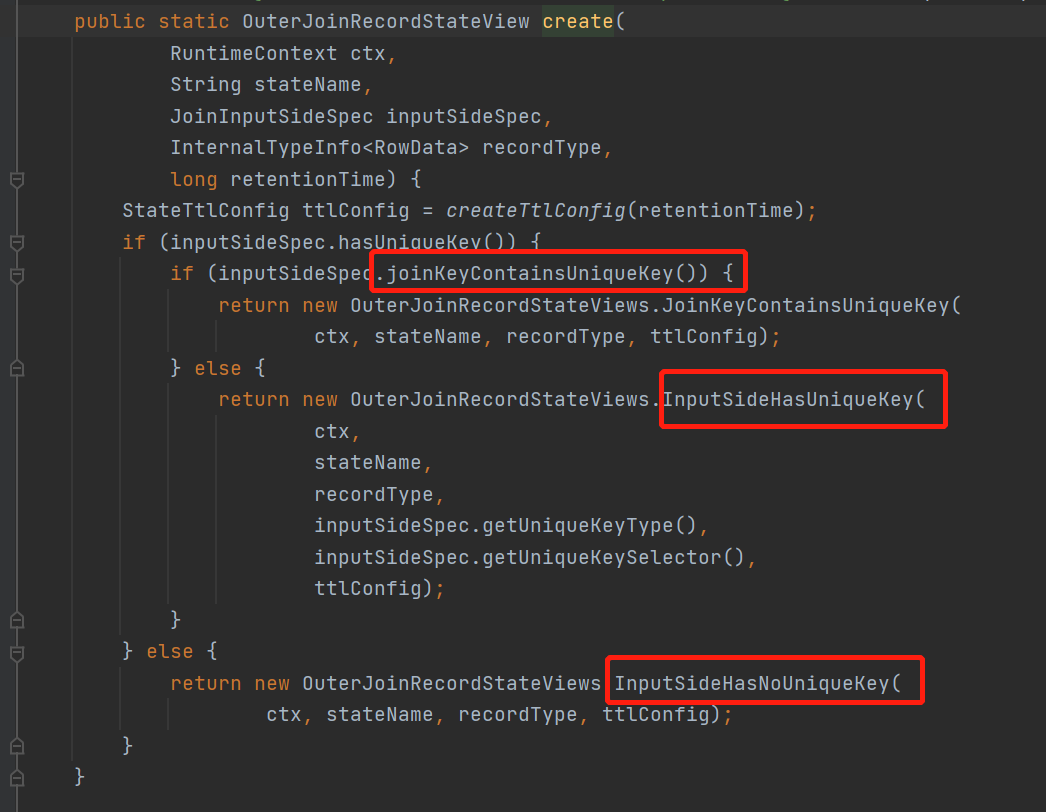
这里状态包装类的创建,将根据数据类型分为三种
1. 流带主键,且join条件包含了主键

这样数据唯一,就只用ValueState来存
2. 流带主键,但join条件没有包含主键

这里就用MapState来存了,每次根据主键更新
3. 流不带主键

就用map,直接把record当key存了
接着看processElement方法
这里详细的代码就不列出来了太复杂了,想看的直接看这个类
org.apache.flink.table.runtime.operators.join.stream.StreamingJoinOperator.processElement()
梳理逻辑我们还是来看下伪代码


主要分为两段
1. 如果是 +Insert / +Update 类型的数据
判断输入数据的流需不需要输出
如果需要输出
看下和另外一个流关联的上不
关联的上输出 +I[record+other]s
关联不上输出 +I[record+null]
将数据加入状态中
如果不需要输出
将数据加入状态中
如果与另外一个流的数据关联上了
如果另外一个流要outer, 输出 +I[record+other]s
如果另外一个流不用输出 ,输出 +I/+U[record+other]s
1. 如果是 -Delete / -Update 类型的数据
状态里面先撤回这条数据
如果与另外流没有匹配上,如果输入数据的流需要输出,则输出 -D[record+null]
如果与另外一条流匹配上了
当前流outer,发送 -D[record+other]s,如果是inner join发送-D/-U[record+other]s
最后的最后
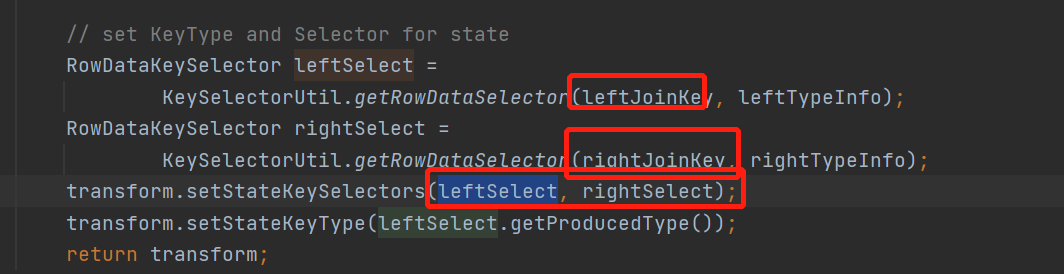
用两个流join的key作为状态的selecter来完成transform的构建就完成了
总结一下:
Flink会根据join的key作为状态分流的selecter,根据表是否有主键,join条件是否包含主键,来创建对应的state数据结构,来优化状态的读写
两条流会根据join类型,来设置此流需不需要输出outer
当数据进入,查询另一侧的流是否有数据可以关联上,以及两条流的outer类型,来确定向下游发送的撤回和新增的数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号