

Flink命令行提交job (源码分析)
这篇文章主要介绍从命令行到任务在Driver端运行的过程
通过flink run 命令提交jar包运行程序
以yarn 模式提交任务命令类似于: flink run -m yarn-cluster XXX.jar
先来看一下脚本中的调用类

在flink.sh脚本中可以看到提交的命令走到了这样一个外观类上,用于提交job解析用户命令行参数
在其main方法中
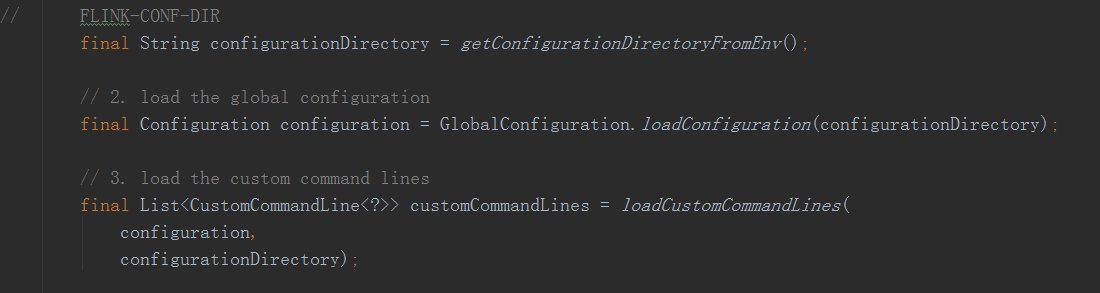
先会解析对应需要的flink参数包括flink-conf-dir等,接着
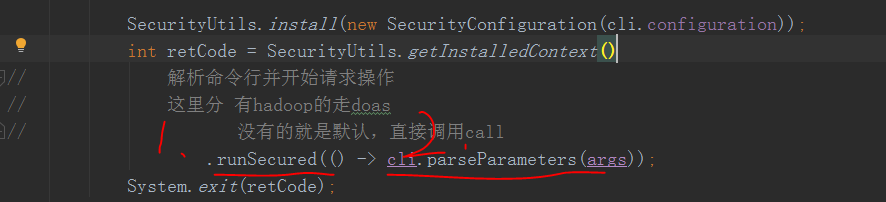
1处会根据是否有hadoop权限安全控制走对应的doas(),具体的执行逻辑为2处解析对应的用户参数
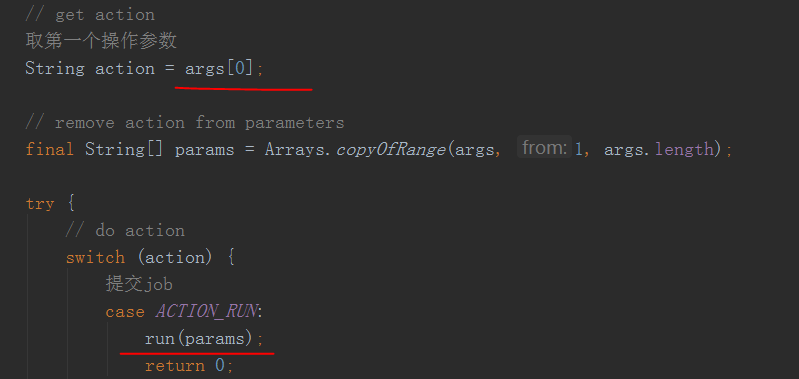
拿到参数后会先将参数中的第一个先取出来作为action
这里我们只看job提交的,解析出来也就是run,然后将剩余的参数用于job运行
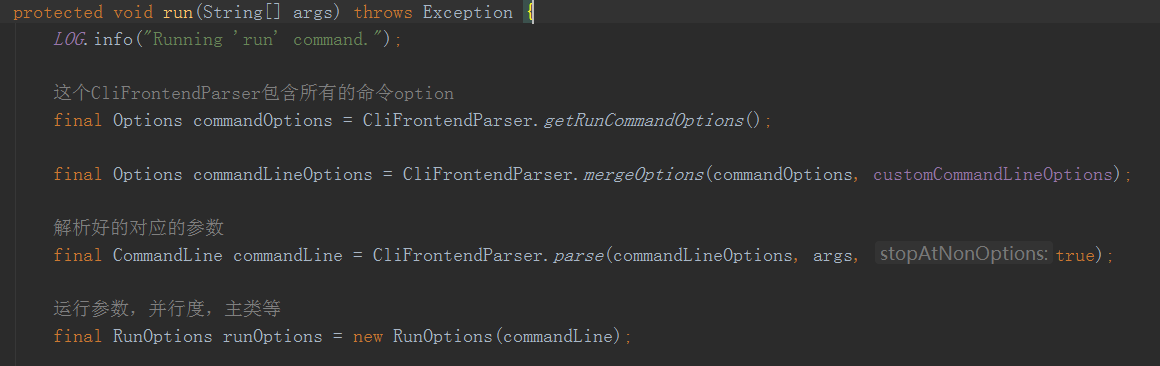
在job运行前会先解析剩余的参数,比如运行的jar文件地址,运行的主类名(没有后面回去Manifest里面找)作为entryPoint入口,并行度等参数
接着

就用得到的这些参数构建program了,这里其实就是拿到了入口运行类的全额限定名,然后通过类加载器加载运行主类

接着,会根据运行时用户的主类是否为Program的实现类(用户可以直接返回plan)来设置对应的packageProgram的属性program是否为空
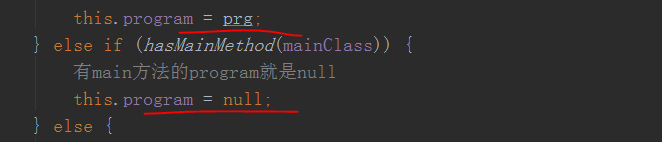
那我们常规的提交main方法主类的这里就是空的,如果是主类实现progarm的就反射实例化了一个以后赋给它
接着,就是运行并且提交任务了


这里比较重要,yarn模式提交的话这里会调度整个集群,提交常见的异常
Couldn't deploy Yarn session cluster
就是从这个方法里面抛出的,与yarn有关
这里只看yarn的调度集群,因为standalone模式的话Jobmanager和TaskManager是已经启动好的了不需要这里
其中走到了这个方法deployInternal()
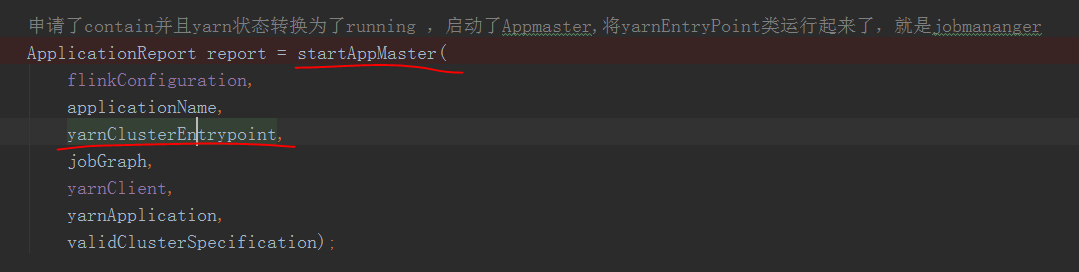
可以看到这里就是申请AppMaster并且传入了yarn模式启动集群的类的全额限定名,其实就是这个类

用于启动jobmanager,和standalone 的入口类
org.apache.flink.runtime.entrypoint.StandaloneSessionClusterEntrypoint
功能差不多,但是还有有区别,当这个yarnsourceManager类申请到contain的时候就会
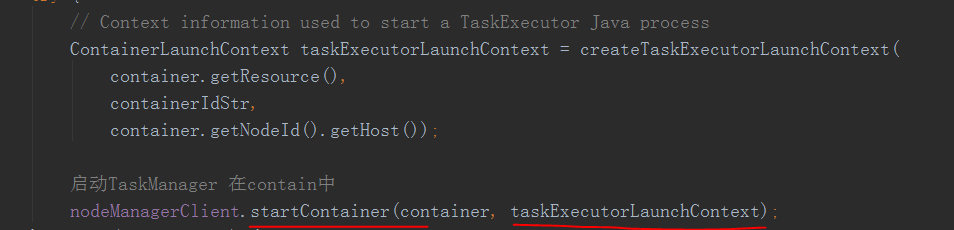
就会去起对应的taskManager了
回到最开始,当集群调度完以后

运行用户程序


其实就是调用了用户的main方法,结束
后面就是job往jobmanager提交了,前面的文章有
总结:
通过一个外观类解析用户参数,拿到类名
调度集群启动申请AppMaster,Contaion起JM,TM
然后类名通过类加载器加载类,然后反射实例调用用户的main方法启动Job

