

Flink的Job启动TaskManager端(源码分析)
前面说到了 Flink的TaskManager启动(源码分析) 启动了TaskManager
然后 Flink的Job启动JobManager端(源码分析) 说到JobManager会将转化得到的TDD发送到TaskManager的RPC
这篇主要就讲一下,Job在TaskManager端是如何启动的
先来看一下,TaskManager端用来接收JobManager发送过来的TDD对象的RPC接口
在TaskExecutor.java中

这个方法用于接收了一个TaskDeploymentDescriptor对象用于启动任务(上一篇知道这里executionGraph的每一个并行度都会调用deploy方法生成一个TDD)
来看一下具体接收到以后做了什么


创建了一个Task并且将其内部的一个线程启动起来了
注意这里从TDD中得到了InputGate,Partition的信息,用于创建InputGate,ResultPartition
InputGate用于对接上游产生的数据(消费)
ResultPartition用于往下游发送自己产生的数据(生产)
来看一下Task创建,在Task的构造方法中
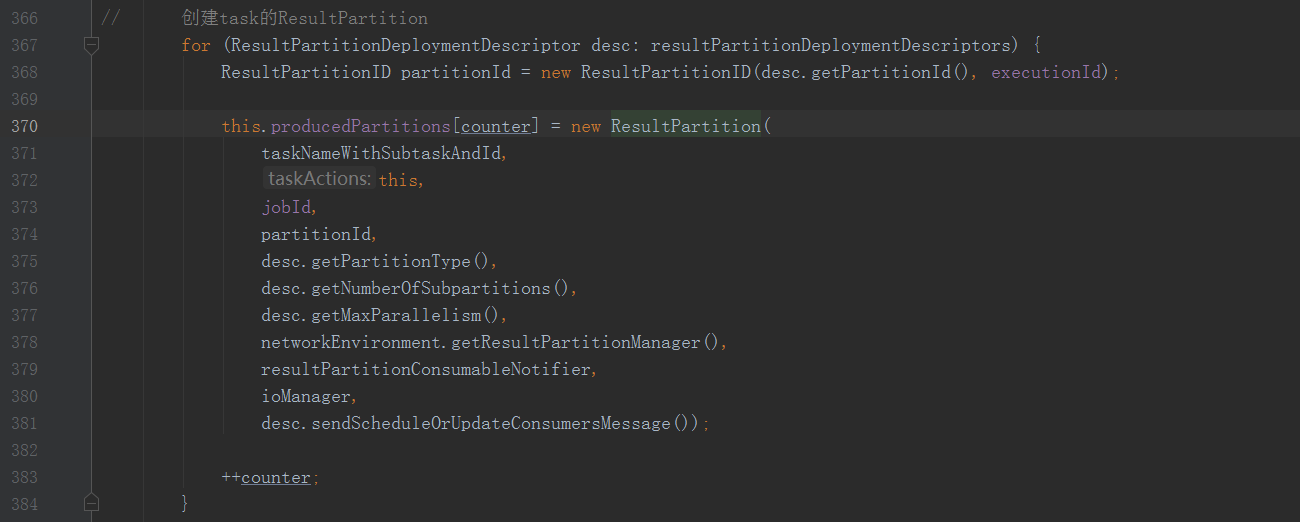
这里看到创建了对应往下游发送数据的ResultPartition
ResultPartition中创建的SubPartition具体分为
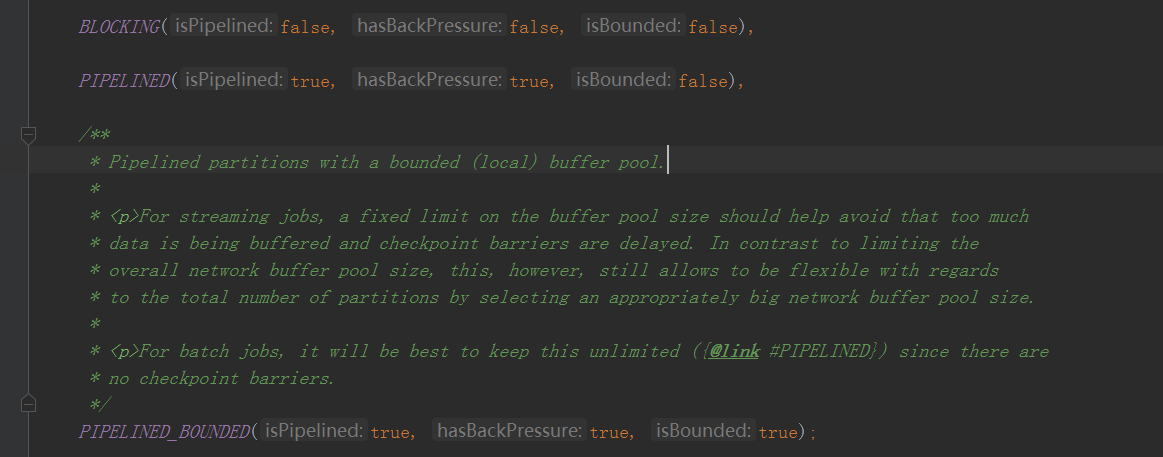
可以看到就是说三个参数分别对应
PIPELINED 可以边消费边生产,是有背压的,这个partition没有buffer数量的限制
(因为背压的控制是通过,接收数据端公用同一个指定大小的bufferPool,以后背压的时候讲)
其他同理
这里看一下不同类型的ResultPartitionType是创建的什么subpartitions

BLOCKING 这种创建了一个SpillableSubpartition并且传进去了一个ioManager(这个ioManager以后io管理细讲)
大致看了一下就是说这种Subpartition是会落盘的
PIPELINED 而这种方式是完全基于内存的
根据上游的信息创建好ResultPartition以后

接着创建了InputGate用于接收上游的数据,并且在create方法中

会根据partition的位置创建对应的channel,这里可以分为
Local 就是说下游和自己是在同一台机器
Remote 下游是需要通过网络发送的

并且在这里将inputGate和它所有的inputChannels关联了起来
创建完inputGate以后Task就初始化完了,然后会被start()起来,来看下Task的run方法
在run方法中

这个地方会为初始化inputGate与ResultPartition的bufferPool(以后讲到反压在讲)
继续

这里通过反射创建了一个StreamTask的实例
并且

调用了他的invoke()方法,这里也是Job开始的逻辑,来看一下invoke方法
在invoke方法中

只要知道这里会初始化OperatorChain这里包含了我们用户算子的逻辑(这里不细讲,随缘讲到Task操作责任链的时候讲)
然后得到了operatorChain的头headoperator其实这里的头就包含了用户的第一个算子逻辑在里面
然后init()方法中用上面的headoperator初始化了一个inputProcess对象并且关联上了上面创建的inputGate(也是留到责任链讲)
接着


这里就是上面在init方法中创建的inputProcess,并且调用了他的processInput方法
重头戏来了,来看一下processInput方法

这里有个while(true)也就是说这里会一直循环下去
来看一下他循环做什么
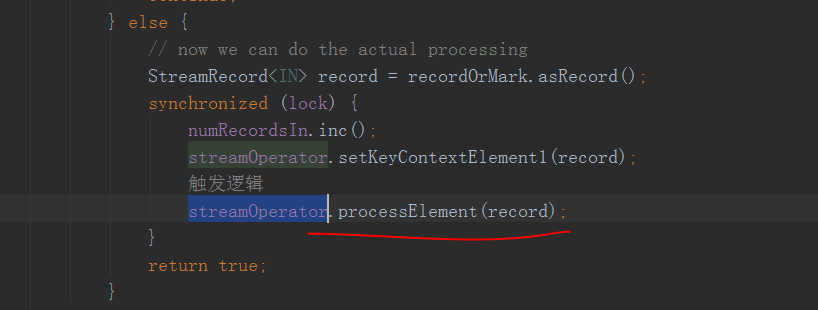
这里!!!!这个streamOperator就是上面构造inputProcess时传入的headOperator
这个processElement方法里面就是调用用户的方法啦
也就是不停的从上游接收到数据以后,调用用户具体的处理逻辑
这里job就启动完成了
注意这个while循环内既然开始走我们用户的逻辑,那肯定会先从inputGate关联到的上游获取数据
这里就非常重要了,因为接收数据就包含了很多的机制的实现
包含了watermark处理的逻辑,水印对齐的逻辑,水印更新的逻辑,如下

以及idle停滞流逻辑,流状态更新逻辑

以及如何接收数据逻辑,接收端反压的逻辑,barriers对齐的逻辑,checkpoint触发的逻辑

所以这个StreamInputProcessor.processInput()方法是一个非常重要的方法,以后随缘更新各种机制的时候也会经常看到

