

Flink中Idle停滞流机制(源码分析)
前几天在社区群上,有人问了一个问题
既然上游最小水印会决定窗口触发,那如果我上游其中一条流突然没有了数据,我的窗口还会继续触发吗?
看到这个问题,我蒙了????
对哈,因为我是选择上游所有流中水印最小的一条作为当前水印时间,那万一最小水印的那条流突然里面没有数据了
那我的最小水印不就一直不往前走了,一直是那个没有数据流的水印了吗,因为它的水印最小,而且一直不会更新了
????然后窗口再也不触发????
思考了一下,发现好像也对,当我有一个上游的水印没来的时候,我就等着呗,谁知道他是不是延迟了
但是!!!
万一他真的就是正常的,出现这种hash极端数据倾斜的情况怎么办呢,MQ的一个partation就是没有数据
那难不成我还真不计算了,一直等着?
怀着这个疑问
首先我想到的是,难道是在生成水印的时候,这条流没有数据了,我为了不让流停下来,就算没数据也周期性的发送水印?
于是有了这篇文章 Flink中Periodic水印和Punctuated水印实现原理(源码分析)
但是,无果!!!
那想要流不停下计算只能在source端实现了,于是看了下源码
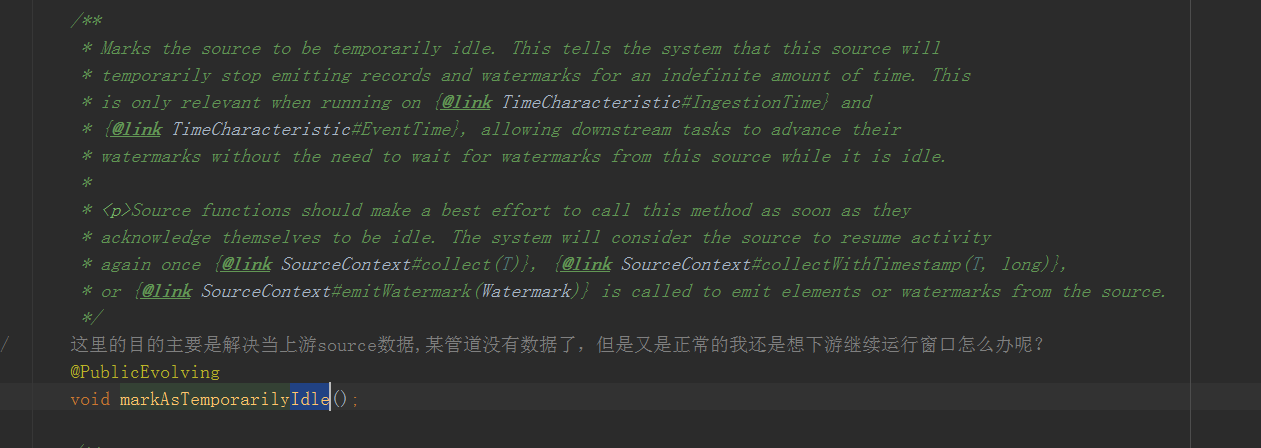
看到sourceFunction.java接口的这个方法时,便解开了我的疑惑
上面就是说事件时间处理时,可以把流标记为 idle停滞的,就是说这个流不会再发送数据和水印了
且允许下游任务推进
ok 找到了那现在来看一下它是如何实现的,看下具体实现类


这里看到这个streamStatus 的停滞idle状态会被emit广播往下游发送
既然往下发了,看下下游接收到这个status是做了什么
打开StreamInputProcessor.java的processInput()方法 (这里是task端运行job的逻辑以后随缘更新到会细讲)

这里接收到了某上游流的状态改变了,这里毫无疑问就是更新stream的状态

修改了stream和channel的状态为idle 停滞 以后呢
来到水印更新的逻辑 (这里不了解的可以看看这里 Flink中watermark为什么选择最小一条(源码分析))

前面就是说如果是来自已经是idle停滞的流的水印,那我就忽略这条水印
然后来看看,来自没有停滞idle的流的水印,是如何更新当前水印的 findAndOutputNewMinWatermarkAcrossAlignedChannels方法
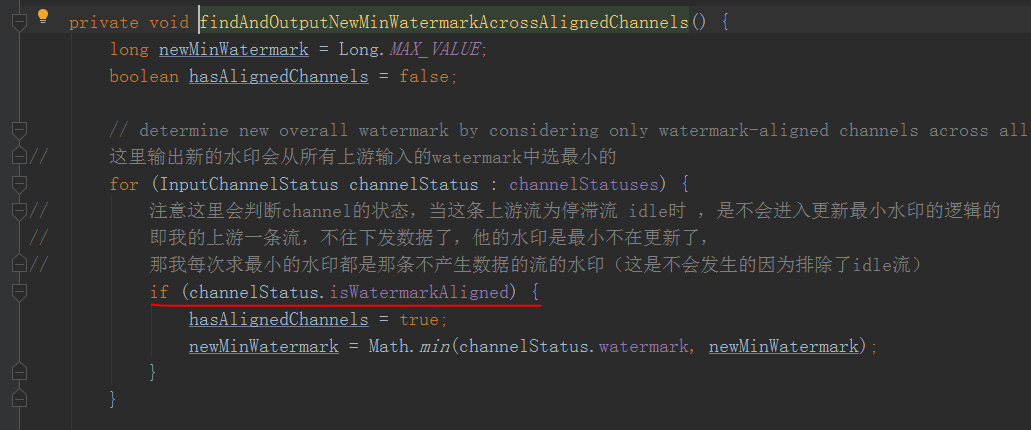
注意到这里
会先判断这个channel是否是idel的!!!!
也就是说当某一个上游的流没有数据停滞了,他是不会参与水印更新逻辑的
真相大白,水印还是会继续往前推进不会停下,计算不会停下
这里就引出了一个思考也是自己在思考的
这里暴露的接口其实是留给我们source源自己实现的,什么时候我们认为流变成了停滞的,我们想他继续强
制推进,继续计算,应该都是要我们自己去决定的,就是说,我是等着数据来才计算呢,还是我继续强制流继续
执行呢,其实是根据自己对source的设计来的,这也是自己的一个思考,自己也没有细研究以后会研究一下主流
source的设计,看能不能解开自己的疑惑
五分钟以后 这!!!FlinkKafkaConsumerBase.java

难道没有offset就停滞了,这么简单吗

