
异常点检测算法
基于统计学的方法
一、基于正态分布的一元离群点检测方法
假设有 n 个点$(x_1, ...,x_n)$, 那么可以计算出这n个点的均值$\mu$和方差$\sigma$.均值和方差分别被定义为:
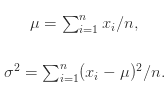
在正态分布的假设下,区域$\mu +- 3 \sigma$包含了99.7% 的数据,如果某个值距离分布的均值$\mu$超过了$3 \sigma$,那么这个值就可以被简单的标记为一个异常点(outlier)。
二、多元离群点的检测方法
涉及两个或者两个以上变量的数据称为多元数据,很多一元离群点的检测方法都可以扩展到高维空间中,从而处理多元数据。
1)基于一元正态分布的离群点检测方法
假设n维的数据集合形如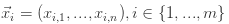 ,那么可以计算每个维度的均值和方差,具体来说,对于
,那么可以计算每个维度的均值和方差,具体来说,对于  ,可以计算
,可以计算

在正态分布的假设下,如果有一个新的数据 ,可以计算概率
,可以计算概率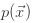 如下:
如下:
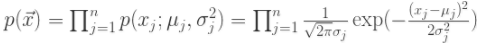
根据概率值的大小就可以判断 x 是否是异常值,显然概率值越小,异常值的可能性越大。
2)多元高斯分布的异常点检测
假设 n 维的数据集合 ,")
,...,E(x_{n}))")
和 
![\Sigma=[Cov(x_{i},x_{j})], i,j \in \{1,...,n\}](https://s0.wp.com/latex.php?latex=%5CSigma%3D%5BCov%28x_%7Bi%7D%2Cx_%7Bj%7D%29%5D%2C+i%2Cj+%5Cin+%5C%7B1%2C...%2Cn%5C%7D&bg=ffffff&fg=2b2b2b&s=0 "\Sigma=[Cov(x_{i},x_{j})], i,j \in \{1,...,n\}")
如果有一个新的数据 
=\frac{1}{(2\pi)^{\frac{n}{2}}|\Sigma|^{\frac{1}{2}}} \exp(-\frac{1}{2}(\vec{x}-\vec{\mu})^{T}\Sigma^{-1}(\vec{x}-\vec{\mu}))")
根据概率值的大小就可以判断
3)使用Mahalanobis距离(马氏距离)检测多元离群点
对于一个多维的数据集合 D,假设 

=\sqrt{(a-\overline{a})^{T}S^{-1}(a-\overline{a})},")
其中 
在这里,")
|a\in D\}")
4)使用 统计量检测多元离群点
统计量检测多元离群点
在正态分布的假设下,

^{2}/E_{i}.")
其中,

基于矩阵分解的异常点检测方法
基于主成分分析(PCA)的算法会把原始数据从原始的空间投影到主成分空间,然后再把投影拉回到原始的空间。如果只使用第一主成分来进行投影和重构,对于大多数的数据而言,重构之后的误差是小的;但是对于异常点而言,重构之后的误差依然相对大。这是因为第一主成分反映了正常值的方差,最后一个主成分反映了异常点的方差。
https://zr9558.com/2016/06/23/outlierdetectiontwo/
https://zr9558.com/2016/06/13/outlierdetectionone/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号