
DeepFM
DeepFM integrates the architectures of FM and deep neural networks (DNN). It models low-order feature interactions like FM(二阶组合特征) and models high-order feature interactions like DNN(高阶组合特征).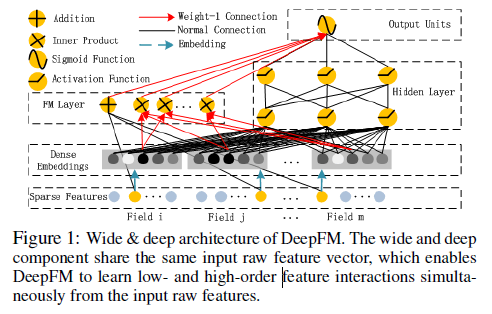 FM部分和Deep部分输入的特征一样,都是one-hot后的特征,共享同一个embedding层,cvr类型的特征需要离散化处理(每个field对应一个embedding层,如何定义layer,使得连接权重全部为常数1,输入节点两两组合进行Inner Product?)
FM部分和Deep部分输入的特征一样,都是one-hot后的特征,共享同一个embedding层,cvr类型的特征需要离散化处理(每个field对应一个embedding层,如何定义layer,使得连接权重全部为常数1,输入节点两两组合进行Inner Product?)
FM部分:
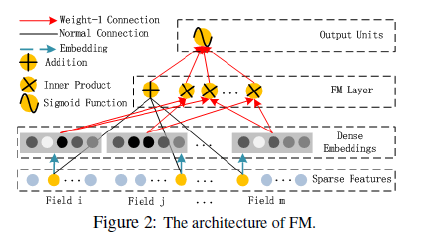
The FM component is a factorization machine,which is proposed to learn feature interactions for recommendation. Besides a linear (order-1) interactions among features, FM models pairwise (order-2) feature interactions as inner product of respective feature latent vectors(FM通过矩阵分解,每个特征对应一个隐向量,任意两个特征组合对应两个隐向量的点积). It can capture order-2 feature interactions much more effectively than previous approaches especially when the dataset is sparse. In previous approaches, the parameter of an interaction of features i and j can be trained only when feature i and feature j both appear in the same data record(两两特征进行组合,训练需要大量的两特征都存在的样本). While in FM, it is measured via the inner product of their latent vectors Vi and Vj . Thanks to this flexible design, FM can train latent vector Vi (Vj ) whenever i (or j) appears in a data record. Therefore, feature interactions, which are never or rarely appeared in the training data, are better learnt by FM.(FM中学习组合特征参数,就是学习特征对应的隐向量,由下面的式子可知,隐向量的训练不需要样本中两个特征同时都出现,这需要隐向量对应的特征存在即可。)
参考: http://www.cnblogs.com/ljygoodgoodstudydaydayup/p/6340129.html
FM训练的时候,要求解的梯度为:
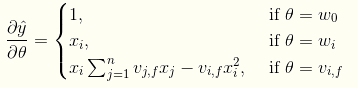
 对应的公式:
对应的公式: 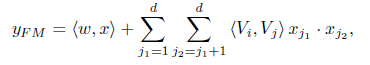
A Normal Connection in black refers to a connection with weight to be learned; a Weight-1 Connection, red arrow, is a connection with weight 1 by default(隐向量在Inner Product神经元中计算点积 ); Embedding,blue dashed arrow, means a latent vector to be learned(每个特征对应一个隐向量,embedding层其实就是一个全连接层,该全连接层有k个神经元,k是隐向量的维度,每个神经元的维度等于输入特征向量的维度。每个field生成一个词向量); Addition means adding all input together; Product, including Innerand Outer-Product, means the output of this unit is the product of two input vector; Sigmoid Function is used as the output function in CTR prediction; Activation Functions, such as relu and tanh, are used for non-linearly transforming the signal.
Deep 部分:
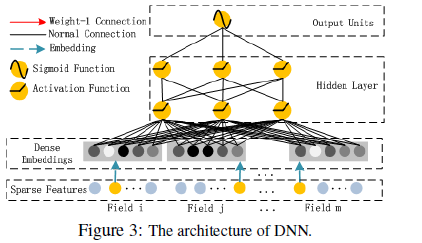
The raw feature input vector for CTR prediction is usually highly sparse, super high-dimensional, categorical-continuous-mixed, and grouped in fields。 This suggests an embedding layer to compress the input vector to a low dimensional, dense real-value vector before further feeding into the first hidden layer, otherwise the network can be overwhelming to train.

每个Field对应一个特征one-hot后的稀疏向量(维度:1 * n),embedding层有k个神经元,神经元的维度为n * 1,Field对应的稀疏向量与这k个神经元都连接,每个神经元上输出一个实数,则embedding层输出的结果为1*k的向量。
1) while the lengths of different input field vectors can be different(不同特征的特征值数目不同,所以one-hot向量的维度也不同),their embeddings are of the same size (k);
2) the latent feature vectors (V ) in FM now server as network weights which are learned and used to compress the input field vectors to the embedding vectors.
It is worth pointing out that FM component and deep component share the same feature embedding, which brings two important benefits: 1) it learns both low- and high-order feature interactions from raw features; 2) there is no need for expertise feature engineering of the input, as required in Wide & Deep 。
每个field对应一个词向量: http://book.paddlepaddle.org/index.cn.html
usr_age_id = paddle.layer.data( name='age_id', type=paddle.data_type.integer_value( len(paddle.dataset.movielens.age_table))) usr_age_emb = paddle.layer.embedding(input=usr_age_id, size=16) usr_age_fc = paddle.layer.fc(input=usr_age_emb, size=16) usr_job_id = paddle.layer.data( name='job_id', type=paddle.data_type.integer_value( paddle.dataset.movielens.max_job_id() + 1)) usr_job_emb = paddle.layer.embedding(input=usr_job_id, size=16) usr_job_fc = paddle.layer.fc(input=usr_job_emb, size=16)

Relationship with the other Neural Networks:
FNN
PNN
Wide & Deep
Parameter Settings:
1) dropout : 0.5
Dropout refers to the probability that a neuron is kept in the network.Dropout is a regularization technique to compromise the precision and the complexity of the neural network.We set the dropout to be 1.0, 0.9, 0.8, 0.7, 0.6,0.5. The result shows that adding reasonable randomness to model can strengthen model's robustness.
2) network structure: 400-400-400
3) optimizer: Adam
4) activation function: relu https://arxiv.org/pdf/1611.00144.pdf
5) the latent dimension: 10
6) number of hidden layers
As presented in Figure 10, increasing number of hidden layers improves the performance of the models at the beginning, however, their performance is degraded if the number of hidden layers keeps increasing. This phenomenon is also because of overfitting.

注意激活层使用的激活函数以及BN层、 dropout层(隐层中设置dropout值就行了吧?)的位置
https://github.com/Leavingseason/OpenLearning4DeepRecsys
dnn ctr预估模型:
http://www.52cs.org/?p=1046
http://www.52cs.org/?p=1851

 浙公网安备 33010602011771号
浙公网安备 33010602011771号