

2017找工作_机器学习相关面经
1、什么是boosting tree
2、GBDT
3、L1和L2正则为何可以减弱over-fitting,L1和L2正则有什么区别?
从贝叶斯的角度来看, 正则化等价于对模型参数引入先验分布 http://www.cnblogs.com/ljygoodgoodstudydaydayup/p/6483560.html
L2正则化等价于 对参数引入高斯先验 , L1正则化等价于对参数引入 拉普拉斯先验
正则化参数等价于对参数引入先验分布,使得 模型复杂度 变小(缩小解空间),对于噪声以及 outliers 的鲁棒性增强(泛化能力)。整个最优化问题从贝叶斯观点来看是一种贝叶斯最大后验估计,其中 正则化项 对应后验估计中的 先验信息,损失函数对应后验估计中的似然函数,两者的乘积即对应贝叶斯最大后验估计的形式。
4、KNN和LR有什么本质区别
5、怎么理解Dropout
6、为什么random forest具有特征选择的功能?
7、random forest有哪些重要的参数?
8、DNN为什么功能强大,说说你的理解
9、SVM的损失函数是什么?怎么理解。svm如何用于多分类?
目前,svm用于多分类的方法主要有:
1. “1-V-R方式”,就是每次解一个两类分类的问题。比如我们有5个类别,首先把类别1的样本定为正样本,其余的样本合起来定为负样本,得到一个两类分类器,它能够指出新的样本是不是第1类的;然后我们把类别2的样本定为正样本,把1、3、4、5的样本合起来定为负样本,得到一个分类器,如此下去,最终可以得到5个这样的两类分类器。这种方法的好处是每个优化问题的规模比较小,而且分类的时候速度很快(对于k类问题,把其中某一类的n个训练样本视为一类,所有其他类别归为另一类,需要训练k个分类器)。
但有时可能会出现两种特殊情况,某样本属于多个类别(分类重叠现象)或者是某样本没有判别为任何类别(不可分类现象)。而且,如果各个类别的样本数目是差不多的,“其余”那一类样本数总是要数倍于正类,这就人为的造成了“数据集偏斜”问题。
2. “1-V-1方式”,也就是我们所说的one-against-one方式。这种方法把其中的任意两类构造一个分类器,共有(k-1)×k/2个分类器。虽然分类器的数目多了,但是在训练阶段所用的总时间却比“一类对其余”方法少很多。
最后预测中如果出现分类重叠现象,可以采用voting方式(各个分类器向k个类别投票,取得票最高类)。但是如果类别数非常大时,要调用的分类器数目会达到类别数的平方量级,预测的运算量不可小觑。
3. “有向无环图(DAG-SVM)”,该方法在训练阶段采用1-V-1方式,而判别阶段采用一种二向无环图的方式。
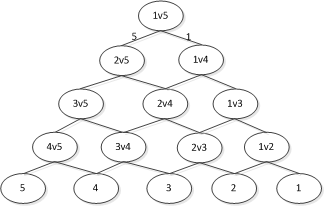
如果类别数是k,则只调用k-1个分类器即可。但是如果开始的分类器回答错误,那么后面的分类器是无论如何也无法纠正它的错误的,其实对下面每一层的分类器都存在这种错误向下累积的现象。也有一些方法可以改善整体效果,我们总希望根节点少犯错误为好,因此参与第一次分类的两个类别,最好是差别特别大,或者取在两类分类中正确率最高的那个分类器作根节点,或者我们让两类分类器在分类的时候,不光输出类别的标签,还输出一个类似“置信度”,当它对自己的结果不太自信的时候,我们就不光按照它的输出走,它可会按照一定的概率走向另一分支。
LibSVM采用的是1-V-1方式,因为这种方式思路简单,并且许多实践证实效果比1-V-R方式要好。
10、介绍下Maxout
11、项目中over-fitting了,你怎么办
12、详细说一个你知道的优化算法(Adam等)
13、项目(比赛)怎么做的模型的ensemble
14、stacking是什么?需要注意哪些问题
15、了解哪些online learning的算法
16、如何解决样本不均衡的问题
17、fasterRCNN中的ROIPooling是如何实现的
18、如何进行特征的选择
19、如何进行模型的选择
20、什么是梯度消失?怎么解决
21、常用的有哪些损失函数
22、假设一个5*5的filter与图像卷积,如何降低计算量?
23、做过模型压缩吗?介绍下
24、什么是residual learning?说说你的理解
25、residual learning所说的residual和GBDT中的residual有什么区别?
26、FFM和FTRL有过了解吗?
27、用Map Reduce implement矩阵乘法
28、不同的activation function的pros/cons
29、如何处理diminishing gradient的问题
30、svm优缺点
31、Dropout为什么可以解决过拟合
32、如何用hadoop实现k-means
33、naive bayes和logistic regression的区别
朴素贝叶斯的参数估计: https://www.zhihu.com/question/33959624
贝叶斯与朴素贝叶斯的区别:朴素贝叶斯是在贝叶斯的基础上多了特征条件独立假设。
http://blog.csdn.net/chlele0105/article/details/38922551
区别:
(1) Naive Bayes是一个生成模型,在计算P(y|x)之前,先要从训练数据中计算P(x|y)和P(y)的概率,从而利用贝叶斯公式计算P(y|x)。
Logistic Regression是一个判别模型,它通过在训练数据集上最大化判别函数P(y|x)学习得到,不需要知道P(x|y)和P(y)。
(2) Naive Bayes是建立在特征条件独立假设基础之上的,设特征X含有n个特征属性(X1,X2,...Xn),那么在给定Y的情况下,X1,X2,...Xn是条件独立的。Logistic Regression的限制则要宽松很多,如果数据满足条件独立假设,Logistic Regression能够取得非常好的效果;当数据不满度条件独立假设时,Logistic Regression仍然能够通过调整参数让模型最大化的符合数据的分布,从而训练得到在现有数据集下的一个最优模型。
相同点:
Logistic regression和Naive bayes建模的都是条件概率 ,对所最终求得的不同类的结果有很好的解释性
34、用户流失率预测怎么做
http://www.jianshu.com/p/d3a72c0e05a0
1、数据采集
数据采集周期上我们以两个月的数据作为分析基础。利用第一个月用户的数据表现作为因变量,然后根据同一批用户第二个月的用户留存/流失情况,建立预测模型得到流失规则。如果是手游,以周甚至日为跨度可能更适合?
特征:
1)反映用户活跃:登录天数、在线时长、登录频次等等;
2)反映用户游戏表现:等级、竞技场段位、VIP等级、战斗力等等;
3)反映用户游戏行为:某些关键功能的使用情况、关卡通关情况、BOSS挑战情况、重要活动参与率等等;
4)反映用户资源拥有情况:服装/装备/宠物拥有数量、强力服装/装备/宠物拥有情况、游戏货币拥有情况等等;
5)反映用户社交情况:家族参与情况、活跃好友数量、发言情况等等。
6)反映用户消费情况:历史游戏货币兑换量、当月游戏货币兑换量、VIP开通月数、当月VIP续费情况等等;
35、采用 EM 算法求解的模型有哪些,为什么不用牛顿法或梯度下降法?· 用 EM 算法推导解释 Kmeans
36、聚类算法中的距离度量有哪些?
37、卷积层为什么能抽取特征
卷积层的输出(feature map)可以看做是图像的每部分对于模版(kernel)的匹配程度,“模版”就是卷积核,”匹配程度”则是输入信号对于该卷积核的响应程度,卷积网络的输入图像或特征图的局部区域越符合卷积核结构,响应越高,即对于模版的匹配程度越高。
深度学习相关的一些面试题: https://zhuanlan.zhihu.com/p/25005808

