



sklearn 特征选择
1、移除低方差的特征(Removing features with low variance)
VarianceThreshold 是特征选择中的一项基本方法。它会移除所有方差不满足阈值的特征。默认设置下,它将移除所有方差为0的特征,即那些在所有样本中数值完全相同的特征。
这里的方差是特征值的方差,当特征值都是离散型变量的时候这种方法才能用,如果是连续型变量,就需要将连续变量离散化之后才能用,而且实际当中,一般不太会有95%以上都取某个值的特征存在,所以这种方法虽然简单但是不太好用。
如果先对某特征groupby,然后计算对应的label的均值,再计算均值的方差,这样可能比较有用(方差反映同一特征的不同特征值对标签的区分能力)
2、单变量特征选择(Univariate feature selection) (filter方法)
单变量特征选择能够对每一个特征进行测试,衡量该特征和响应变量之间的关系,根据得分扔掉不好的特征。对于回归和分类问题可以采用卡方检验等方式对特征进行测试。
这种方法比较简单,易于运行,易于理解,通常对于理解数据有较好的效果(但对特征优化、提高泛化能力来说不一定有效);这种方法有许多改进的版本、变种。
2.1 皮尔森相关系数
2.2 互信息和最大信息系数
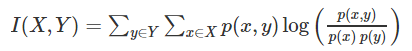
以上就是经典的互信息公式了。想把互信息直接用于特征选择其实不是太方便:1、它不属于度量方式,也没有办法归一化,在不同数据集上的结果无法做比较;2、对于连续变量的计算不是很方便(X和Y都是集合,x,y都是离散的取值,如果是连续变量需要积分),通常变量需要先离散化,而互信息的结果对离散化的方式很敏感。
互信息度量 X 和 Y 共享的信息:它度量知道这两个变量其中一个,对另一个不确定度减少的程度。例如,如果 X 和 Y 相互独立,则知道 X 不对 Y 提供任何信息,反之亦然,所以它们的互信息为零。在另一个极端,如果 X 是 Y 的一个确定性函数,且 Y 也是 X 的一个确定性函数,那么传递的所有信息被 X 和 Y 共享:知道 X决定 Y 的值,反之亦然。因此,在此情形互信息与 Y(或 X)单独包含的不确定度相同,称作 Y(或 X)的熵。而且,这个互信息与 X 的熵和 Y 的熵相同。互信息是非负的.
最大信息系数克服了这两个问题。它首先寻找一种最优的离散化方式,然后把互信息取值转换成一种度量方式,取值区间在[0,1]。http://blog.csdn.net/qtlyx/article/details/50780400 http://www.datamic.com/articles/sf20151126002.html
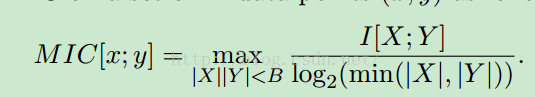
$|X|, |Y|$表示x和y的离散值的数目,B是经验数据,取数据总量的0.6或者0.55次方
3、 使用SelectFromModel选择特征
3.1 基于L1的特征选择(L1-based feature selection)
使用L1范数作为惩罚项的模型会得到稀疏解:大部分特征对应的系数为0。当你希望减少特征的维度以用于其它分类器时,可以通过 feature_selection.SelectFromModel 来选择不为0的系数。特别指出,常用于此目的的稀疏预测模型有 linear_model.Lasso (回归), linear_model.LogisticRegression 和 svm.LinearSVC (分类)
对于SVM和逻辑回归,参数C控制稀疏性:C越小,被选中的特征越少。对于Lasso,参数alpha越大,被选中的特征越少 。
基于L1的稀疏模型的局限在于,当面对一组互相关的特征时,它们只会选择其中一项特征。为了减轻该问题的影响可以使用随机化技术,通过多次重新估计稀疏模型来扰乱设计矩阵,或通过多次下采样数据来统计一个给定的回归量被选中的次数。
RandomizedLasso 实现了使用这项策略的Lasso, RandomizedLogisticRegression 使用逻辑回归,适用于分类任务。要得到整个迭代过程的稳定分数,你可以使用 lasso_stability_path。
3.3 基于树的特征选择(Tree-based feature selection)
基于树的预测模型(见 sklearn.tree 模块,森林见 sklearn.ensemble 模块)能够用来计算特征的重要程度,因此能用来去除不相关的特征(结合 sklearn.feature_selection.SelectFromModel )
随机森林提供了两种特征选择的方法:mean decrease impurity和mean decrease accuracy。
平均不纯度减少 mean decrease impurity
随机森林由多个决策树构成。决策树中的每一个节点都是关于某个特征的条件,为的是将数据集按照不同的响应变量一分为二。利用不纯度可以定义节点,对于分类问题,通常采用基尼指数或者信息增益,对于回归问题,通常采用的是方差或者最小二乘拟合。当训练决策树的时候,可以计算出每个特征减少了多少树的不纯度。对于一个决策树森林来说,可以算出每个特征平均减少了多少不纯度,并把它平均减少的不纯度作为特征选择的值。
使用基于不纯度的方法的时候,要记住:1、这种方法存在偏向,对具有更多类别的变量会更有利(信息增益的缺点);2、对于存在关联的多个特征,其中任意一个都可以作为指示器(优秀的特征),并且一旦某个特征被选择之后,其他特征的重要度就会急剧下降,因为不纯度已经被选中的那个特征降下来了,其他的特征就很难再降低那么多不纯度了,这样一来,只有先被选中的那个特征重要度很高,其他的关联特征重要度往往较低。在理解数据时,这就会造成误解,导致错误的认为先被选中的特征是很重要的,而其余的特征是不重要的,但实际上这些特征对响应变量的作用确实非常接近的(这跟Lasso是很像的)。
平均精确率减少 Mean decrease accuracy
另一种常用的特征选择方法就是直接度量每个特征对模型精确率的影响。主要思路是打乱每个特征的特征值顺序,并且度量顺序变动对模型的精确率的影响。很明显,对于不重要的变量来说,打乱顺序对模型的精确率影响不会太大,但是对于重要的变量来说,打乱顺序就会降低模型的精确率。
http://sklearn.lzjqsdd.com/modules/feature_selection.html
http://blog.csdn.net/bryan__/article/details/51607215
http://www.cnblogs.com/hhh5460/p/5186226.html

