



逻辑回归以及广义线性模型总结
常见的广义线性模型有:probit模型、poisson模型、对数线性模型等等。对数线性模型里有:logistic regression、Maxinum entropy。
在二分类问题中,为什么弃用传统的线性回归模型,改用逻辑斯蒂回归?
线性回归用于二分类时,首先想到下面这种形式,p是属于类别的概率:
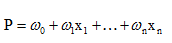
但是这时存在的问题是:
1、等式两边的取值范围不同,右边是负无穷到正无穷,左边是[0,1]
2、实际中的很多问题,都是当x很小或很大时,对于因变量P的影响很小,当x达到中间某个阈值时,影响很大。即实际中很多问题,概率P与自变量并不是直线关系。
逻辑回归模型的求解过程? ==> 目标函数(损失函数)的推导过程
逻辑回归中,Y服从二项分布,误差服从二项分布,而非高斯分布,所以不能用最小二乘进行模型参数估计,可以用极大似然估计来进行参数估计。
预测函数:
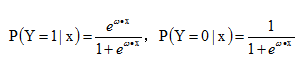
似然函数:这里负类的label为0,如果负类的label为-1的话,将$y_i$ 变为$(1+y_i) / 2$,将$1 - y_i$变为$(1-y_i) / 2$,带入下列似然函数即可
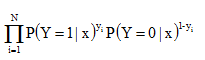
对数似然函数,优化目标函数如下:
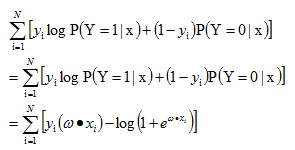
逻辑回归有两种形式:http://www.cnblogs.com/ljygoodgoodstudydaydayup/p/6340129.html 整理在一起
为什么我们在实际中,经典线性模型的优化目标函数是最小二乘,而逻辑回归则是似然函数?
1) 经典线性模型的满足下面等式:
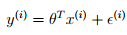
这里有个假设,即最后这个误差扰动项独立同分布于均值为0的正态分布,即:
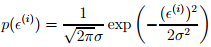
从而:
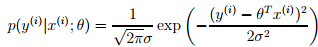
由于有上面的假设,从而就有下面的似然函数:
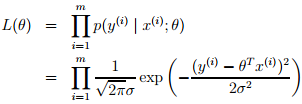
从而这线性回归的问题就可转化为最大化下面的对数似然估计,由于下面公式前面的项是常数,所以这个问题等价于最小化下面等式中的最后一项,即least mean squares。
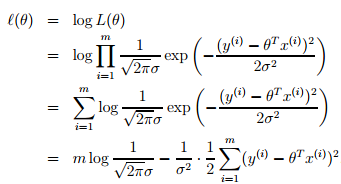
2)逻辑斯蒂回归中,因变量y不再是连续的变量,而是二值的{0,1},中间用到logit变换,将连续性的y值通过此变换映射到比较合理的0~1区间。在广义线性回归用于分类问题中,也有一个假设(对应于上面回归问题中误差项独立同分布于正态分布),其中h(x)是logistic function
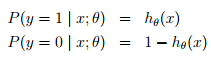
即,给定x和参数,y服从二项分布,上面回归问题中,给定x和参数,y服从正态分布。从而
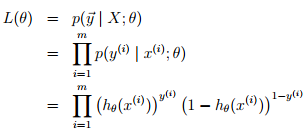
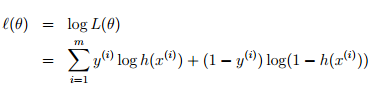
问题不同(一个是分类、一个是回归)对应假设也就不同,决定了logistic regression问题最优化目标函数是上面这项,而非回归问题中的均方误差LMS。
参考:
http://blog.csdn.net/lilyth_lilyth/article/details/10032993?utm_source=tuicool&utm_medium=referral

