
how to avoid over-fitting?(机器学习中防止过拟合的方法,重要)
methods to avoid overfitting:
- Cross-Validation : Cross Validation in its simplest form is a one round validation, where we leave one sample as in-time validation and rest for training the model. But for keeping lower variance a higher fold cross validation is preferred.
- Early Stopping : Early stopping rules provide guidance as to how many iterations can be run before the learner begins to over-fit.
- Pruning : Pruning is used extensively while building CART models. It simply removes the nodes which add little predictive power for the problem in hand.
- Regularization : This is the technique we are going to discuss in more details. Simply put, it introduces a cost term for bringing in more features with the objective function. Hence, it tries to push the coefficients for many variables to zero and hence reduce cost term.
参考:
https://www.analyticsvidhya.com/blog/2015/02/avoid-over-fitting-regularization/
1、获取更多数据:解决过拟合最有效的方法
从数据源头获取更多数据
根据当前数据集估计数据分布参数,使用该分布产生更多数据
数据增强(Data Augmentation):通过一定规则扩充数据,比如图像平移、翻转、缩放、切割等
2、改变模型网络结构Architecture
减少网络的层数、神经元个数等均可以限制网络的拟合能力
3、Early stopping
对于每个神经元而言,其激活函数在不同区间的性能是不同的:
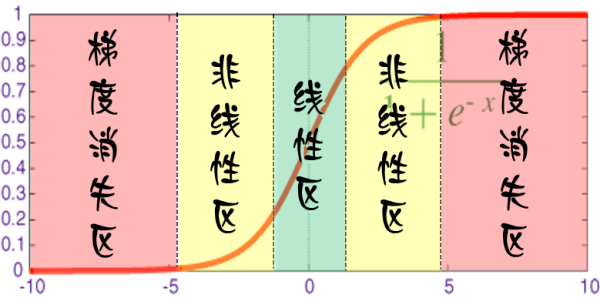
当网络权值较小时,神经元的激活函数工作在线性区,此时神经元的拟合能力较弱(类似线性神经元)。因为我们在初始化网络的时候一般都是初始为较小的权值。训练时间越长,部分网络权值可能越大。如果我们在合适时间停止训练,就可以将网络的能力限制在一定范围内。
3、正则化
4、增加噪声
1)在输入中增加噪声
2)在权值上增加噪声:在初始化网络的时候,用0均值的高斯分布作为初始化。
5、bagging:以随机森林(Rand Forests)为例,就是训练了一堆互不关联的决策树。但由于训练神经网络本身就需要耗费较多自由,所以一般不单独使用神经网络做Bagging。
6、boosting:既然训练复杂神经网络比较慢,那我们就可以只使用简单的神经网络(层数、神经元数限制等)。通过训练一系列简单的神经网络,加权平均其输出。
7、dropout
https://www.zhihu.com/question/59201590

 浙公网安备 33010602011771号
浙公网安备 33010602011771号