1、样本不均衡可能带来的问题
模型训练的本质是最小化损失函数,当某个类别的样本数量非常庞大,损失函数的值大部分被样本数量较大的类别所影响,导致的结果就是模型分类会倾向于样本量较大的类别。咱们拿上面文本分类的例子来说明,现在有1W条用户搜索的样本,其中50条和传奇游戏标签有关,9950条和传奇游戏标签无关,那么模型全部将样本预测为负例,也能得到99.5%的准确率,会让人有一种模型效果还不错的假象,但是实际的情况是这个模型根本没什么卵用,因为我们的目标是识别出这些数量较少的类别。这也是我们在实际业务场景中遇到的问题。(一般使用auc作为评估指标,这种情况下样本不均衡影响貌似不大? 需要补充下)
总体来看,解决样本不均衡的问题主要从数据层面和模型层面来解决,下面会分别从理论到实践的角度分享样本不均衡问题的解决策略。
2、从模型层面解决样本不均衡问题
本节主要从模型层面解决样本不均衡的问题。相比于控制正负样本的比例,我们还可以通过控制Loss损失函数来解决样本不均衡的问题。拿二分类任务来举例,通常使用交叉熵来计算损失,下面是交叉熵的公式:
<img src="https://picx.zhimg.com/50/v2-a9d0b4255ae68856da4cf7df2df31aeb_720w.jpg?source=1940ef5c" data-caption="" data-size="normal" data-rawwidth="507" data-rawheight="120" class="origin_image zh-lightbox-thumb" width="507" data-original="https://pic2.zhimg.com/v2-a9d0b4255ae68856da4cf7df2df31aeb_r.jpg?source=1940ef5c"/> 上面的公式中y是样本的标签,p是样本预测为正例的概率。
2.1 类别加权Loss
为了解决样本不均衡的问题,最简单的是基于类别的加权Loss,具体公式如下:
<img src="https://pica.zhimg.com/50/v2-2b82f33208d342bf8de01aca774f8dbe_720w.jpg?source=1940ef5c" data-caption="" data-size="normal" data-rawwidth="532" data-rawheight="114" class="origin_image zh-lightbox-thumb" width="532" data-original="https://pic3.zhimg.com/v2-2b82f33208d342bf8de01aca774f8dbe_r.jpg?source=1940ef5c"/> 基于类别加权的Loss其实就是添加了一个参数a,这个a主要用来控制正负样本对Loss带来不同的缩放效果,一般和样本数量成反比。还拿上面的例子举例,有100条正样本和1W条负样本,那么我们设置a的值为10000/10100,那么正样本对Loss的贡献值会乘以一个系数10000/10100,而负样本对Loss的贡献值则会乘以一个比较小的系数100/10100,这样相当于控制模型更加关注正样本对损失函数的影响。通过这种基于类别的加权的方式可以从不同类别的样本数量角度来控制Loss值,从而一定程度上解决了样本不均衡的问题。
2.2 Focal Loss
上面基于类别加权Loss虽然在一定程度上解决了样本不均衡的问题,但是实际的情况是不仅样本不均衡会影响Loss,而且样本的难易区分程度也会影响Loss。在样本不均衡的场景中,有非常多的负样本是易区分样本。虽然这些样本的Loss很低,但是数量确很多,所以对于最终的Loss有很大的贡献,导致模型最终的效果不够好。基于这个问题2017年何恺明在论文《Focal Loss for Dense Object Detection》中提出了非常火的Focal Loss,下面是Focal Loss的计算公式:
<img src="https://pic3.zhimg.com/50/v2-e854b67f8773a16ceee9063afb2e3a22_720w.jpg?source=1940ef5c" data-caption="" data-size="normal" data-rawwidth="554" data-rawheight="119" class="origin_image zh-lightbox-thumb" width="554" data-original="https://pic3.zhimg.com/v2-e854b67f8773a16ceee9063afb2e3a22_r.jpg?source=1940ef5c"/>
2.3 GHM Loss Focal Loss
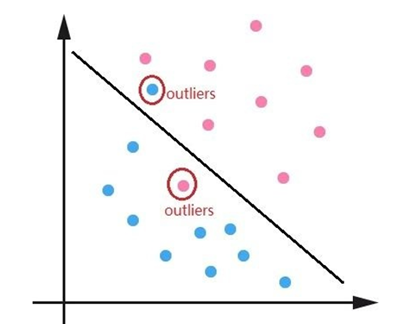
主要结合样本的难易区分程度来解决样本不均衡的问题,使得整个Loss的曲线平滑稳定的下降,但是对于一些特别难区分的样本比如离群点会存在问题。可能一个模型已经收敛训练的很好了,但是因为一些比如标注错误的离群点使得模型去关注这些样本,反而降低了模型的效果。比如下面的离群点图:
<img src="https://pic2.zhimg.com/50/v2-c5dcc8da2004e29c8f81ea4b9426d219_720w.jpg?source=1940ef5c" data-size="normal" data-rawwidth="401" data-rawheight="324" class="content_image" width="401"/> 图4 离群点图
针对Focal Loss存在的问题,2019年论文《Gradient Harmonized Single-stage Detector》中提出了GHM(gradient harmonizing mechanism) Loss。相比于Focal Loss从置信度的角度去调整Loss,GHM Loss则是从一定范围置信度p的样本数量(论文中称为梯度密度)去调整Loss。
3、从数据层面解决样本不均衡问题
从数据层面解决样本不均衡的问题核心是通过人为控制正负样本的比例,分成欠采样和过采样两种。
3.1 欠采样
欠采样的基本做法是这样的,现在我们的正负样本比例为1:100。如果我们想让正负样本比例不超过1:10,那么模型训练的时候数量比较少的正样本也就是100条全部使用,而负样本随机挑选1000条,这样通过人为的方式我们把样本的正负比例强行控制在了1:10。这种方式存在一个问题,为了强行控制样本比例我们生生的舍去了那9000条负样本,这对于模型来说是莫大的损失。
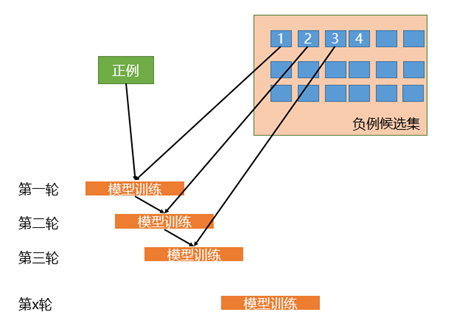
相比于简单的对负样本随机采样的欠采样方法,实际工作中我们会使用迭代预分类的方式来采样负样本。具体流程如下图所示:
<img src="https://pic2.zhimg.com/50/v2-30ecd953c2d11a2ef39cad6f3ec4d48b_720w.jpg?source=1940ef5c" data-size="normal" data-rawwidth="454" data-rawheight="329" class="origin_image zh-lightbox-thumb" width="454" data-original="https://pic1.zhimg.com/v2-30ecd953c2d11a2ef39cad6f3ec4d48b_r.jpg?source=1940ef5c"/> 图7 迭代预分类方式的欠采样
首先我们会使用全部的正样本和从负例候选集中随机采样一部分负样本(这里假如是100条)去训练第一轮分类器;然后用第一轮分类器去预测负例候选集剩余的9900条数据,把9900条负例中预测为正例的样本(也就是预测错误的样本)再随机采样100条和第一轮训练的数据放到一起去训练第二轮分类器;同样的方法用第二轮分类器去预测负例候选集剩余的9800条数据,直到训练的第N轮分类器可以全部识别负例候选集,这就是使用迭代预分类的方式进行欠采样。
相比于随机欠采样来说迭代预分类的欠采样方式能最大限度的利用负样本中差异性较大的负样本,从而在控制正负样本比例的基础上采样出了最有代表意义的负样本。
欠采样的方式整体来说或多或少的会损失一些样本,对于那些需要控制样本量级的场景下比较合适 。如果没有严格控制样本量级的要求那么下面的过采样可能会更加适合你。
3.2 过采样
过采样和上面的欠采样比较类似,都是人工干预控制样本的比例,不同的是过采样不会损失样本 。还拿上面的例子,现在有正样本100条,负样本1W条,最简单的过采样方式是我们会使用全部的负样本1W条,但是为了维持正负样本比例,我们会从正样本中有放回的重复采样,直到获取了1000条正样本,也就是说有些正样本可能会被重复采样到,这样就能保持1:10的正负样本比例了。这是最简单的过采样方式,这种方式可能会存在严重的过拟合。
实际的场景中会通过样本增强的技术来增加正样本。之前组里的小伙伴分享了基于SMOTE算法(SMOTE算法的本质是通过对训练集里的正例进行插值来产生额外的正例)来增加正样本,感兴趣的小伙伴们可以关注下。
4、其他解决样本不均衡问题的策略
4.1 调节阈值修改正负样本比例
参考:https://zhuanlan.zhihu.com/p/259710601?utm_source=wechat_session&utm_medium=social&utm_oi=27198249500672#ref_6
########################################################################################################################
工业界常规做法是随机降采样+校准 (降低训练成本),具体来说
1. 保留全部正样本,负样本按一定比例随机降采样,随机采样主要避免因为采样引入selection bias
2. 用以上样本训练的ctr,打分均值会偏离样本均值。所以上线前要做calibration,常用的方法是保序回归
参考:
https://www.zhihu.com/question/450688180/answer/1820931429



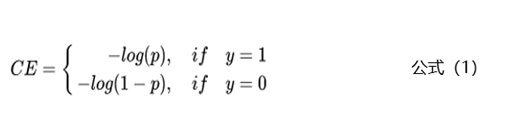
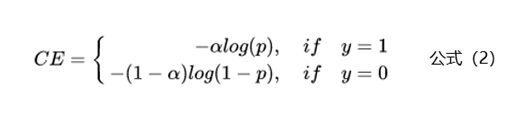
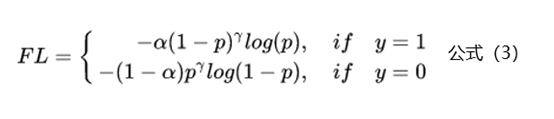


· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
2014-07-11 【APUE】关于信号的一些常用函数
2014-07-11 【Nginx】请求上下文
2014-07-11 【c++】拷贝控制具体分析