


12、优化算法
在机器学习算法中,对于很多监督学习模型,需要对原始的模型构建损失函数,之后通过优化算法对损失函数进行优化,寻找到最优的参数。求解机器学习参数的优化算法中,使用较多的是基于梯度下降的优化算法(Gradient Descent, GD),梯度下降法的含义是通过当前点的梯度方向寻找到新的迭代点。
基本思想可以这样理解:我们从山上的某一点出发,找一个最陡的坡走一步(也就是找梯度方向),到达一个点之后,再找最陡的坡,再走一步,直到我们不断的这么走,走到最“低”点(最小花费函数收敛点)。这里的下山最陡的方向就是梯度的负方向。
通俗来说,梯度就是函数在当前位置的导数。
上式中, 是自变量,
是关于
的函数,
表示梯度。
1、梯度下降法
其中, 是自变量参数,即下山位置坐标,
是学习因子,即下山每次前进的一小步(步长),
是更新后的
,即下山移动一小步之后的位置。
梯度下降算法的公式非常简单!但是”沿着梯度的反方向(坡度最陡)“是我们日常经验得到的,其本质的原因到底是什么呢?为什么局部下降最快的方向就是梯度的负方向呢?接下来我将以通俗的语言来详细解释梯度下降算法公式的数学推导过程。
2、一阶泰勒展开
3、梯度下降数学原理
先写出一阶泰勒展开式的表达式:
其中, 是微小矢量,它的大小就是我们之前讲的步进长度
,类比于下山过程中每次前进的一小步,
为标量,而
的单位向量用
表示。则
可表示为:
特别需要注意的是, 不能太大,因为太大的话,线性近似就不够准确,一阶泰勒近似也不成立了。替换之后,
的表达式为:
重点来了,局部下降的目的是希望每次 更新,都能让函数值
变小。也就是说,上式中,我们希望
。则有:
因为 为标量,且一般设定为正值,所以可以忽略,不等式变成了:
上面这个不等式非常重要! 和
都是向量,
是当前位置的梯度方向,
表示下一步前进的单位向量,是需要我们求解的,有了它,就能根据
确定
值了。
想要两个向量的乘积小于零,我们先来看一下两个向量乘积包含哪几种情况:
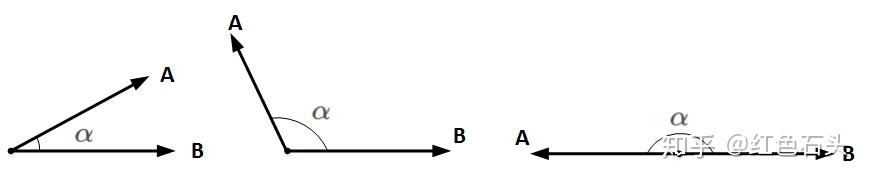
和
均为向量,
为两个向量之间的夹角。
和
的乘积为:
和
均为标量,在
和
确定的情况下,只要
,即
和
完全反向,就能让
和
的向量乘积最小(负最大值)。
顾名思义,当 与
互为反向,即
为当前梯度方向的负方向的时候,能让
最大程度地小,也就保证了
的方向是局部下降最快的方向。
知道 是
的反方向后,可直接得到:
之所以要除以 的模
,是因为
是单位向量。
求出最优解 之后,带入到
中,得:
一般地,因为 是标量,可以并入到步进因子
中,即简化为:
这样,我们就推导得到了梯度下降算法中 的更新表达式。
参考:
https://zhuanlan.zhihu.com/p/36503663
