
深度学习中的注意力模型
Encoder-Decoder框架:
目前大多数注意力模型附着在Encoder-Decoder框架下,当然,其实注意力模型可以看作一种通用的思想,本身并不依赖于特定框架,这点需要注意。
抽象的文本处理领域的Encoder-Decoder框架:
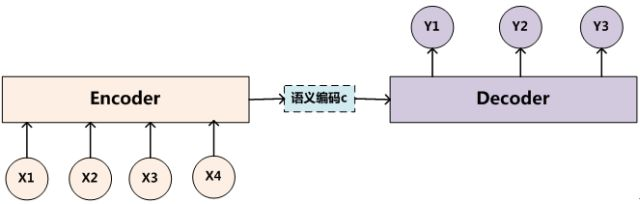
文本处理领域的Encoder-Decoder框架可以这么直观地去理解:可以把它看作适合处理由一个句子(或篇章)生成另外一个句子(或篇章)的通用处理模型。对于句子对<Source,Target>,我们的目标是给定输入句子Source,期待通过Encoder-Decoder框架来生成目标句子Target。
Source和Target分别由各自的单词序列构成: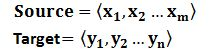
Encoder顾名思义就是对输入句子Source进行编码,将输入句子通过非线性变换转化为中间语义表示C:
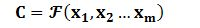
一般而言,文本处理和语音识别的Encoder部分通常采用RNN模型,图像处理的Encoder一般采用CNN模型。
上图展示的Encoder-Decoder框架是没有体现出“注意力模型”的,目标句子Target中每个单词的生成过程如下:
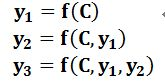
其中f是Decoder的非线性变换函数。从这里可以看出,在生成目标句子的单词时,不论生成哪个单词,它们使用的输入句子Source的语义编码C都是一样的,没有任何区别。而语义编码C是由句子Source的每个单词经过Encoder编码产生的,这意味着不论是生成哪个单词,y1,y2还是y3,其实句子Source中任意单词对生成某个目标单词yi来说影响力都是相同的,这是为何说这个模型没有体现出注意力的缘由。随着输入序列的增长,模型的性能会发生显著下降。编码时输入序列的全部信息压缩到一个向量表示中,随着序列增长,句子越前面的词的信息丢失就越严重。建模时的一个小技巧是将源语言句子逆序输入,或者重复输入两遍来训练模型。
目标句子中的每个单词都应该学会其对应的源语句子中单词的注意力分配概率信息(即source中各单词对当前目标单词的影响力)。这意味着在生成每个单词yi的时候,原先都是相同的中间语义表示C会被替换成根据当前生成单词而不断变化的Ci。理解Attention模型的关键就是这里,即由固定的中间语义表示C换成了根据当前输出单词来调整成加入注意力模型的变化的Ci。增加了注意力模型的Encoder-Decoder框架理解起来如下图所示:
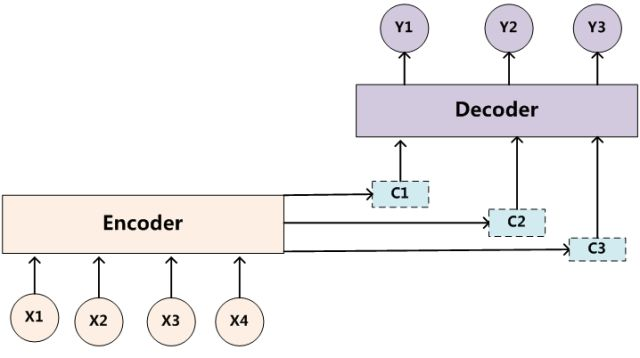
即生成目标句子单词的过程成了下面的形式:
![]()
其中每个Ci可能对应着不同的源句子单词的注意力分配概率分布,关键在于如何获取这里的注意力分配概率。比如对于上面的英汉翻译来说,其对应的信息可能如下:

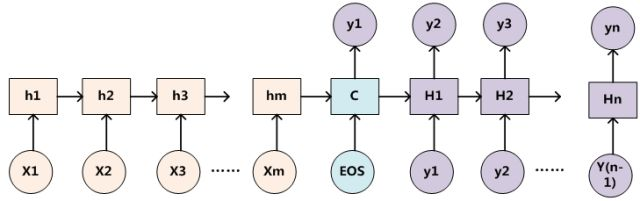
为了便于说明,我们假设对上图的非Attention模型的Encoder-Decoder框架进行细化,Encoder采用RNN模型,Decoder也采用RNN模型,这是比较常见的一种模型配置,则上图的框架转换为下图:
对于采用RNN的Decoder来说,在时刻i,如果要生成yi单词,我们是可以知道Target在生成Yi之前的时刻i-1时,隐层节点i-1时刻的输出值Hi-1的,而我们的目的是要计算生成Yi时输入句子中的单词“Tom”、“Chase”、“Jerry”对Yi来说的注意力分配概率分布,那么可以用Target输出句子i-1时刻的隐层节点状态Hi-1去一一和输入句子Source中每个单词对应的RNN隐层节点状态hj进行对比,即通过函数F(hj,Hi-1)来获得目标单词yi和每个输入单词对应的对齐可能性,这个F函数在不同论文里可能会采取不同的方法,然后函数F的输出经过Softmax进行归一化就得到了符合概率分布取值区间的注意力分配概率分布数值。
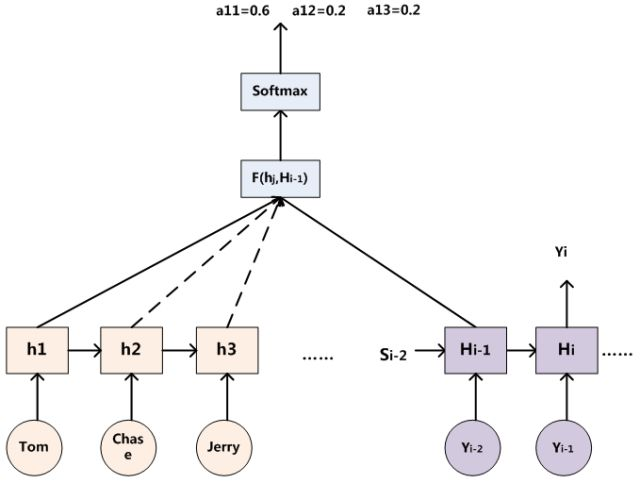 <= 获取注意力分配概率,然后再生成 $C_i$
<= 获取注意力分配概率,然后再生成 $C_i$
Attention机制的本质思想
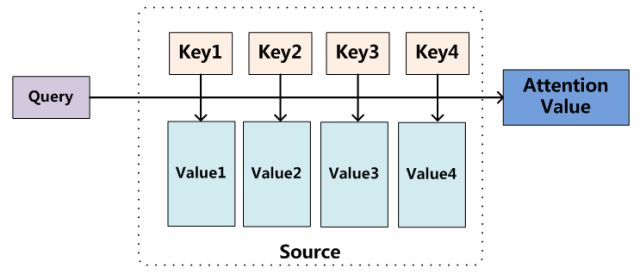
我们可以这样来看待Attention机制(参考上图):将Source中的构成元素想象成是由一系列的<Key,Value>数据对构成,此时给定Target中的某个元素Query,通过计算Query和各个Key的相似性或者相关性,得到每个Key对应Value的权重系数,然后对Value进行加权求和,即得到了最终的Attention数值。所以本质上Attention机制是对Source中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数。
上文所举的机器翻译的例子里,因为在计算Attention的过程中,Source中的Key和Value合二为一,指向的是同一个东西,也即输入句子中每个单词对应的语义编码,所以可能不容易看出这种能够体现本质思想的结构。
当然,从概念上理解,把Attention仍然理解为从大量信息中有选择地筛选出少量重要信息并聚焦到这些重要信息上,忽略大多不重要的信息,这种思路仍然成立。聚焦的过程体现在权重系数的计算上,权重越大越聚焦于其对应的Value值上,即权重代表了信息的重要性,而Value是其对应的信息。
Attention机制的具体计算过程,如果对目前大多数方法进行抽象的话,可以将其归纳为两个过程:第一个过程是根据Query和Key计算权重系数,第二个过程根据权重系数对Value进行加权求和。而第一个过程又可以细分为两个阶段:第一个阶段根据Query和Key计算两者的相似性或者相关性;第二个阶段对第一阶段的原始分值进行归一化处理;
第一阶段最常见的方法包括:求两者的向量点积、求两者的向量Cosine相似性或者通过再引入额外的神经网络来求值

第二阶段引入类似SoftMax的计算方式对第一阶段的得分进行数值转换,一方面可以进行归一化,将原始计算分值整理成所有元素权重之和为1的概率分布;另一方面也可以通过SoftMax的内在机制更加突出重要元素的权重
![]()
第三阶段:
![]()
1、图像描述生成(Image Caption Generation)
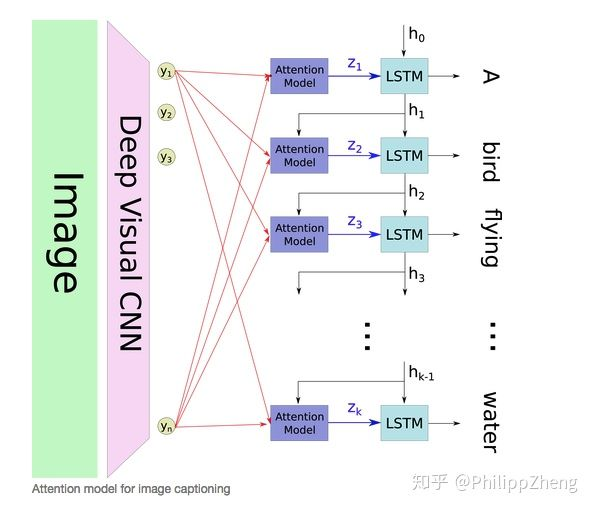
文章提出了两种attention模式,即hard attention 和soft attention:

hard attention会专注于很小的区域,而soft attention的注意力相对发散。模型的encoder利用CNN(VGG net),提取出图像的 个
维的向量
,每个向量表示图像的一部分信息。decoder是一个LSTM,每个timestep
的输入包含三个部分,即context vector
、前一个timestep的hidden state
、前一个timestep的output
。
由{
}和权重{
}通过加权得到。这里的权重
通过attention模型
来计算得到,而本文中的
是一个多层感知机(multilayer perceptron)。
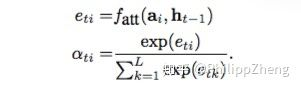
 前一个timestep的hidden state $h_{t-1}$与encoder中每一个时间步的隐层状态作为MLP的输入,通过softmax归一化,即可得到注意力概率。
前一个timestep的hidden state $h_{t-1}$与encoder中每一个时间步的隐层状态作为MLP的输入,通过softmax归一化,即可得到注意力概率。
从而可以计算 。
1) Stochastic “Hard” Attention
记 为decoder第
个时刻的attention所关注的位置编号,
表示第
时刻attention是否关注位置
,
服从多元伯努利分布(multinoulli distribution), 对于任意的
,
中有且只有取1,其余全部为0,所以
是one-hot形式。这种attention每次只focus一个位置的做法,就是“hard”称谓的来源。
也就被视为一个变量,计算如下
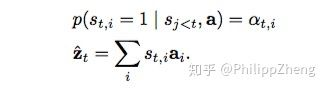
2)Deterministic “Soft” Attention
在hard attention里面,每个时刻 模型的序列 [
] 只有一个取1,其余全部为0,也就是说每次只focus一个位置,而soft attention每次会考虑到全部的位置,只是不同位置的权重不同罢了。这时
即为
的加权求和
。
2、两种attention的改进版本:global attention和local attention
1)global attention
global attention 在计算context vector 的时候会考虑encoder所产生的全部hidden state。记decoder时刻
的target hidden为
,encoder的全部hidden state为
,对于其中任意
,其权重
为
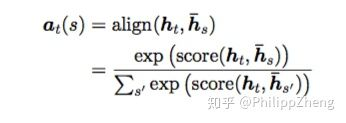
在得到这些权重后, 的计算是很自然的,即为
的weighted summation。
机器翻译在encoder端以时序输入了一句话,context vector表示为各个词语的加权语义向量。
2)local attention
global attention可能的缺点在于每次都要扫描全部的source hidden state,计算开销较大,对于长句翻译不利,为了提升效率,提出local attention,每次只forcus一小部分的source position。
这里,context vector 的计算只forcus窗口
内的
个source hidden states(若发生越界,则忽略界外的source hidden states)。其中
是一个source position index,可以理解为attention的“焦点”,作为模型的参数,
根据经验来选择
关于 的计算,文章给出了两种计算方案,
i)Monotonic alignment (local-m)
ii) Predictive alignment (local-p)
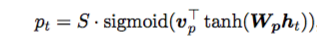
其中 和
是模型的参数,
是source sentence的长度,易知
。
权重 的计算如下
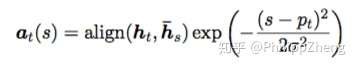
可以看出,距离中心 越远的位置,其位置上的source hidden state对应的权重就会被压缩地越厉害。
参考:
https://zhuanlan.zhihu.com/p/37601161
https://github.com/Choco31415/Attention_Network_With_Keras
https://zhuanlan.zhihu.com/p/37835894 Attention模型方法综述 | 多篇经典论文解读
