
前段时间,跟部门同事分享了深度学习相关的一些理论基础,在此记录一下。仅供后续学习和复习。
目录
1、背景及现状
2、Embeding
3、DNN
4、CNN
5、RNN(LSTM)
6、应用(结合自身的应用案例)
(1)情感分析/类目预测(文本分类)
(2)NER/POS TAGGING (标注、命名实体识别)
(3)流量预测
(4)CTR预估
7、总结与挑战
一、背景与现状
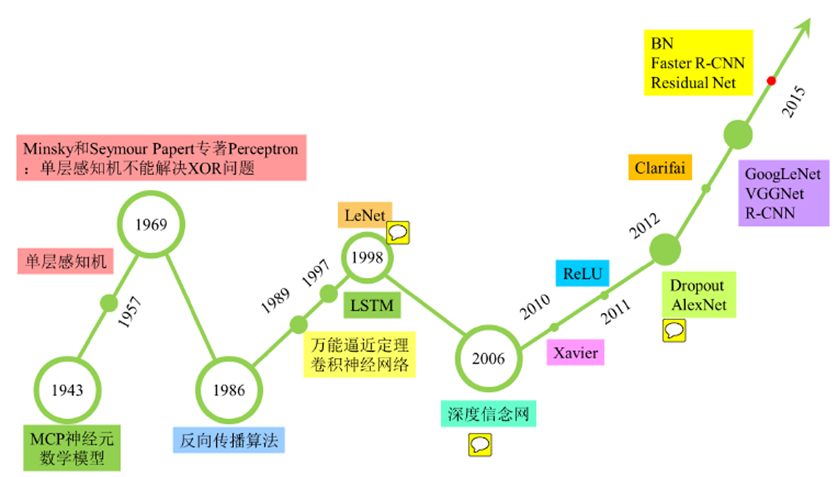
上图基本说明深度学习的发展历史,简要说明如下:
1、MCP人工神经元模型,但是还是比较简单的单层感知机的形式,改模型被证明是一种线性模型,只能解决线性问题,就连最简单的异或都无法正确分类。于是迎来了神经网络的第一次低谷。
2、到了1986年,由于BP算法的发明,人们提出了多层的神经网络,当时被证明是可以逼近任何一个连续的函数。(包括非线性问题)。那个时候比较有代表性的是BP神经网络;然而当时提出的网络缺乏理论支持,并且又被指出BP反向传播算法存在梯度消失的情况,又一次让深度学习陷入谷底。
3、2012年,再一次ImageNet图像识别比赛中,Hinton团队采用了CNN构建的AlexNet网络,直接碾压第二名,获得比赛冠军。当时AlexNet的创新点是:(1)采用ReLU激活函数,能够解决梯度消失的问题。(2)采用GPU对计算进行加速(3)添加了DropOut层减少过拟合,增强泛化能力。
二、Embeding
(1)Word2Vec
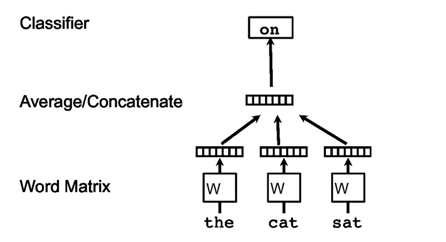
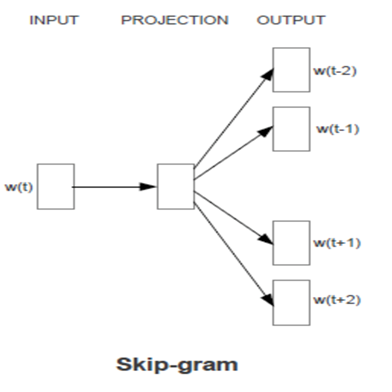
该方法是一个三层的神经网络,分别利用CBOW(利用上下文预测当前单词)和Skip-Gram(利用当前单词预测上下文)两种方式进行训练。
CBOW:
Skip-Gram:
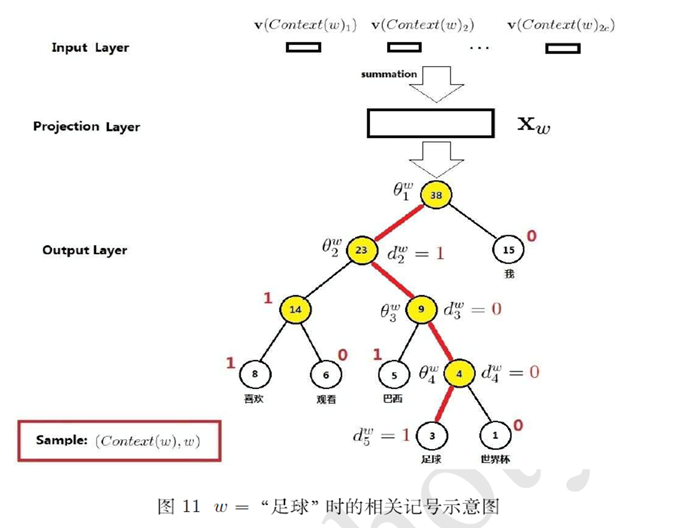
这里需要注意的是,
1)三层的神经网络结构。其中输出层为了减少算法的复杂度,采用Huffman编码树的形式进行编码输出。即输出一颗树型结构。
2)训练过程中,实际是需要两次遍历预料,第一次遍历构建输出的Huffman树和字典,第二次遍历进行训练。
(2)Paragraph2Vec、Doc2vec
该方法类似word2vec,只是在训练的过程中,增加了paragraph vector(段落向量)
(3)Glove
该方法用的是词的共现矩阵通过矩阵分解得到全局的信息,并且得到每个词对应的全局词向量,
再根据CBOW的思想(利用上下文预测当前单词的概率,这里的概率就是共现矩阵中共现概率比值)进行优化全局词向量,进而得到最优的词向量。

三、DNN
1、神经网络的思想源于生物医学上的感知器,启用计算机模拟如下:
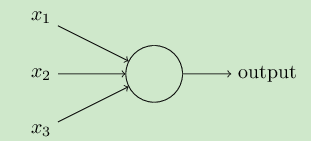
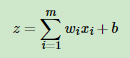 ,
,
典型的DNN模型如下所示:

前向输入后向传播:
这里主要讲解一下训练过程中是如何训练的,参数是如何更新迭代的,这里采用一个例子进行说明:
假如有这样一个网络:
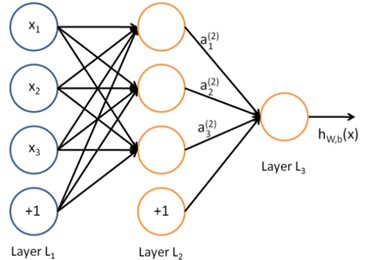
第一层是输入,第二层是隐藏层,第三层是输出层。
(1)前向运算:
1)第二层输出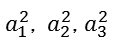 ,如下所示:
,如下所示:
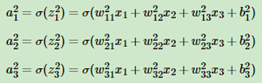
2)第三层输出:

则一般通用公式如下:
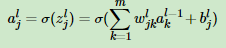 ,
,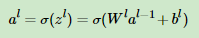
反向传播(BP算法):(这里需要理解为何需要反向传播?主要是为了更新网络参数)
我们知道前向传播的算是函数如下:
 ,进一步展开得到如下:
,进一步展开得到如下:

对损失函数求导可得:
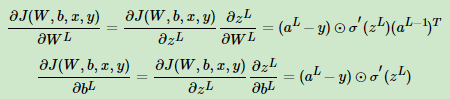
我们假设: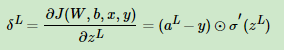 ,则导数可以变换成如下所示:
,则导数可以变换成如下所示:
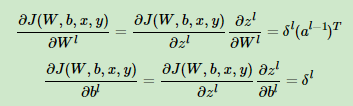
我没来看看对应的
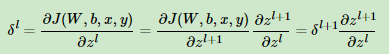
则有: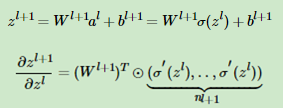 ,即
,即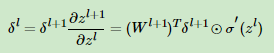
得到了梯度之后,我们即可得到每层的权重更新的方法。
四、CNN
首先来看一下CNN的网络结构及特性:(1)局部感知,(2)权值共享。从整体上,采用通信里面的知识理解CNN,本质是一个滤波器,只是该滤波器是通过卷积的方式进行滤波。这里需要注意的地方是,卷积层的输出神经元个数分别维护一个卷积算子的权重。每个输出的神经元可以理解成就是一个滤波器,多少个神经元就有多少个滤波器。(在分享时,发现很多人这里不是很理解。。。)

例如:
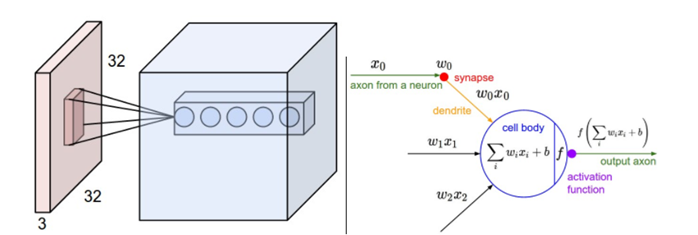 ,假设我们的卷积因子是
,假设我们的卷积因子是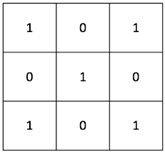 ,则有如下所示:
,则有如下所示:
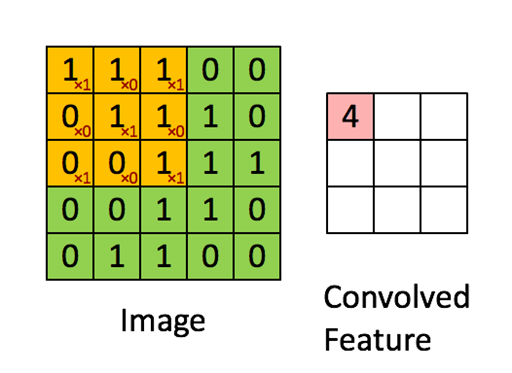
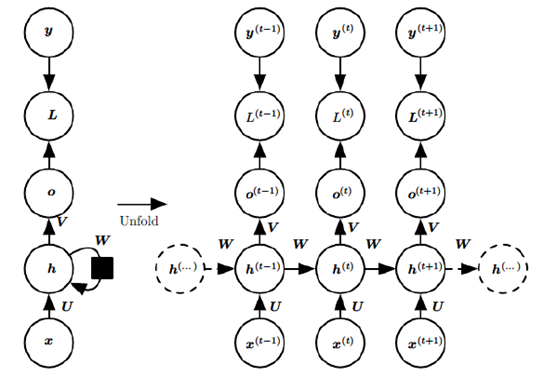
五、RNN(LSTM)
经典RNN结构如下所示:这里由于篇幅的问题,本来是也想说一下它的训练过程中参数是如何更新的。这里就略过,感兴趣的可以留言。主要跟CNN类似,不同的地方是它加上了时间维度。称之为(BPTT算法)。
重点讲一下LSTM,这里主要讲解一下我自己对LSTM的理解,如果需要知道其他方面的内容可以网上查阅相关资料,这方面还挺详细的。这里我也把它相关的结构图贴上来:
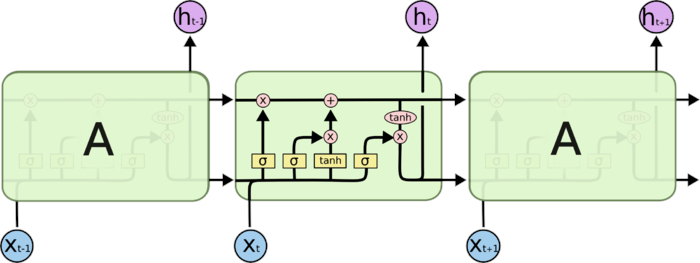
理解经典LSTM网络结构主要包含三个部门,分别是:遗忘门,输入门,输出门
1、遗忘门:指的是上一状态的记忆,在当前状态下,有多少信息是可以遗忘的。这里主要是通过一个sigmod函数进行加权得到有多少信息作为当前状态的记忆保留下来。
2、输入门:由于上一状态记忆会有一个遗失过程,当前状态可以根据当前输入x和上一状态记忆决定当前状态下,有多少信息可以添加到记忆(信息流)中去。这里有一个加法操作和一个sigmod函数决定添加多少信息。信息时通过输入x和上一状态记忆通过tan函数得到当前状态的信息
3、输出门:根据当前状态的输入x和上一状态记忆,通过sigmod函数决定当前状态记忆信息多少可以输出。当前状态记忆信息是由输入门添加的信息+上一状态保留的信息通过tanh函数得到信息
注意:输入门和输出门对应的tanh输入的内容是不一样的。输入门对应的输入时输入x和上一状态记忆;输出门对应的是加法之后的记忆信息。
六、应用
1、文本分类
LSTM
2、NER
BI-LSTM+CRF
3、流量预测
LSTM
4、CTR预估
Wide-Deep


