LightGBM是Boosting算法的一种,与GBDT、XGBOOST是属于同一类算法,很多情况下可能会需要lightGBM与GBDT、xgb进行比较。这里花点时间简单比较一下:
一、GBDT
GBDT是通过使用回归树来构建每一个弱分类器,(具体为啥使用回归树的原因是因为GBDT是由于每次迭代都是拟合上一颗树的残差(一阶梯度且是负梯度),最后所有的树结果求和即使最后结果。只有回归树才可以实现求和,那这里还会涉及到如何构建回归树,以及特征分裂点的选择的方法及其比较。相关的衍生内容很多,这里暂且点到为止)。
优点:
(1) 可以灵活处理各种类型的数据,包括连续值和离散值。
(2) 在相对少的调参时间情况下,预测的准确率也可以比较高。这个是相对SVM来说的。
(3)使用一些健壮的损失函数,对异常值的鲁棒性非常强。比如 Huber损失函数和Quantile损失函数。
缺点:
(1)训练过程需要串行训练,只能在决策树内部采用一些局部并行的手段提高训练速度。
二、XGBOOST
XGB是在GBDT的基础上做了一些优化和改进,主要是(1)损失函数是二阶泰勒展开,相比GBDT一阶精度更高;(2)在损失函数中引入了正则化约束,防止模型过度复杂,降低了过拟合的可能性(3)可并行计算,注意这里的并行实际上是特征计算的并行化(比如,计算特征最佳分裂点等)
缺点:
(1)续建进行特征预排序,预排序需要消耗大量内存,算法训练过程中时间复杂度较高
三、lightGBM
进入本文的重点内容了,LightGBM在GBDT、XGBoost基础上针对这个做了优化,主要表现在两个方面:
1、尽量减少样本数据
(1)通过GOSS(gradient of sildes sampling)的方法,即对样本按照梯度的大小进行降序排序,注意:梯度比较小的样本是模型已经学习到了,所以对应的误差小,即梯度小。
(2)GOSS的思想就是保留那些没有学习到的样本(梯度比较大的样本)
(3)对梯度较小的样本进行随机采样的方法来保证 整体样本的分布。这里面会涉及到两个参数:一个梯度大的样本采样比例a;另一个是梯度小的样本采样比例b。
2、尽量减少特征
(1)减少特征的方法就是合并特征:如何合并特征,论文提出的方法是扩展特征的边界。比如:特征A对应的边界是(0,10],特征B的边界是(0,20],则合并的 方法是在特征B的基础上+10,再融合特征A得到特征C的边界是(0,30]。
(2)具体如何去找那些特征应该合并呢?
方法是:通过构建有颜色的直方图的方法。即将特征作为顶点,如果两个特征不会相互排斥则构建一条边。不会相互排斥的特征非常少,一般情况算法是容忍一定比例的冲突。
四、实践
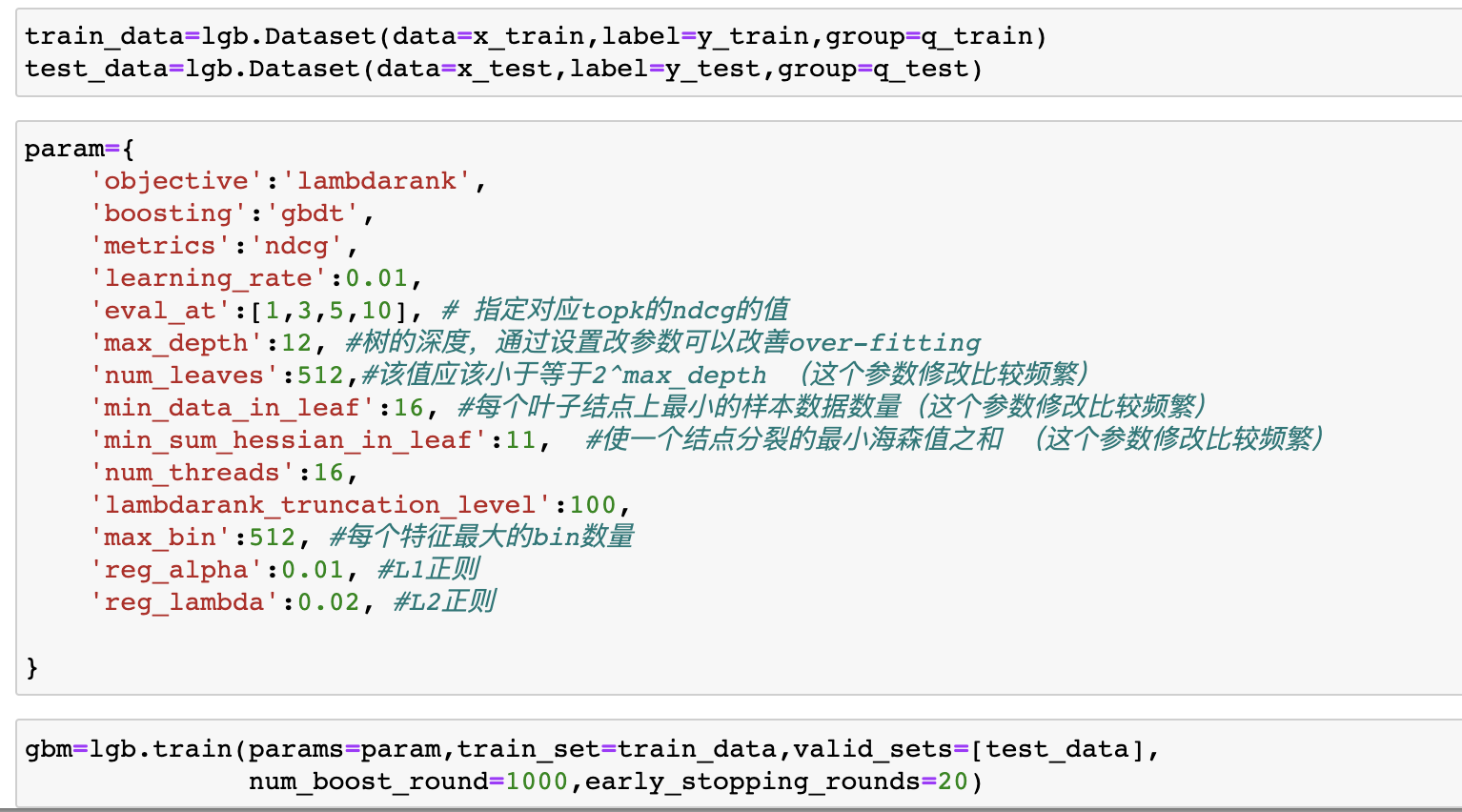
lightGBM在实际使用的过程中,主要是调参数。
1、回归/分类
这里贴上关键部分代码:

2、LTR