《信息安全系统设计与实现》第二周学习笔记
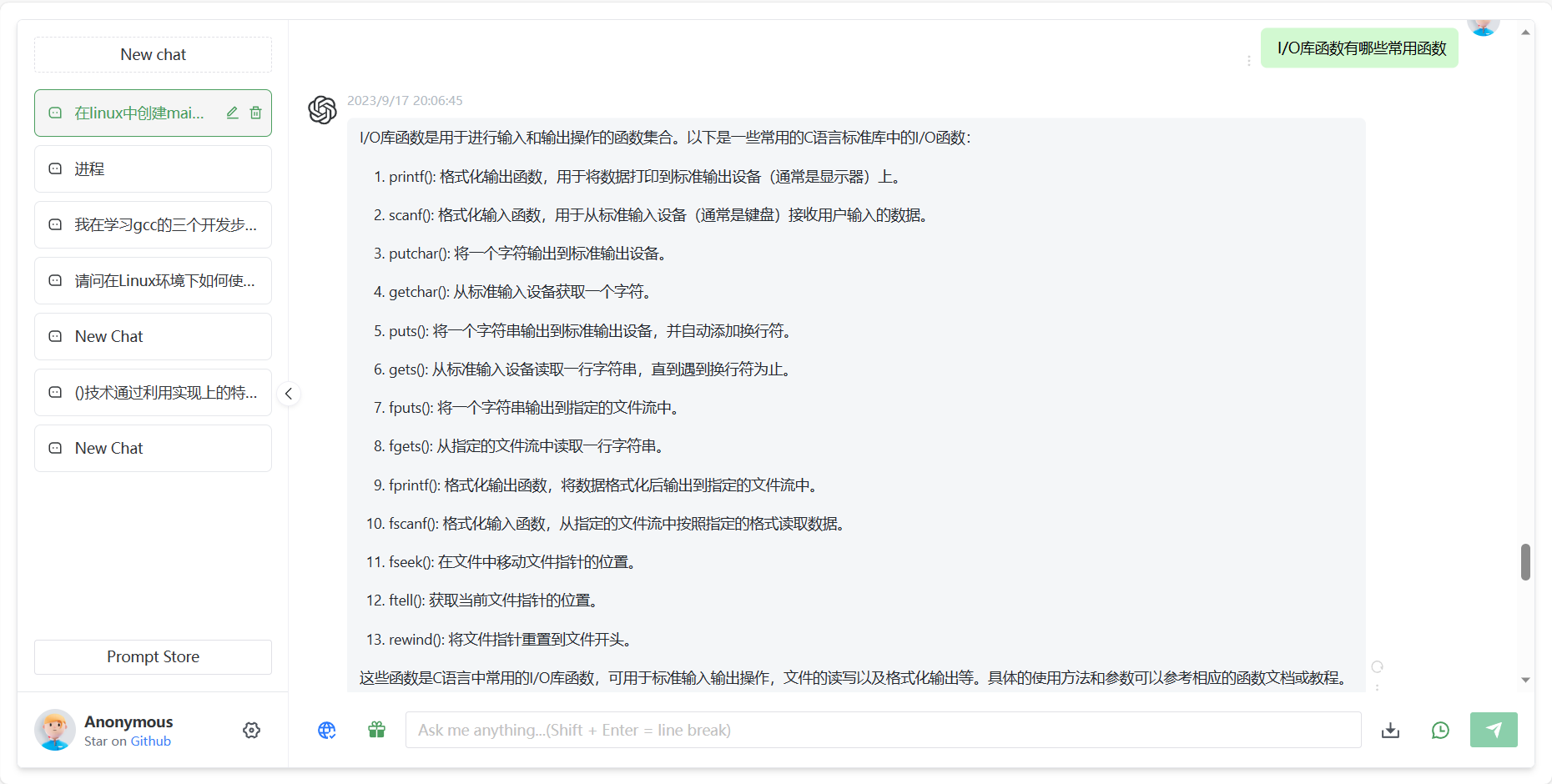
scanf(): 格式化输入函数,用于从标准输入设备(通常是键盘)接收用户输入的数据。
putchar(): 将一个字符输出到标准输出设备。
getchar(): 从标准输入设备获取一个字符。
puts(): 将一个字符串输出到标准输出设备,并自动添加换行符。
gets(): 从标准输入设备读取一行字符串,直到遇到换行符为止。
fputs(): 将一个字符串输出到指定的文件流中。
fgets(): 从指定的文件流中读取一行字符串。
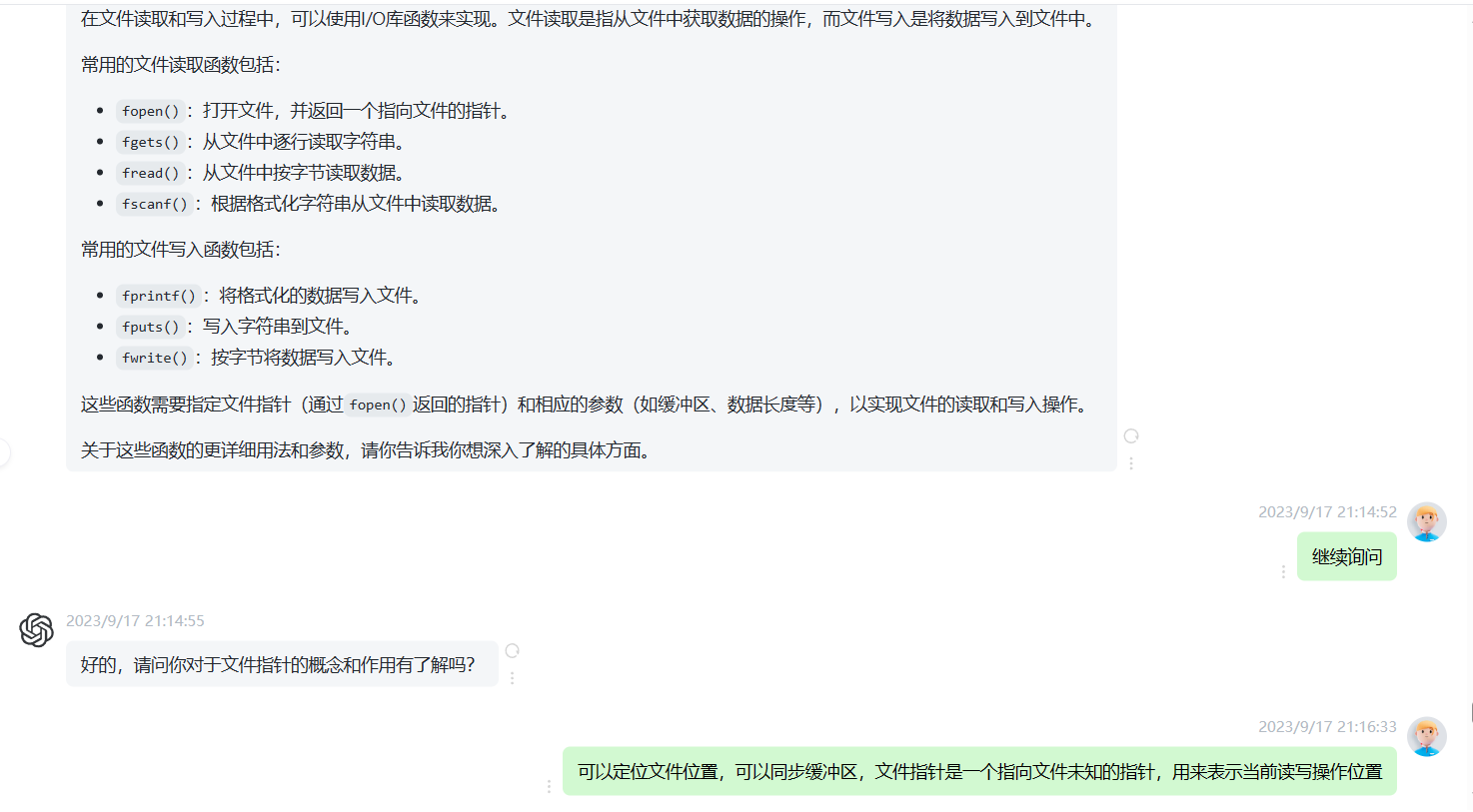
fprintf(): 格式化输出函数,将数据格式化后输出到指定的文件流中。
fscanf(): 格式化输入函数,从指定的文件流中按照指定的格式读取数据。
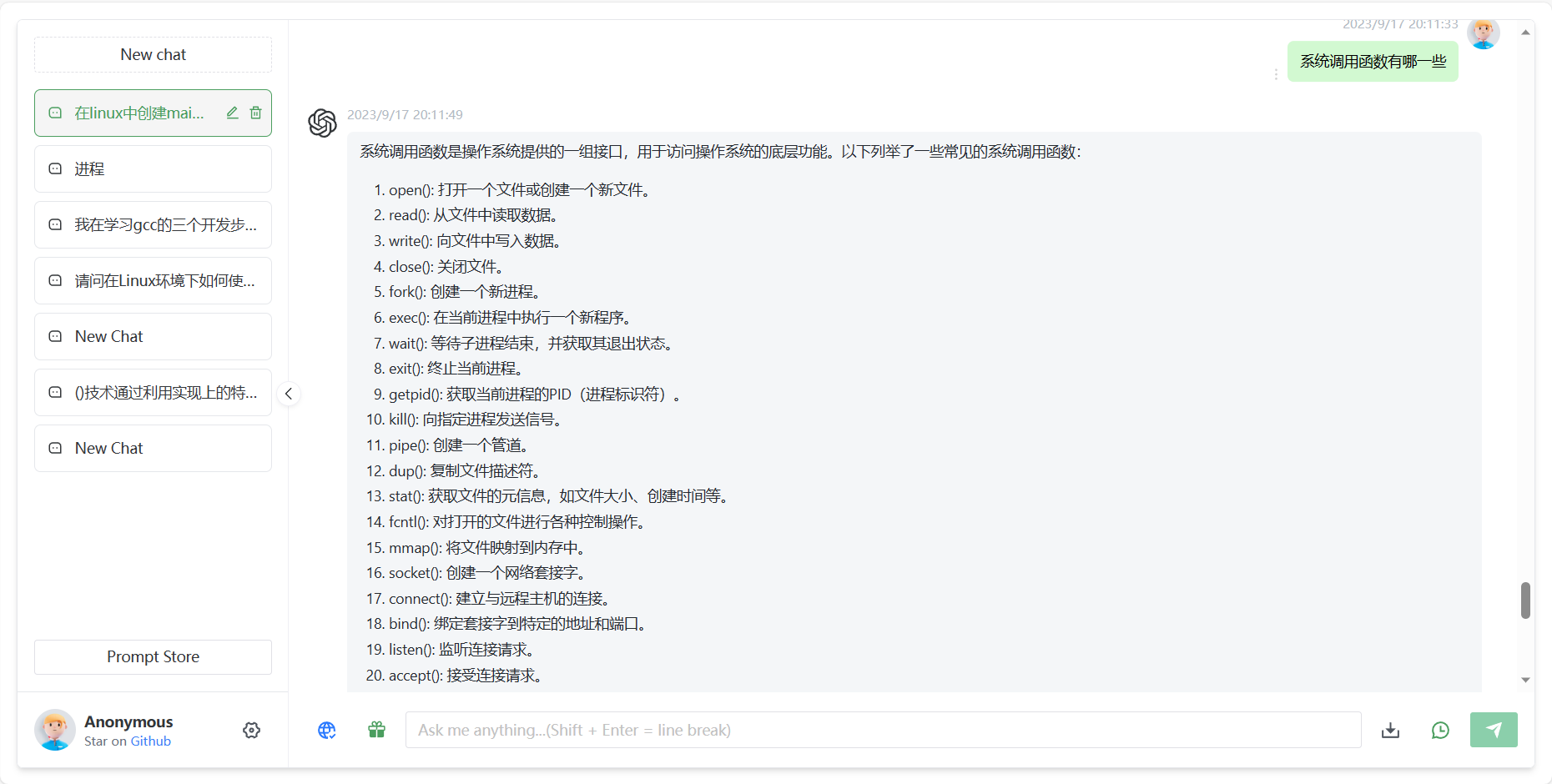
系统调用函数:
open(): 打开一个文件或创建一个新文件。
read(): 从文件中读取数据。
write(): 向文件中写入数据。
close(): 关闭文件。
i/o库函数的算法:
fopen(): 打开文件并返回一个文件指针。
fclose(): 关闭文件。
fseek(): 在文件中定位文件指针的位置。
fread(): 从文件中读取一块数据。
fwrite(): 将数据写入文件。
feof(): 判断是否已到达文件末尾。
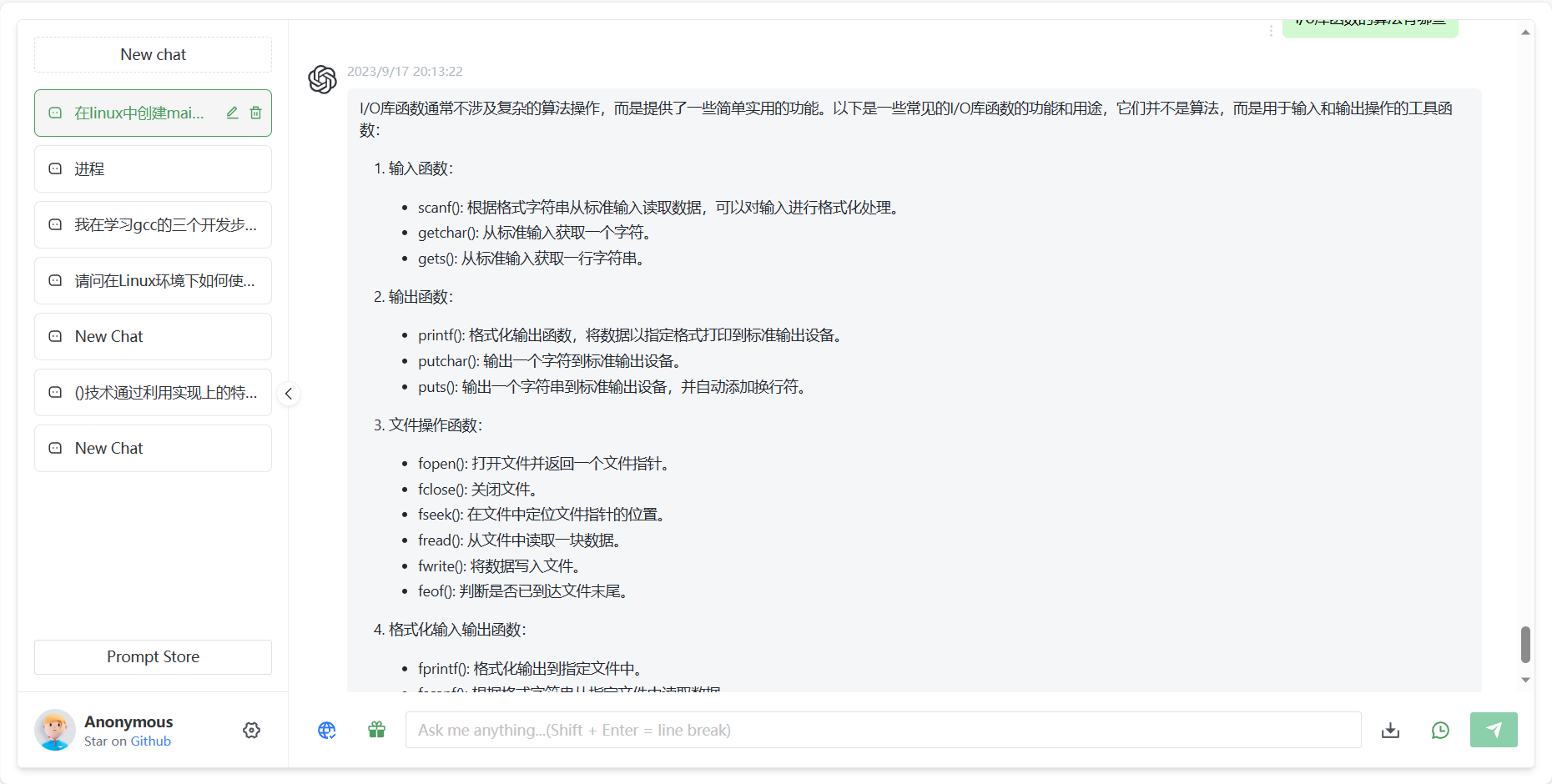
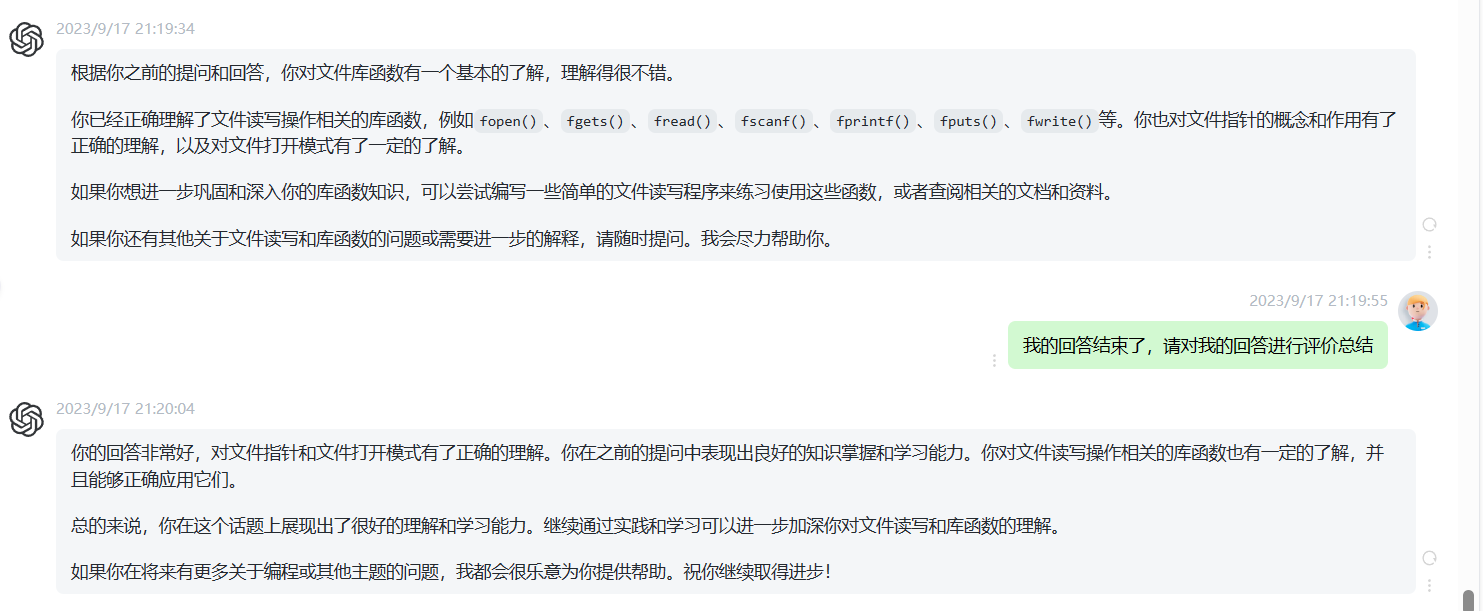
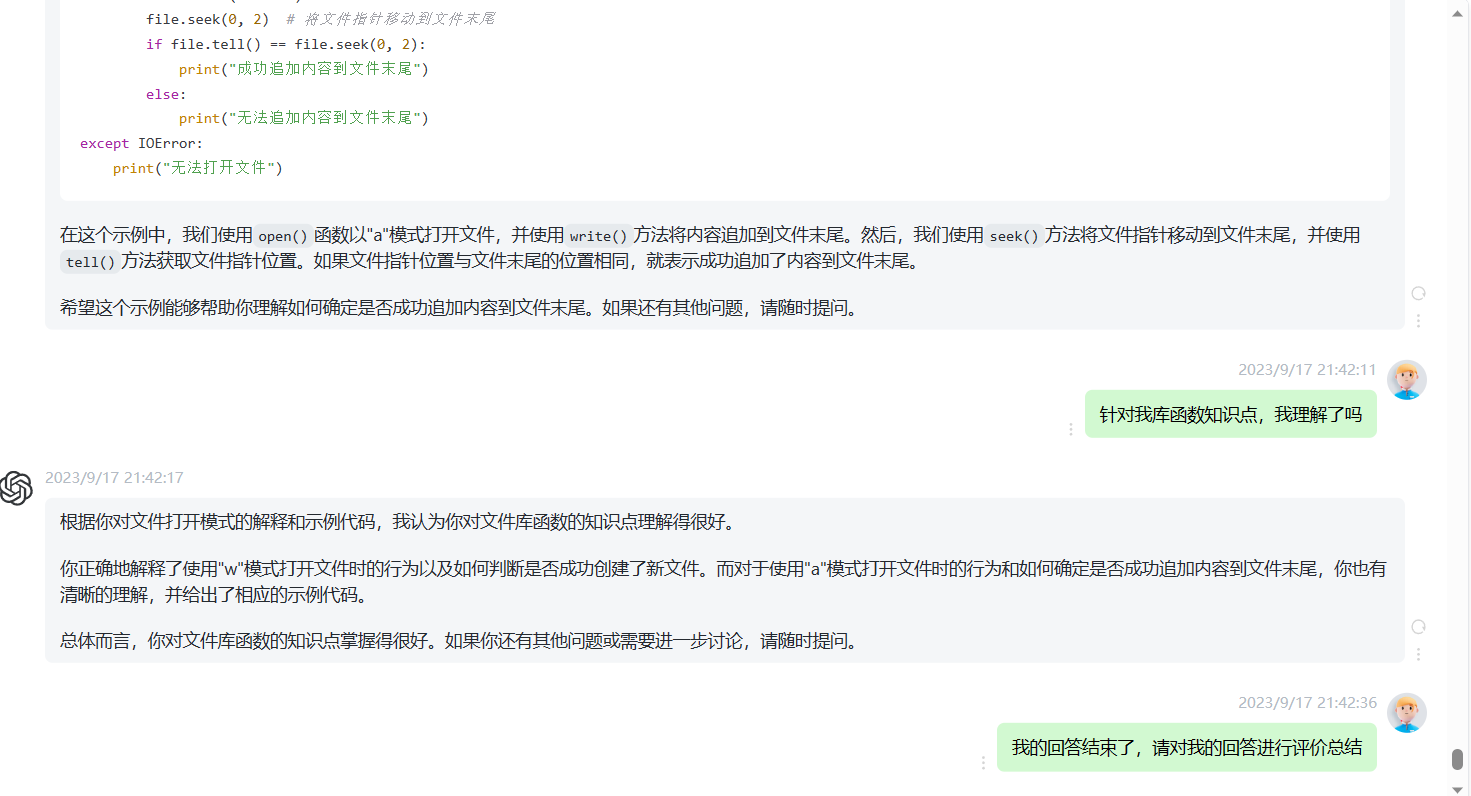
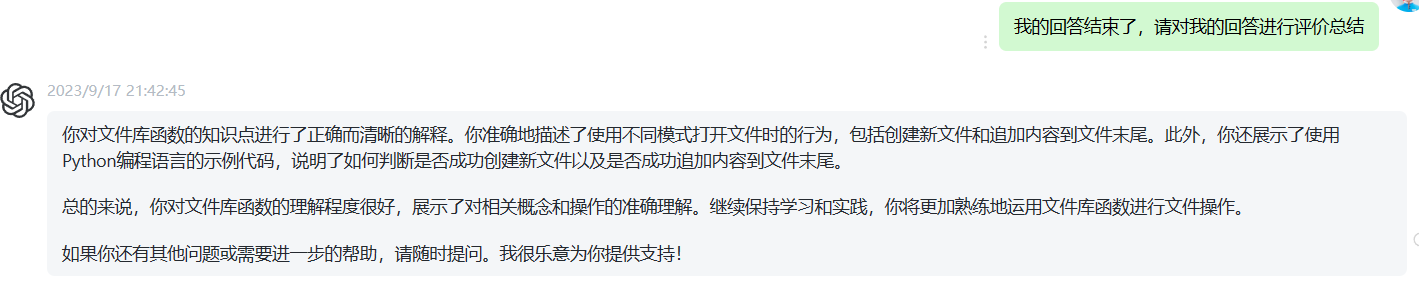
实践:编写一个c程序,计算文本文件的行数:
先询问gpt该实验的代码以及实验流程:
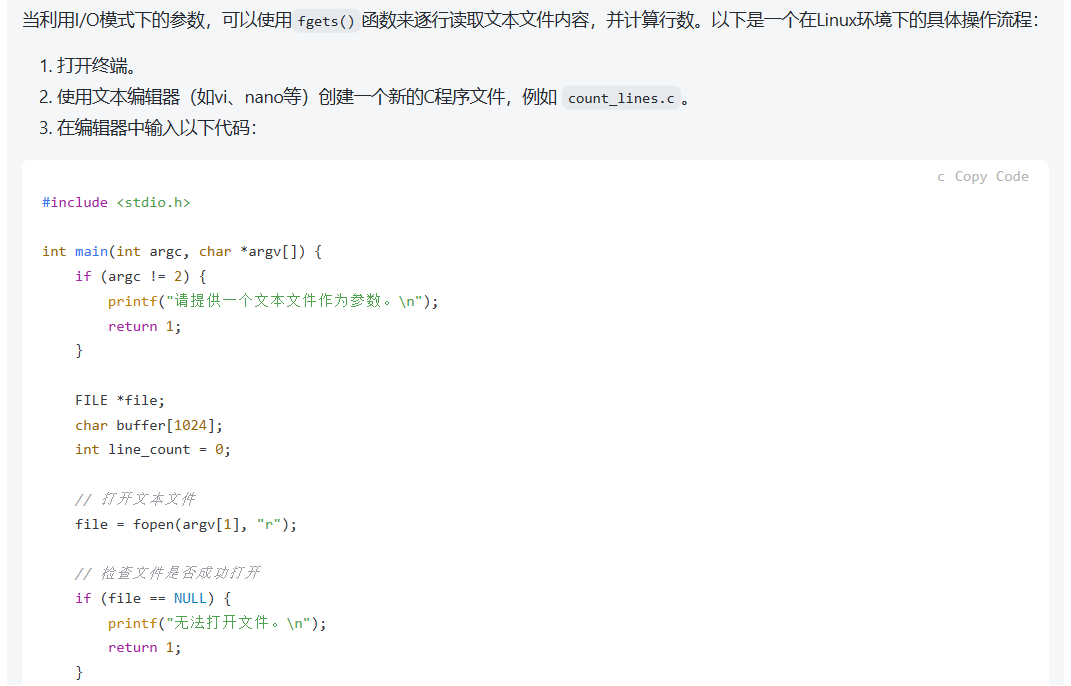
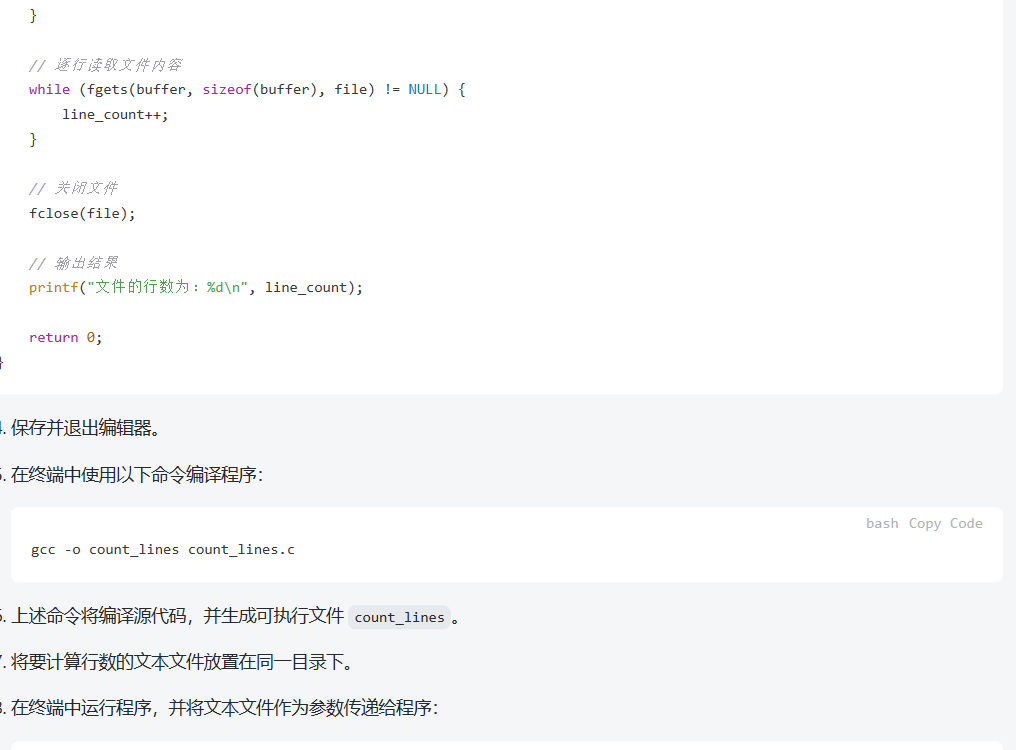
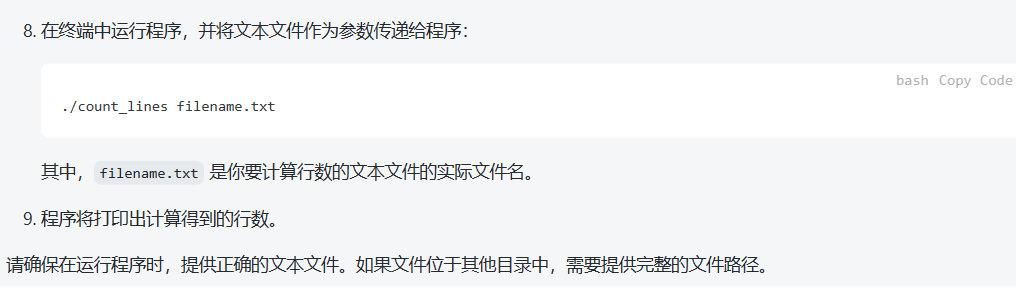
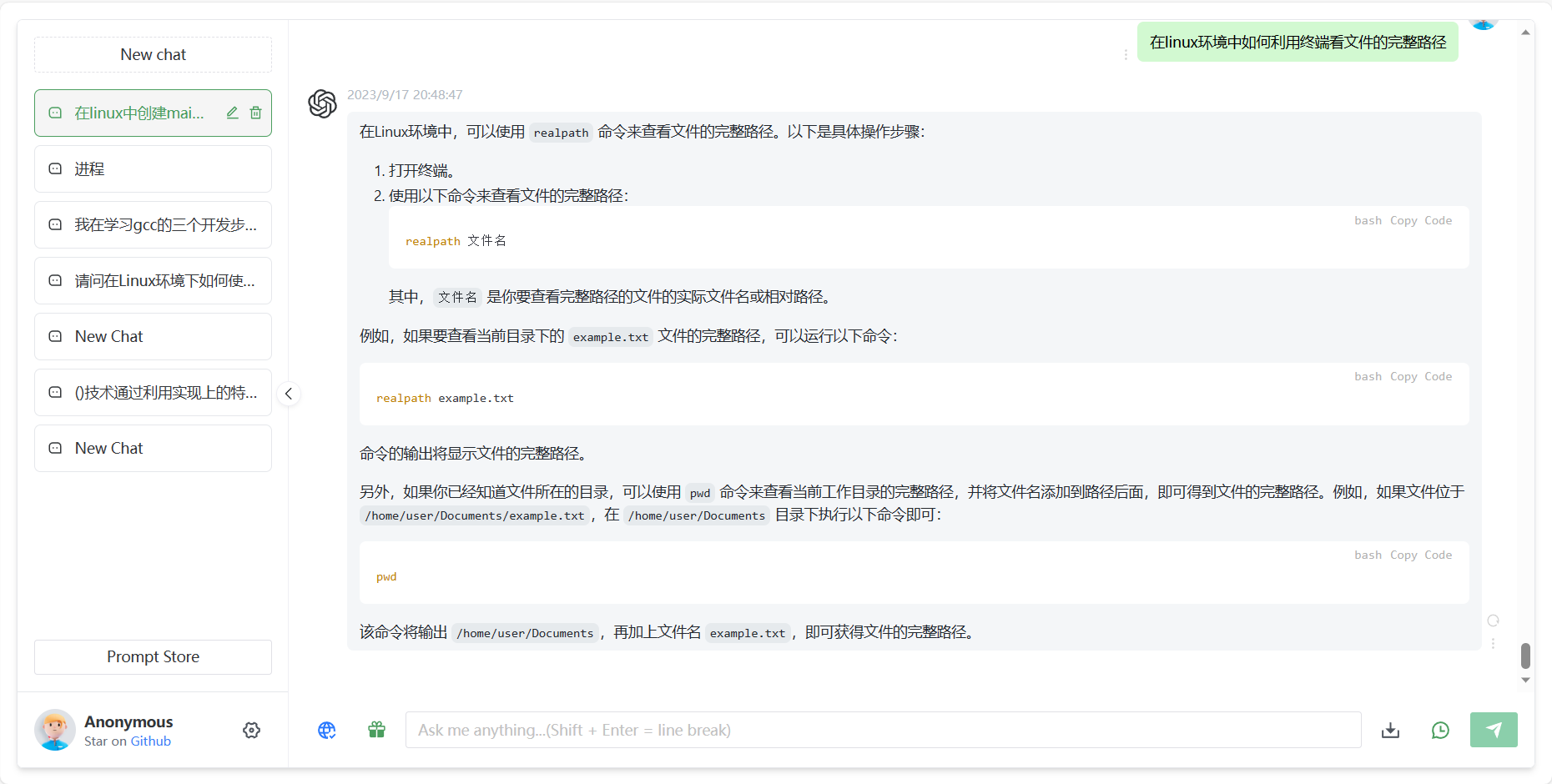
在linux环境中实践:
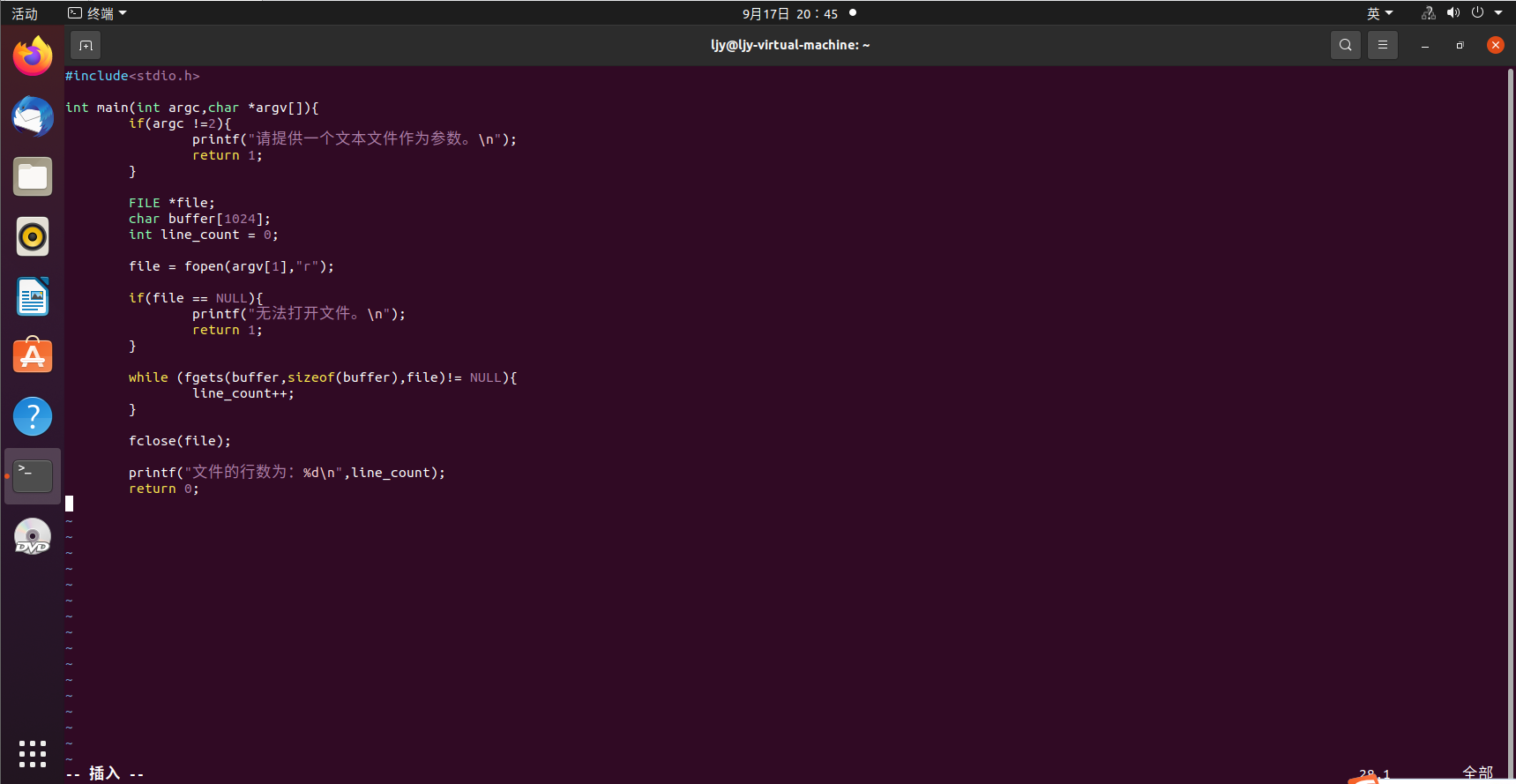

a.txt中的内容:
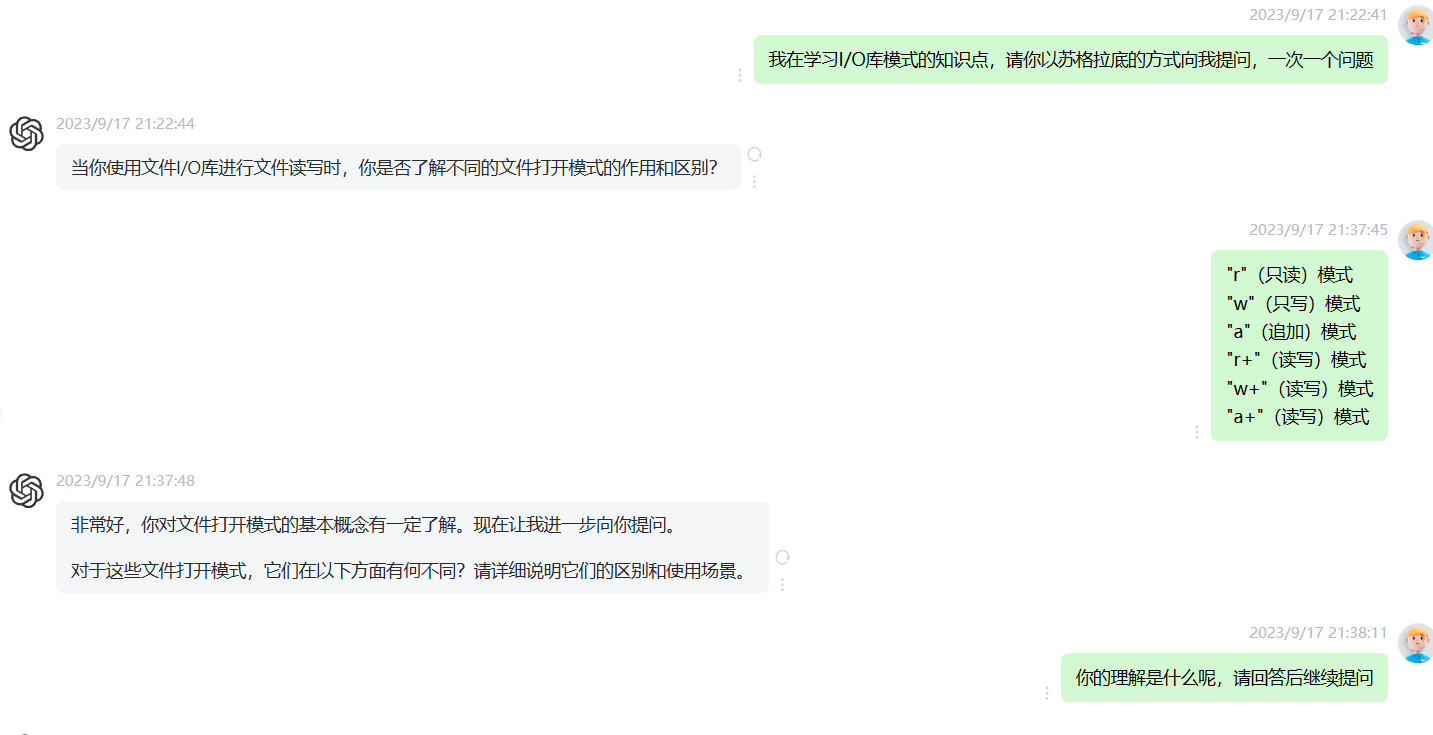
I/O库模式:
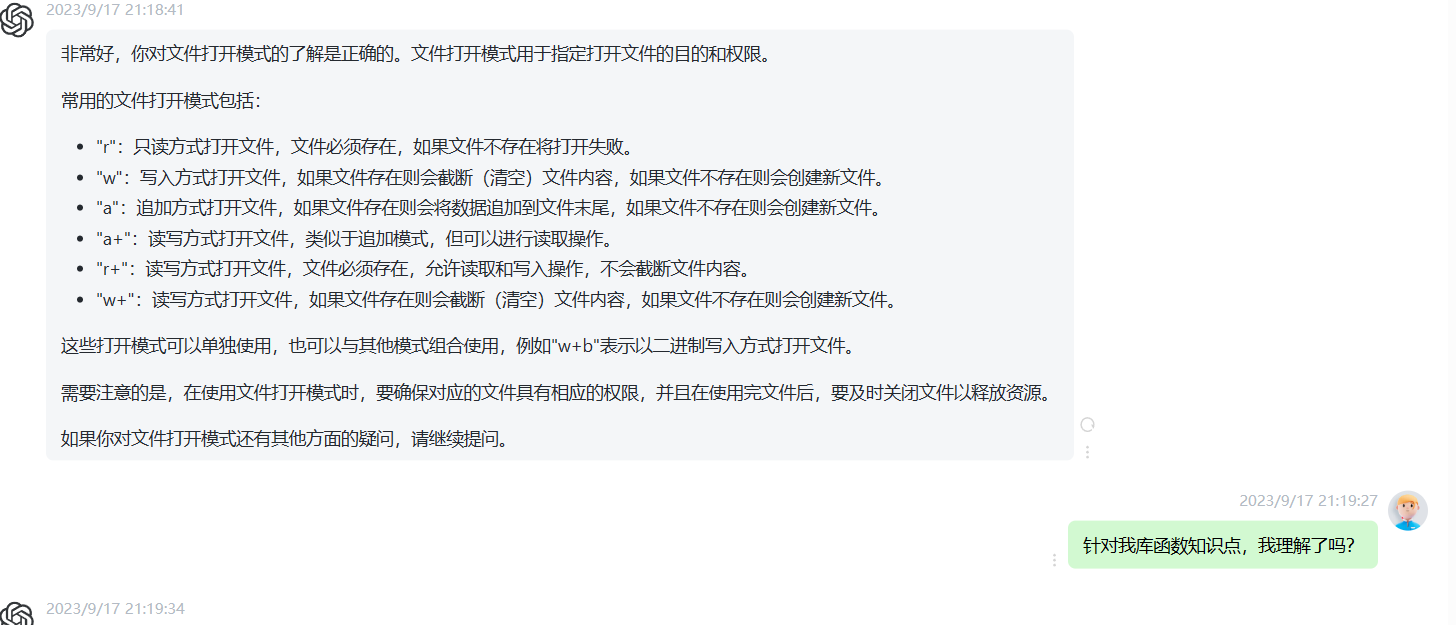
文本模式:在文本模式下,I/O库会将文件内容看作是由文本字符组成的,对于不同操作系统之间的行尾符号进行转换,并且在每行末尾添加一个 NULL 字符表示行的结束。在默认情况下,文本模式下的文件以文本形式呈现。可以使用 fopen() 函数的 "r" 或 "w" 模式打开文件。
二进制模式:在二进制模式下,I/O库会将文件内容看作是由字节组成的,并不会对它们进行任何处理。因此,在此模式下,不能够对行尾符号进行自动转换和追加 NULL 字符。可以使用 fopen() 函数的 "rb" 或 "wb" 模式打开文件。
更新模式:更新模式是同时支持读取和写入的,需要使用 fopen() 函数的 "r+" 或 "w+" 模式打开文件。在此模式下,文件指针可以在读写操作中进行移动,并且既可以使用 fread() 函数读取文件,也可以使用 fwrite() 函数写入文件。但是,在同一时刻只能进行一个操作。
文件流缓冲:
文件流缓冲有三种类型:
全缓冲:当使用标准I/O函数处理输出流时,默认情况下会使用全缓冲模式。在全缓冲模式下,数据会等到缓冲区填满或者遇到特定条件(例如换行符 \n)时才会进行实际的写入操作。此时,才会将缓冲区的数据一次性写入磁盘。这种模式适用于大量数据的写入,可以减少实际的磁盘I/O次数,提高效率。
行缓冲:当使用标准I/O函数处理输出流时,如果输出流关联的是一个终端设备(如终端窗口),则会使用行缓冲模式。在行缓冲模式下,数据会在遇到换行符 \n 时进行实际的写入操作,并且会立即显示在终端上。这样做可以实现实时的输出显示,提高用户交互的体验。例如,使用 printf() 函数输出内容到终端时就是行缓冲模式。
无缓冲:当使用标准I/O函数处理错误流 stderr 时,默认情况下会使用无缓冲模式。在无缓冲模式下,数据会立即进行实际的写入操作,而不会进行缓冲。这样可以确保错误信息尽快地输出,而不会因为缓冲等待而导致延迟。
需要注意的是,可以使用 setvbuf() 函数来设置特定文件流的缓冲模式,包括全缓冲、行缓冲和无缓冲模式。可以根据具体的需求选择适合的缓冲模式来进行文件读写操作。
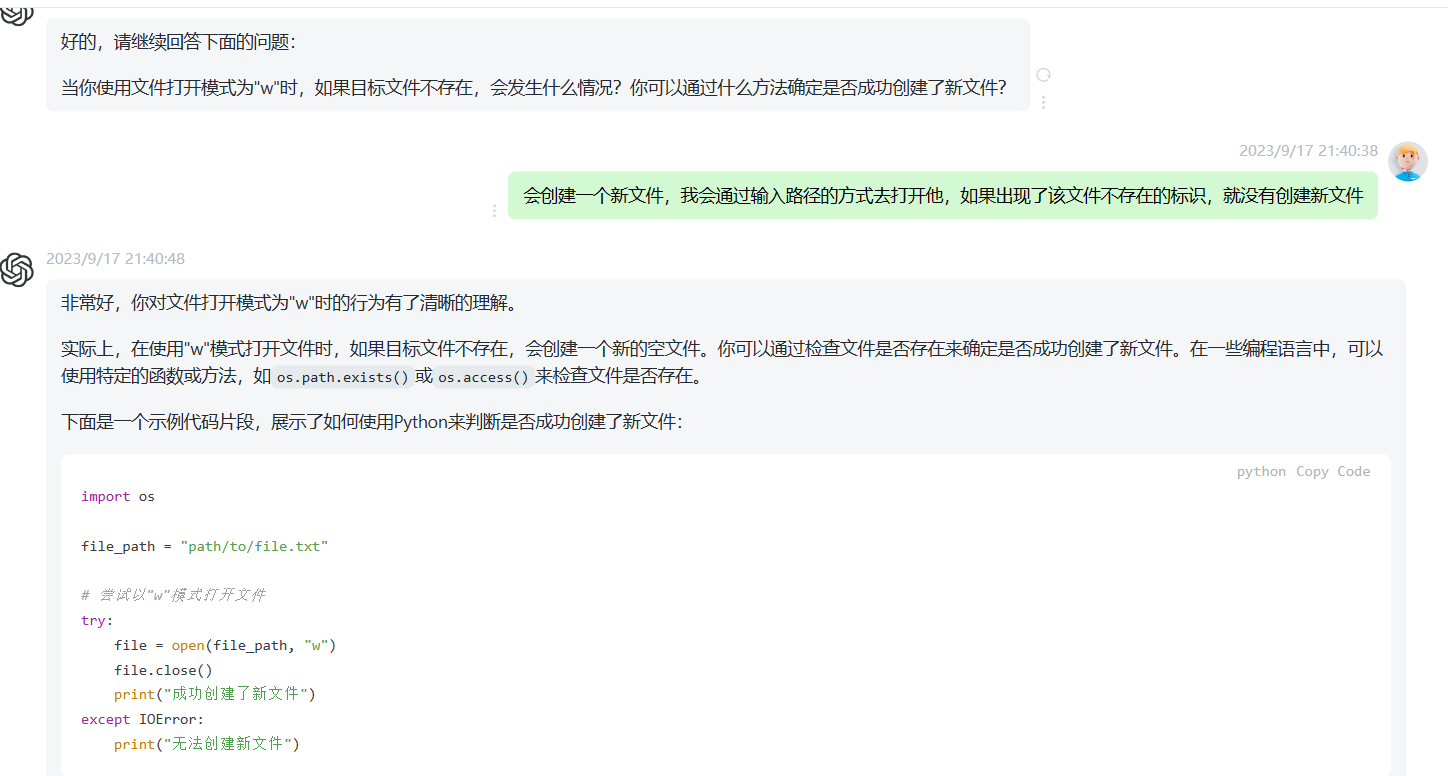
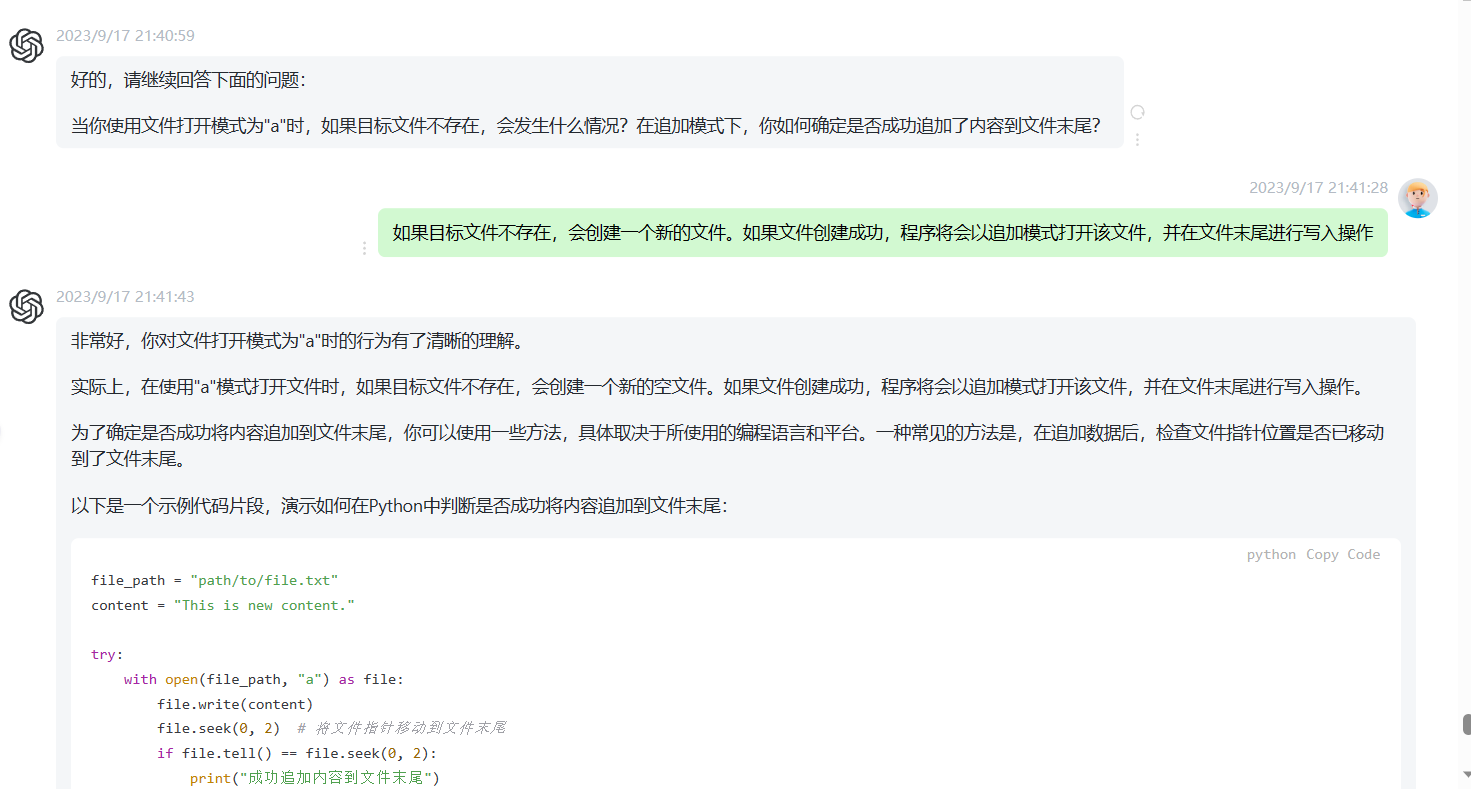
gpt苏格拉底挑战: