关于JNI调用C++中文乱码
2019-09-30 14:31 老九君 阅读(1239) 评论(0) 收藏 举报在JNI调用C实现的本地方法时,我们曾经介绍过直接修改控制台代码页的方式解决中文乱码问题(文章参见:http://wiki.xuetang9.com/?p=5254 ),但是到了C++实现,这个方法又不管用了,折腾了一个下午,终于找到了解决问题的方法,分享如下:
1、相关概念
大家都知道,Java内部采用的是16位Unicode编码来表示字符串,中英文都采用2字节;而JNI内部是使用UTF-8编码来表示字符串,UTF-8编码其实就是Unicode编码的一个变长版本(对应关系参见文章:http://wiki.xuetang9.com/?p=5207 ),一般的ASCII字符占1个字节,中文汉字是3个字节;C/C++使用的是原始数据,ASCII字符就是一个字节,中文一般是GB2312编码,使用两个字节表示一个中文字符。明确了概念,操作就比较清楚了。下面根据字符流的方向来分别说明一下:
1-1:从Java 到 C/C++
这种情况下,Java调用的时候使用的是UTF-16编码的字符串,JVM把这个字符串传给JNI,C/C++得到的输入是jstring,这个时候,可以利用JNI提供的两种函数,一个是GetStringUTFChars,这个函数将得到一个UTF-8编码的字符串;另一个是etStringChars这个将得到UTF-16编码的字符串。无论哪个函数,得到的字符串如果含有中文,都需要进一步转化成GB2312的编码。示意图如下:

1-2:从C/C++ 到 Java
从JNI返回给Java的字符串,C/C++首先就会负责把字符串转换为UTF-8或UTF-16的格式,然后通过NewStringUTF()或NewString()方法将字符串封装成jstring,返回给Java就可以了:
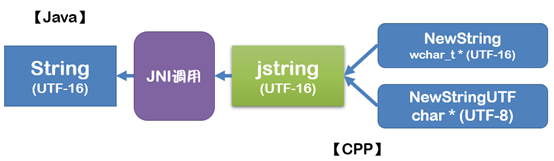
如果字符串中不含中文字符,只是标准ASCII码,使用GetStringUTFChars()/NewStringUTF()方法就可以搞定了,因为这个情况下,UTF-8编码和ASCII编码是一致的,不需要转换。但是如果字符串中存在中文字符,那么就必须在C/C++程序中进行转码操作。这里要说明一下:Linux和Win32都支持wchar,这个实际上就是宽度为16位的Unicode编码UTF-16。所以,如果我们的C/C++程序中完全使用wchar类型,理论上就不需要这种硬转换了。但是实际上,大家在写程序的时候不可能完全用wchar来取代char,所以就目前大多数应用而言,转换仍然是必须的。
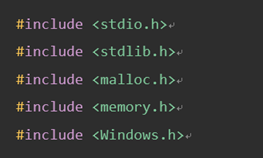
2、转换方法:需要包含的头文件:
使用wide char 类型来做转换:


更多干货笔记关注微信公众号 : 老九学堂

 浙公网安备 33010602011771号
浙公网安备 33010602011771号