LevelDB 学习笔记2:合并
LevelDB 学习笔记2:合并
部分图片来自 RocksDB 文档
LevelDB 中会发生两种不同的合并行为,分别称为 minor compaction 和 major compaction
Minor Compaction
将内存数据库刷到硬盘的过程称为 minor compaction
- 产出的 L0 层的 sstable
- 事实上,LevelDB 不一定会将 minor compaction 产生的 sstable 放到 L0 里
- L0 层的 sstable 可能存在 overlap
- 如果上一次产生的 imm memtable 还没能刷盘,而新的 memtable 已写满,写入线程必须等待到 minor compaction 完成才能继续写入
- 只允许同时存在一个 imm memtable

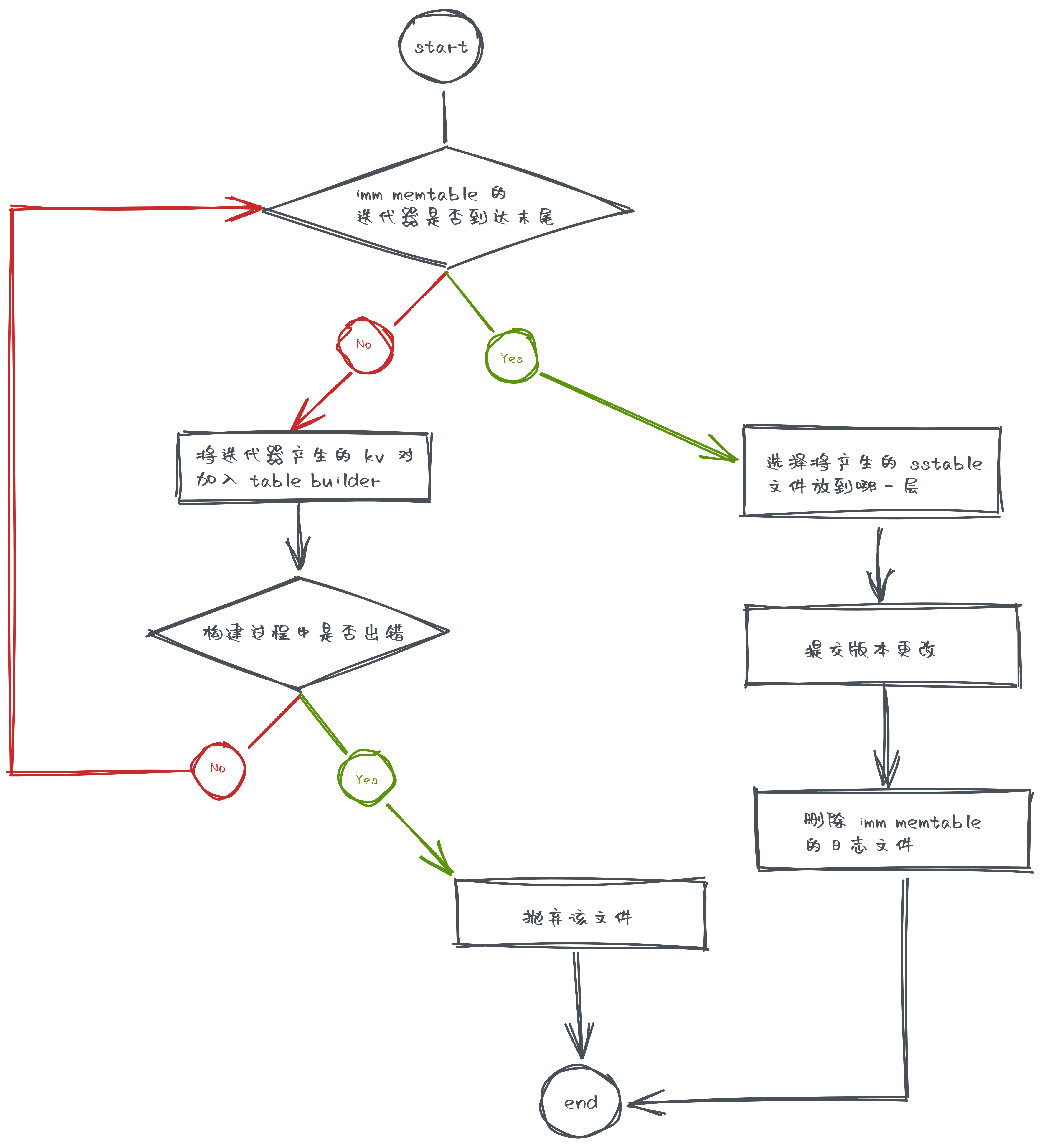
Minor Compaction 的流程
主要流程在 CompactMemTable() 中
- 借助工具类 TableBuilder 构建 sstable 文件
BuildTable()
- 选择将这个产生的 sstable 文件放到哪一层去
PickLevelForMemTableOutput()- 如果某个 sstable 文件和 L0 层没有重叠部分,就可以考虑将它扔到后面的层级里
- 如果满足
- 和 level + 1 层不重叠
- 且不要和 level+ 2 有太多的重叠部分
- 我们就可以将它扔到 level + 1 层去
- 我们希望它能放到第二层去
- 这样可以避免 0 -> 1 层合并的巨大 I/O 开销
- 但我们不希望它直接扔到最后一层,这样可能带来带来的问题是
- 如果某个 key 被重复改写,可能带来磁盘空间的浪费
- 比如你写到 L7 中,然后再改写它时可能又在 L6 里写了一份副本,以此类推,可能每一层里都有这个 key 的副本
- 最高可以放到
config::kMaxMemCompactLevel(默认为 2)层里去
- 提交版本修改
- 增加新的 sstable 文件
- 删除 imm memtable 的日志文件
Major Compaction
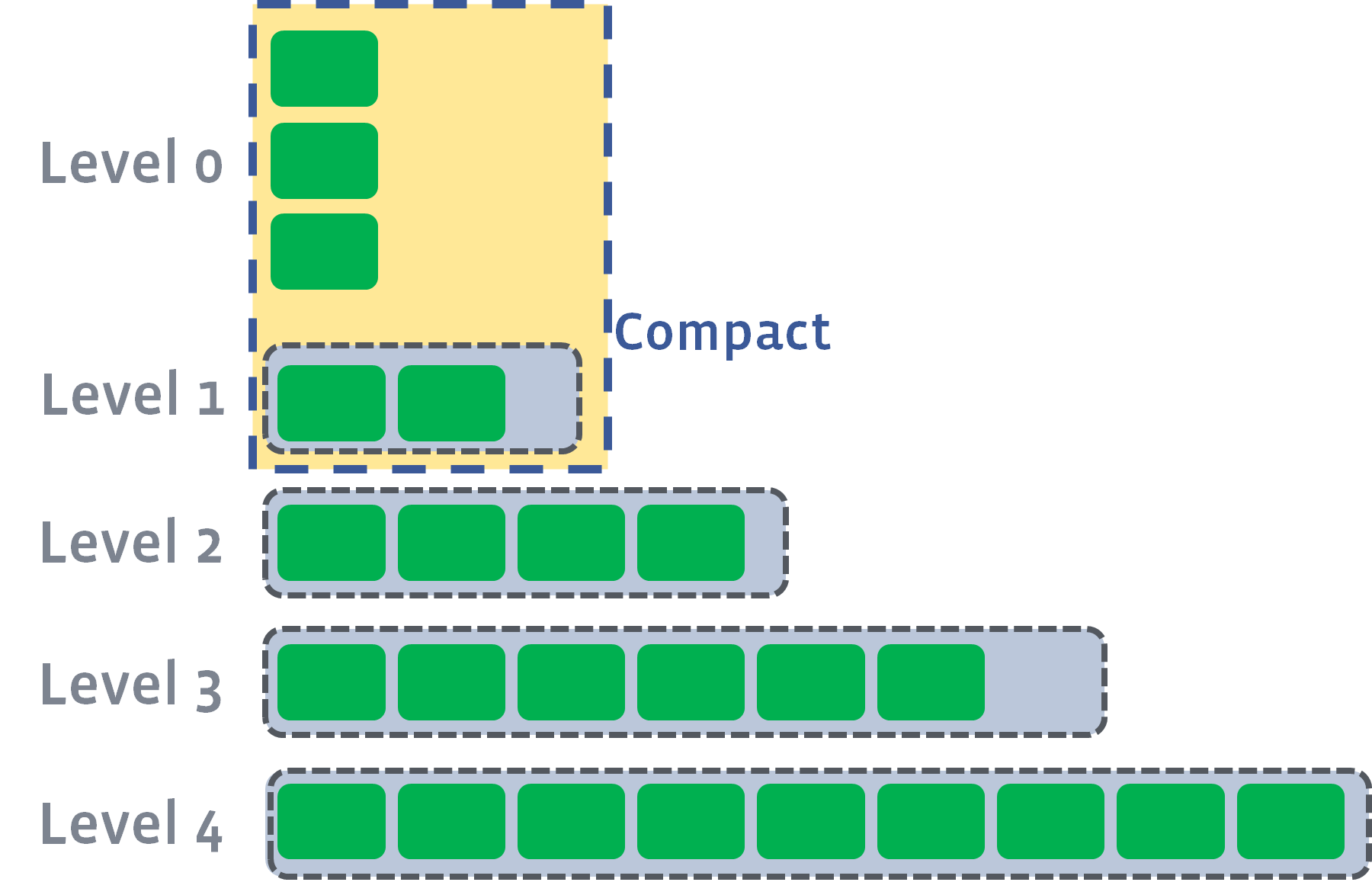
- L0 层的记录有 overlap,搜索的时候可能要遍历所有的 L0 级文件
- 当 L0 层文件数量到达阈值(
kL0_CompactionTrigger,默认值为 4)时,会被合并到 L1 层中去 - 在没有 overlap 的层里搜索时,只需要找到 key 在哪个文件里,然后遍历这个文件就行了
- 所以针对 L0 层的 major compaction 可以提高数据检索效率
- 当 L0 层文件数量到达阈值(
- major compaction 过程会消耗大量时间,为了防止用户写入速度太快,L0 级文件数量不断增长,LevelDB 设置了两个阈值
kL0_SlowdownWritesTrigger,默认值为 8- 放缓写入,每个合并写操作都会被延迟 1ms
kL0_StopWritesTrigger,默认值为 12- 写入暂停,直到后台合并线程工作完成
除了 L0 层以外,其他层级内 sstable 文件的 key 是有序且不重叠的
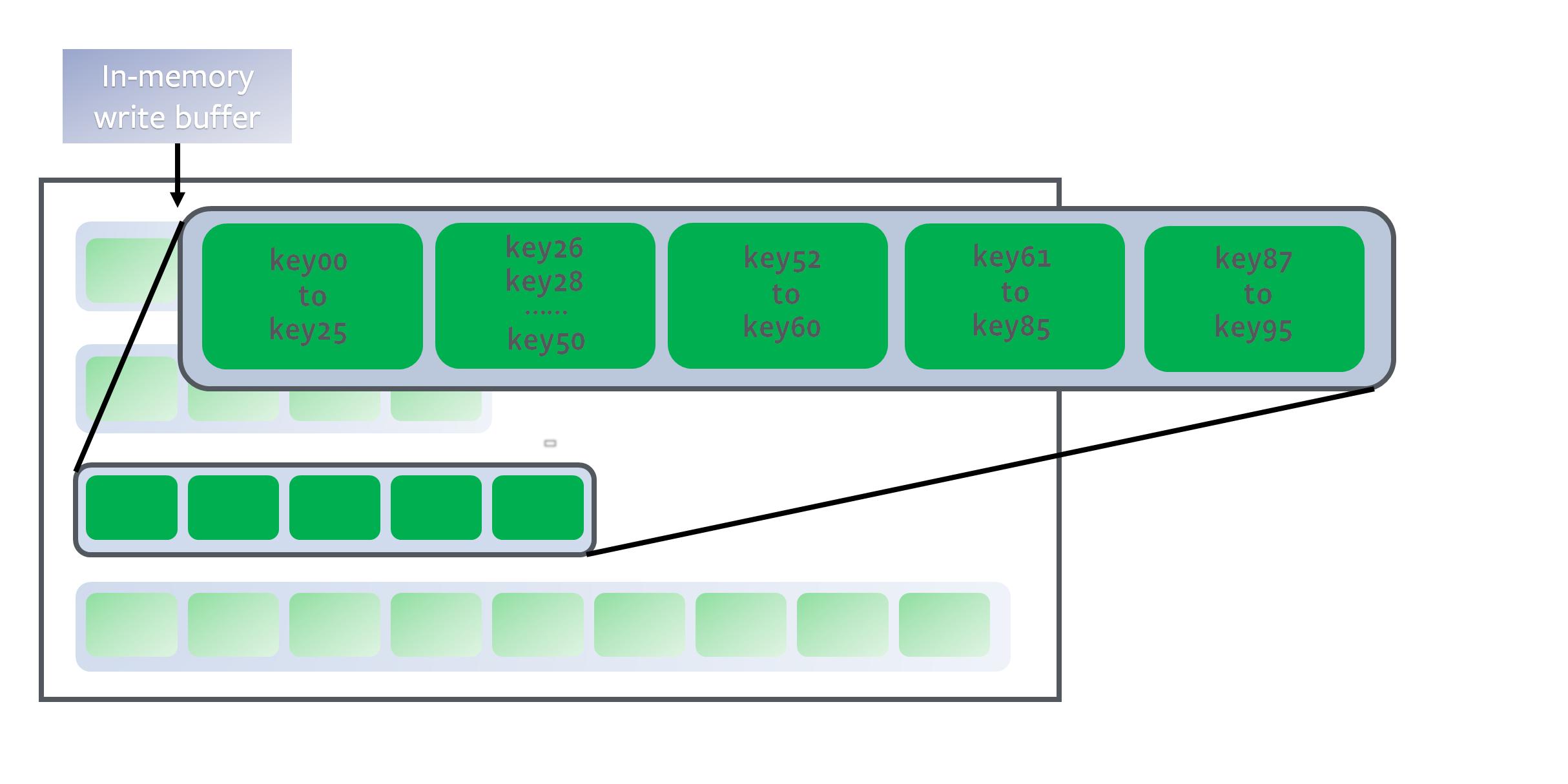
- LevelDB 的写入都是 Append 的,也就是不管是修改还是删除,都是添加新的记录,因此数据库里可能存在 key 相同的多条记录
- major compaction 也起到合并相同 key 的记录、减小空间开销的作用
- 而且如果 L1 层文件积累的太多,L0 层文件做 major compaction 的时候,需要和大量的 L1 层文件做合并,导致 compaction 的 I/O 开销很大
- 所以合并操作也能降低 compaction 的 I/O 开销
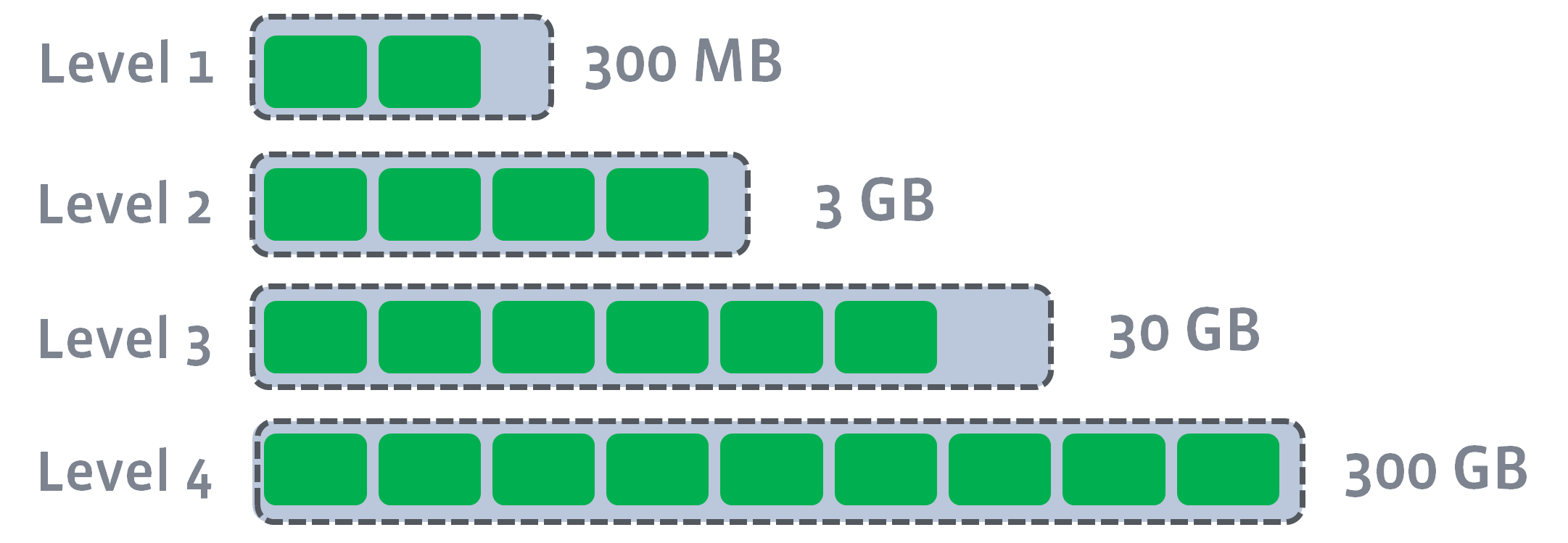
- 当 Li(i > 0)层文件大小超过 \(10^i\) MB 时,也会触发 major compaction,选择至少一个 Li 层文件和 Li+1 层文件合并
- 下面这个图来自 RocksDB 文档,所以阈值跟 LevelDB 不一样
🔑 major compaction 的作用:
- 提高数据检索效率
- 合并相同 key 的记录、减小空间开销的作用
- 降低 compaction 的 I/O 开销
- 可能发生的一种情况是,L0 合并完成后,L1 也触发合并阈值,需要合并,导致递归的合并
- 最坏的情况是每次合并都会引起下一层触发合并
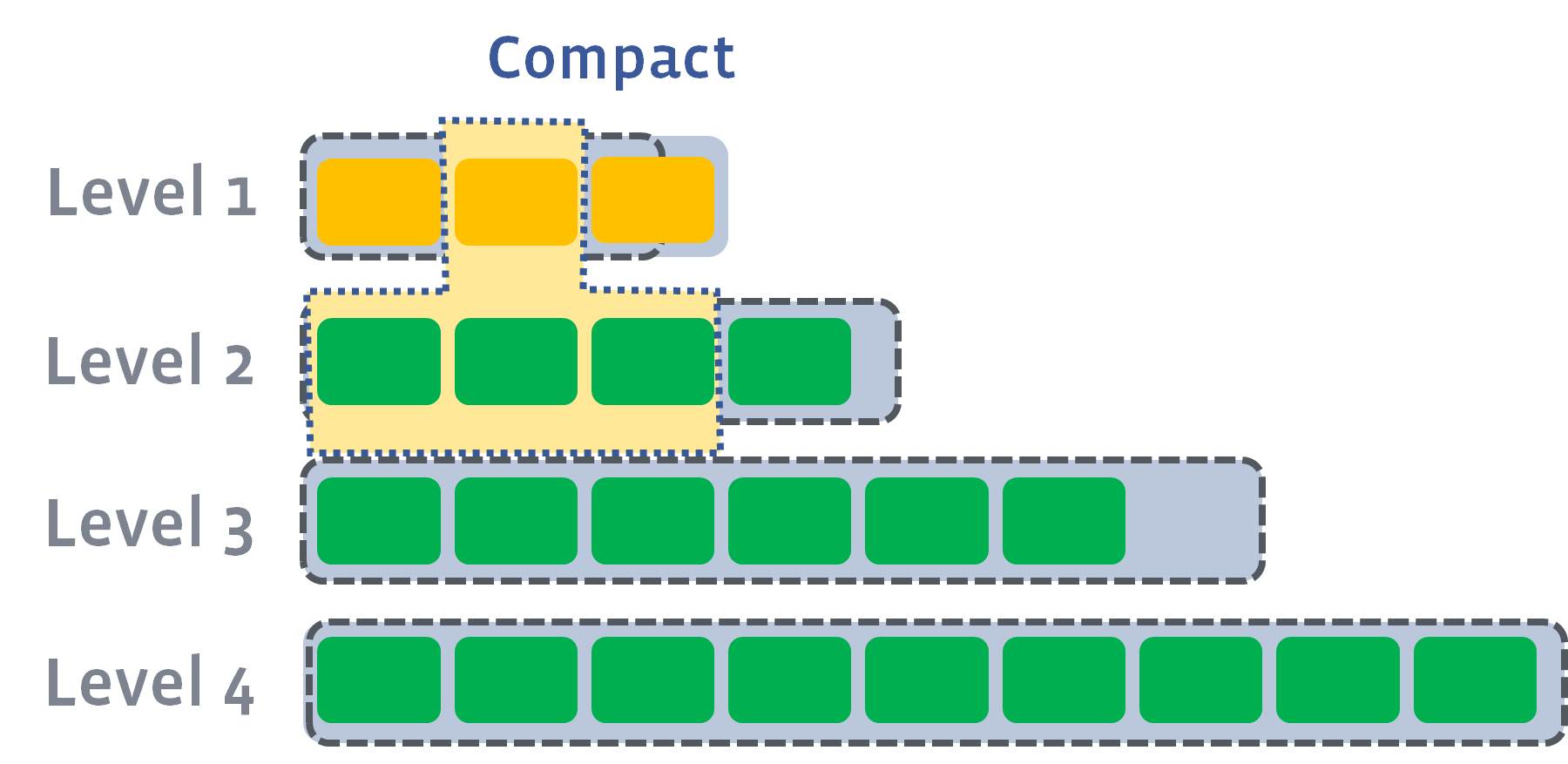
Trivial Move
- LevelDB 做的一种优化是当满足下列条件的情况下
- level 层的文件个数只有一个
- level 层文件与 level+1 层文件没有重叠
- level 层文件与 level+2 层的文件重叠部分的文件大小不超过阈值
- 直接将 level 层的文件移动到 level+1 层去
- 这种优化称为 trivial move
Seek Compaction
如果某个文件上,发生了多次无效检索(搜索某个 key,但没找到),我们希望对该文件做压缩
LevelDB 假设
- 检索耗时 10ms
- 读写 1MB 消耗 10ms(100MB/s)
- 压缩 1MB 文件需要做 25MB 的 I/O
- 从这次层读 1MB 数据
- 从下一层读 10-12MB 数据
- 写 10-12MB 数据到下一层
因此,做 25 次检索的代价等价于对 1MB 的数据做合并,也就是说,一次检索的代价等价于对 40KB 数据做合并
LevelDB 最终的选择比较保守,文件里每有 16KB 数据就允许对该文件做一次无效检索,当允许无效检索的次数耗尽,就会触发合并
文件的元数据里有一个 allowed_seeks 字段,存储的就是该文件剩余无效检索的次数
allowed_seeks的初始化方式
f->allowed_seeks = static_cast<int>((f->file_size / 16384U));
if (f->allowed_seeks < 100) f->allowed_seeks = 100;
- 每次
Get()调用,如果检索了文件,LevelDB 就会做判断,是否检索了一个以上的文件,如果是,就减少这个文件的allowed_seeks - 当文件的
allowed_seeks减少为 0,就会触发 seek compaction
压缩计分
LevelDB 中采取计分机制来决定下一次压缩应该在哪个层内进行
- 每次版本变动都会更新压缩计分
VersionSet::Finalize()- 计算每一层的计分,下次压缩应该在计分最大的层里进行
- 计分最大层和最大计分会被存到当前版本的
compaction_level_和compaction_score_中
- 计分最大层和最大计分会被存到当前版本的
score >= 1说明已经触发了压缩的条件,必须要做压缩
- L0 的计分算法
- L0 级文件数量 / L0 级压缩阈值(
config::kL0_CompactionTrigger,默认为 4)
- L0 级文件数量 / L0 级压缩阈值(
- 其他层的计分算法
- Li 级文件大小总和 / Li 级大小阈值
- 大小阈值为 \(10^i\) MB
为什么 L0 层要特殊处理
- 使用更大的 write buffer 的情况下,这样就不会做太多的 L0->L1 的合并
- write buffer size 是指 memtable 转换为 imm memtable 的大小阈值
options_.write_buffer_size
- 比如设置 write buffer 为 10MB,且 L0 层的大小阈值为 10MB,每做一次 minor compaction 就需要做一次 L0->L1 的合并,开销太大
- write buffer size 是指 memtable 转换为 imm memtable 的大小阈值
- L0 层文件每次读的时候都要做归并(因为 key 是有重叠的),因此我们不希望 L0 层有太多文件
- 如果你设置一个很小的 write buffer,且使用大小阈值,就 L0 就可能堆积大量的文件
Major Compaction 的流程
准备工作
- 判断合并类型
- 如果
compaction_score_ > 1做 size compaction - 如果是有文件
allowed_seeks == 0而引起的合并,做 seek compaction
- 如果
- 选择合并初始文件
- size compaction
- 轮转
- 初始文件的最大 key 要大于该层上次合并时,所有参与合并文件的最大 key
- 每层上次合并的最大 key 记录在 VersionSet 的
compact_pointer_字段中
- 轮转
- seek compaction
- 引起 seek compaction 的那个文件
- 也就是
allowed_seeks归 0 的那个文件
- 也就是
- 引起 seek compaction 的那个文件
- size compaction
- 选择所有参与合并的文件
- 总的来说就是根据文件的重叠部分不断扩大参与合并的文件范围
- 先拓展 Li 的边界
- 再拓展 Li+1 的边界
- 再反过来继续拓展 Li 的边界
- 这次拓展不应该导致 Li+1 的边界扩大(产生更多的重叠文件),否则不做这次拓展
- 具体过程在
PickCompaction()和SetupOtherInputs()中 - 关键函数有两个
GetOverlappingInputs()- 给定一个 key 的范围,选择 Li 中所有和该范围有重叠的 sstable 文件加入集合
AddBoundaryInputs()- 假设有两个 block
b1=(l1, u1)和b2=(l2, u2) - 其中 b1 的上界和 b2 的下界的 user_key 相等
- 也就是说这两个块是相邻的
- 如果只是合并 b1,也就是将它移动到下一层去
- 那么后续查这条 user_key 时,从 b2 中查到后,就不会再去下一层查找
- 如果 b2 中的数据比 b1 中的旧,那么这样查到的数据就是错误的
- 因此 b1 和 b2 必须同时被合并
- 假设有两个 block
- 总的来说就是根据文件的重叠部分不断扩大参与合并的文件范围

拓展边界的示例:
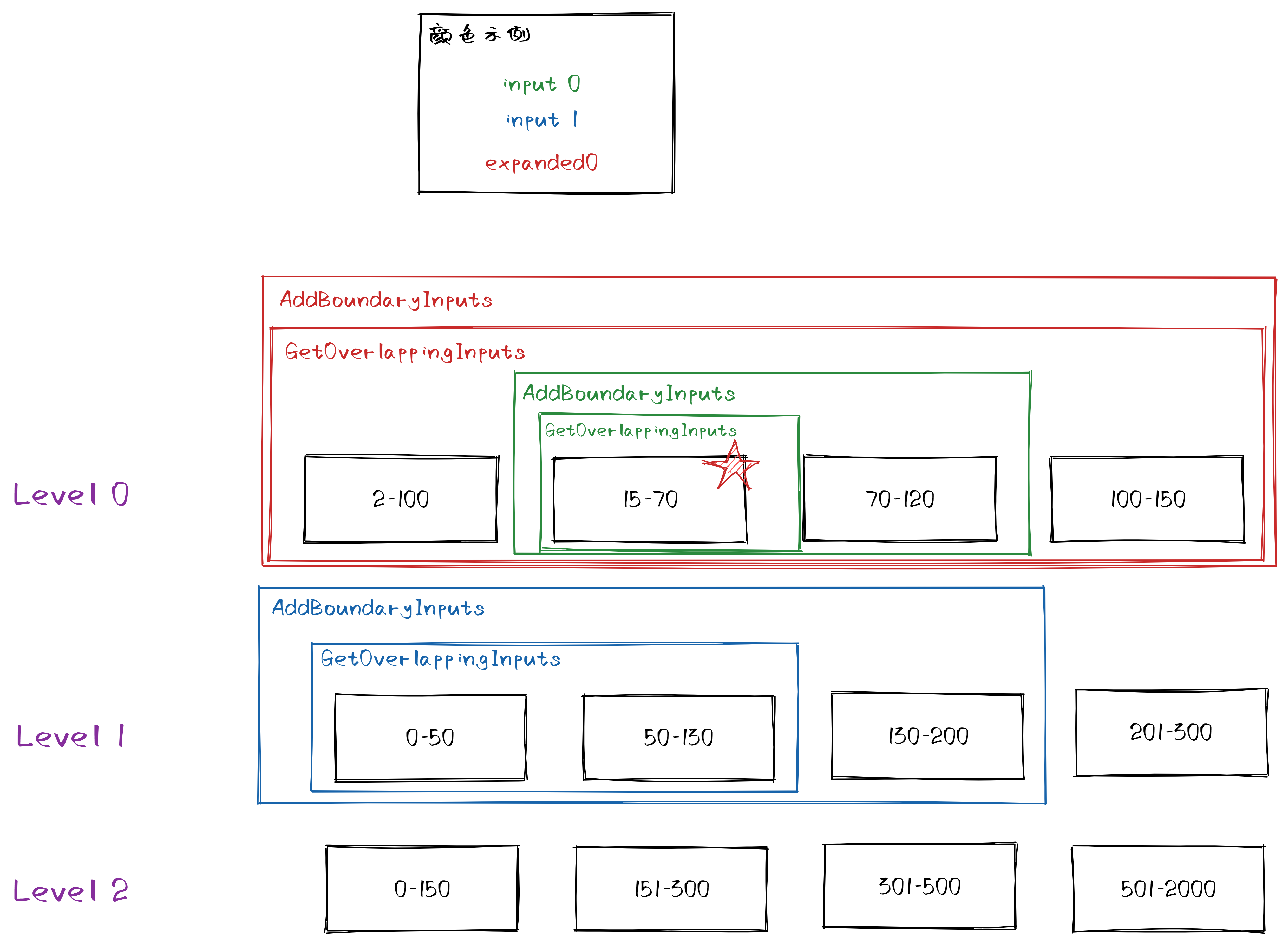
执行合并
- 判断是否满足 [[#Trivial Move]] 的条件
- 满足就做 trivial move,不再执行后续流程
- 开始执行合并
- 合并主要流程在
DoCompactionWork()中 - 用合并的输入文件构造 MergingIterator
- 遍历 MergingIterator
- 这个过程就是对输入文件做归并排序的过程
- 如果遍历过程中发现有 imm memtable 文件存在,就会转而先做 minor compaction
- 并且会唤醒在
MakeRoomForWrite()中等待 minor compaction 完成的线程
- 并且会唤醒在
- 借助工具类 TableBuilder 构建 sstable 文件
- 将遍历迭代器产生的 kv 对加入 builder
- 如果当前文件大小超过阈值或和 level+2 层有太多的重叠部分
- 完成对该文件的写入,并打开新的 TableBuilder
- 合并主要流程在
- 提交版本更改
- 调用
RemoveObsoleteFiles()删除不再需要的文件
抛弃无用的数据项
- 满足以下条件的数据项会被抛弃,不会加入到合并后的文件里
- 数据项的类型是删除
- 这个数据项比当前最老的 snapshot 还要老
- level + 2 以上的层都不包含这个 user_key
- 不然你把这项在合并阶段删掉了,用户读的时候就会读到错误的数据
- 比这些数据项更老的所有相同 user_key 的数据项都会被抛弃
本文来自博客园,作者:路过的摸鱼侠,转载请注明原文链接:https://www.cnblogs.com/ljx-null/p/16154773.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号