Paxos 学习笔记2 - Multi-Paxos
Paxos 学习笔记2 - Multi-Paxos
图片来自 John Ousterhout 的 Raft user study 系列课程
关于 Basic Paxos 可以看本人的这篇文章
🔑 Multi-Paxos 论文里对很多问题并没有描述清楚,所以实践里往往用的是修改过的 Multi-Paxos 协议或 Raft 协议
用 basic paxos 实现 replicated log 的简单思路
实现 replicated log 的最简单思路就是对每个日志项运行一个 basic paxos
- 在 basic paxos 请求的参数里加一个 index 参数
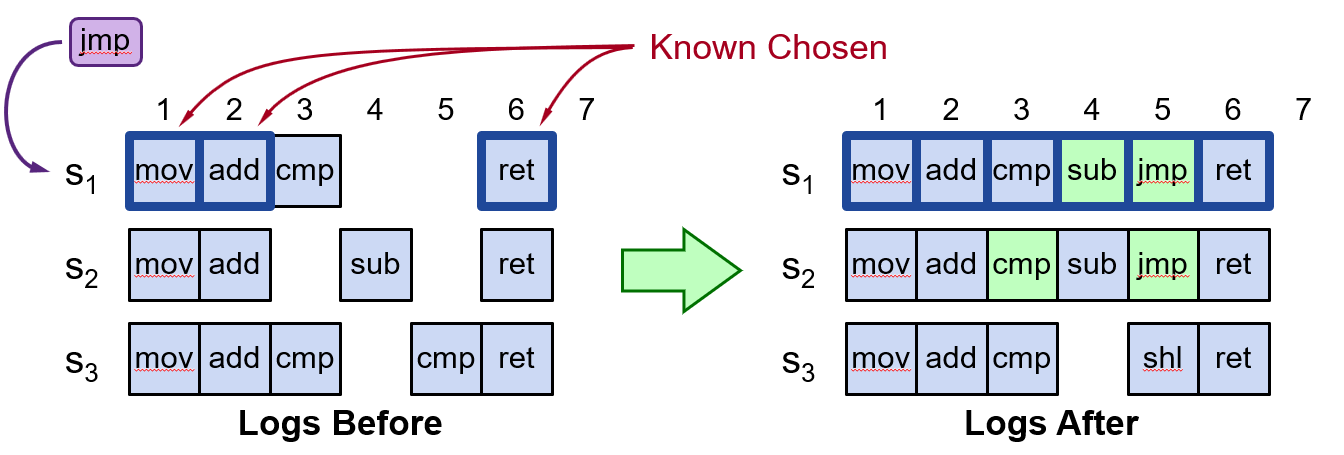
当提议者收到客户端发来的一条指令,他会尝试使用下一个没有被选中的日志项位置
比如 S1 从客户端收到指令 jmp 后
- 会先尝试日志项 3,发现已经写入了 cmp(但还没有被选中),于是走 basic paxos 的两阶段协议提议在日志项 3 中放置 cmp
- 等到 cmp 被选中后,发现日志项 4 是空的,于是提议将在日志项 4 中放置 jmp ,最终达成共识的不是 jmp(提议之间产生了冲突),于是 S1 就会去尝试下一个日志项,直到给 jmp 找到一个可以达成共识的位置
在这种方案中服务器可以并发地处理多个客户端请求,只要为他们选择不同的日志项,并独立地执行 basic paxos 流程即可
如果一条指令和它之前的全部指令都已经被选中了,那么就可以交给状态机去执行了
可能的性能优化
- 使用领导人来避免提议者之间的冲突
- basic paxos 的活锁问题会在高负载的 replicated log 场景下变得更加严峻
- 消除多余的 Prepare 请求
尚未解决的问题
- 确保完全复制
- basic paxos 中共识的结果只有提议者自己知道,但 replicated log 场景中每个服务器都应该拥有一份已选中日志的拷贝
- 客户端协议
- 客户端如何与 paxos 集群交互
- 配置改变
- 服务器加入或离开时,算法应该做怎样的改变
领导人选举
Lamport 提出的选举方法
- 让 ID 最大的服务器作为领导人
- 所有服务器每隔 T ms 就发其他所有服务器发送心跳报文
- 如果一个服务器在过去的 2T ms 里都没有收到其他比他 ID 更大的服务器发来的心跳报文,他就作为领导人开始工作
- 接受客户端请求
- 同时作为提议者和接受者
- 如果服务器不是领导人
- 拒绝客户端请求
- 只作为接受者
🔑 Chubby 中是通过运行 basic paxos 投票选举选出领导人,在运行过程中,主节点会通过不断续租的方式来延长租期(Lease)
消除 Prepare 阶段
回忆 Basic Paxos 中 Prepare 阶段的用途
- 阻止那些更老的还未完成的提议被选中
- 看看有没有已经被选中的值,如果有,提议者的提议就应该使用这个值
消除 Prepare 的设计:
- Prepare 请求中对整个日志使用一个提议号,而不是针对每个日志项用一个独立的提议号
- 接受者回复 Prepare 请求时
- 回复当前日志项的最大已接收提议
- 即
acceptedProposal[index]和acceptedValue[index]
- 即
- 查看 index 之后的所有日志项,如果没有已接受的日志项,就在回复里设置 noMoreAccepted
- 回复当前日志项的最大已接收提议
noMoreAccepted:
- 如果提议者收到了某个接受者发送的 noMoreAccepted
- 就可以省略发给该接受者的任何 Prepare 报文
- 直到发给该接受者的某个 Accept 报文被拒绝
- 如果提议者收到了多数接受者发送的 noMoreAccepted
- 就不需要发送任何 Prepare 报文了,直接发送 Accept 报文即可
🔑 减少算法中非必要的协商步骤,优化系统性能
完全拷贝
使用上面的方法来实现 replicated log,当提议者发现某个日志项被选中后,并没有一种机制能保证该日志项能拷贝给其他节点,由于我们使用了领导人,因此接受者是没有任何主动的手段去获得已选中日志项的内容的,因此我们引入了下面的机制来保证日志项被完全地拷贝
机制 1
领导人收到多数 Accept 回复后
- 在后台继续重试发送 Accept 报文,直到所有接受者都回复
- 不能保证完全拷贝,比如重试过程中领导人宕机了,或者服务器故障期间达成共识的日志项,就没法以这种方式同步过来
机制 2
所有节点都必须将已经被选中的日志项记录下来
- 通过将
acceptedProposal[i]设置为 ∞- 表示该日志项已经被选中了
- 因为只有提议编号大于等于 acceptedProposal 的情况下,该日志项才会被覆盖,如果是无穷大,该日志项就再也不能被覆盖了
- 维护一个 firstUnchosenIndex
- 表示最早的没有被选中的日志项下标
- 即第一个
acceptedProposal[i] != ∞的日志项
机制 3
领导人主动告知接受者哪些日志项被选中了
- 在 Accept 请求中包含 firstUnchosenIndex,也就是告诉接受者小于 firstUnchosenIndex 的日志项都已经被选中了
- 如果某个日志项 i 满足
i < request.firstUnchosenIndexacceptedProposal[i] == request.proposal- 提议号相同说明,日志项中的内容和 Accept 请求来自同一个提议者,firstUnchosenIndex 又告诉我们这条日志项已经被选中了,说明这条日志项里记录的正好就是被选中的日志内容
- 将满足上述条件的所有日志项标记为已选中
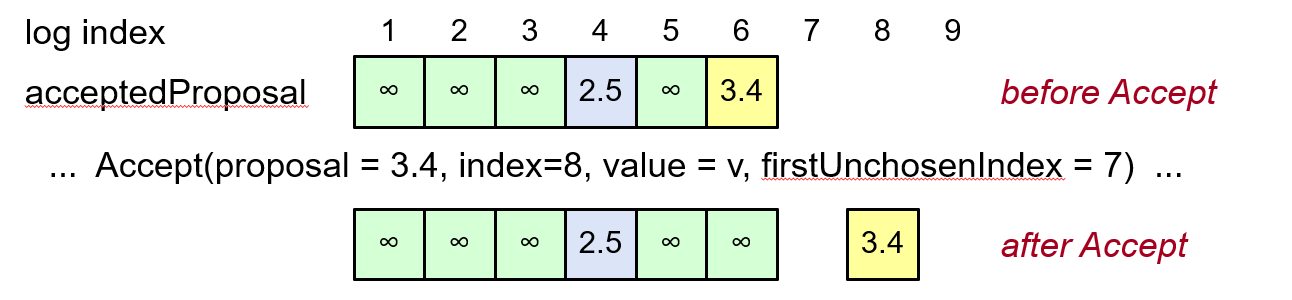
上图中,日志项 6 的下标小于 firstUnchosenIndex,且它的 acceptedProposal 等于请求的提议编号,因此可以将它标记为已选中
机制 4
通过上面的三种机制,并不能解决日志拷贝中的全部问题,比如上图的日志项 4,他的 acceptedProposal 和 Accept 请求的提议号是不同的,说明这条记录来自于其他提议者或来自于同一个提议者在较老的提议轮中提出的提议,这种情况下我们是无法判断这条日志项中的内容正确与否的,这种情况往往发生在领导人切换时
为了处理上一任领导人留下来的日志项
- 接受者在 Accept 回复中带上他的 firstUnchosenIndex
- 如果领导人的 firstUnchosenIndex 大于回复里的 firstUnchosenIndex,说明存在这样的不同步的日志项,这时,领导人会发送 Success RPC(在后台)
Success RPC 的格式为 Success (index, v),也就是说在 index 的位置上,有已经被选中的提议值 v,收到 Success 报文后,接受者应该
acceptedValue[index] = vacceptedProposal[index] = ∞- 回复给提议者新的 firstUnchosenIndex
- 如果需要,领导人会继续发送 Success RPC,直到和接受者达成同步
通常情况下,只有领导人切换时才需要执行这一步
客户端协议
客户端与 Paxos 集群交互的方式
- 如果客户端不知道领导人是哪台机器
- 随便找一台服务器发送请求
- 如果接受请求的服务器不是领导人,他就会将消息转发给领导人
- 只有请求被记录到日志中,并提交给领导人的状态机执行结束后,领导人才会给客户端回复
- 如果请求超时(比如领导人崩溃的情况下)
- 客户端将请求发送给其他服务器
- 请求最终会被转发给新的领导人
- 新的领导人重试这条请求
这样做的问题在于如果领导人崩溃前,已经执行了一次客户端请求,只不过还没来得及回复给客户端,这样同一条客户端请求就被执行了两次
解决方法是客户端在请求上带上唯一 id,服务器记录已经执行过了哪些指令,状态机执行新的指令前先检查是否已经执行过了,如果执行过了就直接将结果回复给客户端
只要客户端不崩溃,上述方法就可以保证 exactly-once 语义
更改配置
分布式系统中系统配置指的是
- 每台服务器的 ID、地址
- 多少服务器能构成 quorum 中的多数
共识机制必须支持对系统配置的更改,比如移除掉故障的机器
安全性要求
配置更改期间,不能出现集群中不同的部分针对某个日志项选中了不同的值
- 比如图中前两个节点还在使用旧的配置,他们认为自己构成了多数节点,选择了 v1
- 而后三个节点已经切换到了新的配置,他们也认为自己构成了多数节点,选择了另一个值 v2
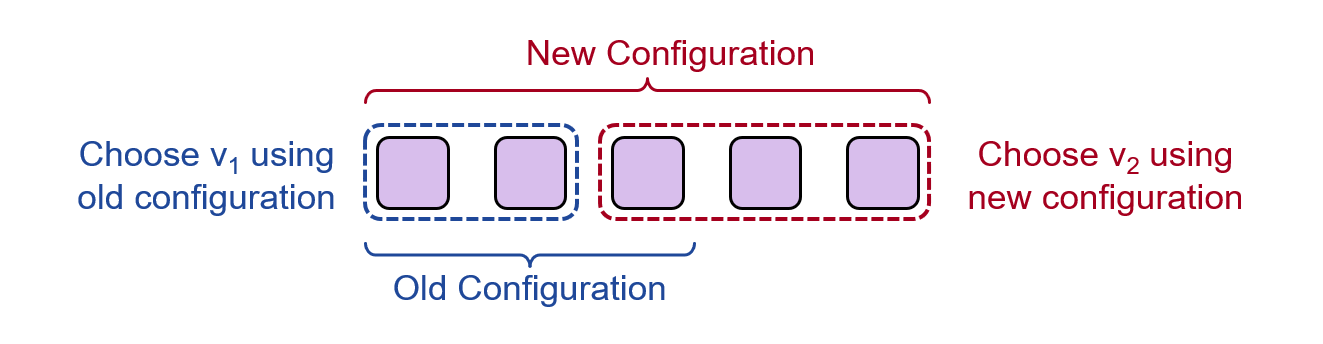
Paxos中配置更改的方式
使用日志项来管理配置的更改
- 配置也被存储为日志项
- 也像其他日志项一样在服务器间拷贝
- 日志项生效有延迟,放到日志项 i 中的配置,要在选择日志项 i+α 时才能生效
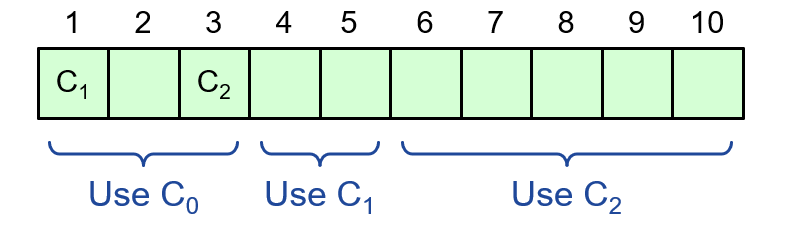
- α 限制了 paxos 的并发度,只有选中了日志项 i 后,我们才可以开始选择日志项 i+α
- 如果想要配置更改快点生效,可以发出多条空指令
本文来自博客园,作者:路过的摸鱼侠,转载请注明原文链接:https://www.cnblogs.com/ljx-null/p/15940785.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号