Linux 内核 RCU机制介绍
Linux 内核 RCU机制介绍
内容基本上是这篇文章的翻译
RCU 是一种内核同步机制,在2002年10月加入到 Linux 内核中
RCU 与读写自旋锁和顺序锁不同,后两者只允许多个读者的并发,RCU 允许单个写者和多个读者的并发
那有人会问了,顺序锁中不也是读者和写者同时在运行嘛?RCU 和顺序锁的区别在于
- 虽然顺序锁也是读者和写者并发执行,但
read_seqretry()原语会强制读者重试,也就是说当两者并发执行的时候,事实上读者是没有完成任何工作的 - 但 RCU 能做到即使有并发的写者存在,读者也能做有用的工作
RCU 由三个基本机制组成
- (插入时使用)发布-订阅机制
- (删除时使用)等待已存在的读者完成
- (读者读取时使用)维持最近更新对象的多个版本
发布-订阅机制
RCU 的一个关键性质就是它允许你安全的访问数据,即使这时数据正在被修改,而这种性质就是通过发布-订阅机制保证的
下面这段代码在分配并初始化一个结构体后将它赋值给指针 gp,问题在于没法保证编译器或 CPU 不会重排序代码,让 gp = p 在三条赋值语句之前执行,这样并发的读者可能会看到未初始化的值,需要使用内存屏障来保证这种情况不会发生
struct foo {
int a;
int b;
int c;
};
struct foo *gp = NULL;
/* . . . */
p = kmalloc(sizeof(*p), GFP_KERNEL);
p->a = 1;
p->b = 2;
p->c = 3;
gp = p;
但众所周知,内存屏障非常难用,RCU 将它封装为一个原语 rcu_assign_pointer(),具有发布语义,因此可以将最后四行改为
p->a = 1;
p->b = 2;
p->c = 3;
rcu_assign_pointer(gp, p);
只是写者强制执行顺序的,考虑这段读者的代码
p = gp;
if (p != NULL) {
do_something_with(p->a, p->b, p->c);
}
尽管这段代码看起来不会被重排序,但在某些上下文里编译器会去先取 p->a 、 p->b 、 p->c 的值,再取 p 的值,因此要使用 rcu_dereference() 原语来阻止这种激进的优化
rcu_read_lock();
p = rcu_dereference(gp);
if (p != NULL) {
do_something_with(p->a, p->b, p->c);
}
rcu_read_unlock();
rcu_dereference 可以被看作是订阅操作,保证后续的解引用操作能看到发生在发布操作之前的初始化值
rcu_read_lock() 和 rcu_read_unlock() 是必须要有的,它们定义了 RCU 读端临界区(RCU read-side critical sections)范围,事实上,它们只是禁止和重启内核抢占,在没有配置 CONFIG_PREEMPT 的内核里甚至什么都不做
操作 RCU 保护的链表
虽然可以用 rcu_assign_pointer() 和 rcu_dereference() 来构造 RCU 保护的数据结构,但大部分情况下都应该使用封装好的高层 API,Linux 中有两种链表:循环链表 struct list_head 和线性链表 struct hlist_head/struct hlist_node
struct foo {
struct list_head list;
int a;
int b;
int c;
};
LIST_HEAD(head);
/* . . . */
p = kmalloc(sizeof(*p), GFP_KERNEL);
p->a = 1;
p->b = 2;
p->c = 3;
list_add_rcu(&p->list, &head);
list_add_rcu() 必须由某种并发机制保护(通常是使用某种锁),以防止多个 list_add() 操作并发执行,但 list_add() 是可以和 RCU 读者并发执行的
订阅一个由 RCU 保护的链表的代码是比较直接的,所有运行 Linux 的体系结构中,指针的读写都是原子的,并且 list_for_each_entry_rcu() 只会向前移动,因此它要么能看到插入的节点,要么看不到插入的节点,不管那种情况,读者看到的链表都是结构良好的(well-formed)
rcu_read_lock();
list_for_each_entry_rcu(p, head, list) {
do_something_with(p->a, p->b, p->c);
}
rcu_read_unlock();
操作 RCU 保护的 hlist 的代码也是类似的,同样的 hlist_add_head_rcu() 也需要同步机制来保护
struct foo {
struct hlist_node *list;
int a;
int b;
int c;
};
HLIST_HEAD(head);
/* . . . */
p = kmalloc(sizeof(*p), GFP_KERNEL);
p->a = 1;
p->b = 2;
p->c = 3;
hlist_add_head_rcu(&p->list, &head);
rcu_read_lock();
hlist_for_each_entry_rcu(p, head, list) {
do_something_with(p->a, p->b, p->c);
}
rcu_read_unlock();
RCU API
- 指针
- 发布
rcu_assign_pointer()
- 撤销
rcu_assign_pointer(..., NULL)
- 订阅
rcu_dereference()
- 发布
- list
- 发布
list_add_rcu()list_add_tail_rcu()list_replace_rcu()
- 撤销
list_del_rcu()
- 订阅
list_for_each_entry_rcu()
- 发布
- hlist
- 发布
hlist_add_after_rcu()hlist_add_before_rcu()hlist_add_head_rcu()hlist_replace_rcu()
- 撤销
hlist_del_rcu()
- 订阅
hlist_for_each_entry_rcu()
- 发布
替换和删除的 API 让问题更复杂了,何时释放这些被替换或删除的元素是安全的,换句话说,我们怎么才能知道所有读者都释放了对这些元素的引用,这就需要 RCU 的第二个机制
等待已存在的读者完成
RCU 是一种等待事情发生的机制,当然内核里提供了许多其他的方法来等待某件事发生,比如引用计数、读写锁、事件等等,RCU 的一大优势就是它的拓展性极好,你可以同时等待许多事件,而不用担心性能下降、死锁或内存泄漏等问题
RCU 中等待的事件叫 RCU 读端临界区,由 rcu_read_lock() 开始,到 rcu_read_unlock() 结束,临界区可以嵌套,可以容纳任何代码,只要这些代码不要阻塞或睡眠
如下图所示,RCU 是一种等待已存在的 RCU 读端临界区完成的方式
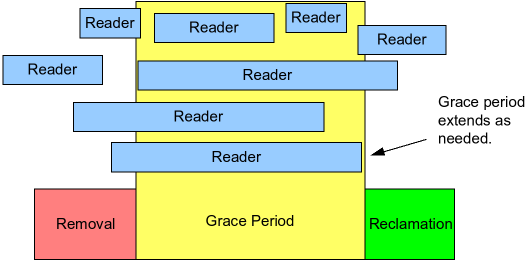
算法使用 RCU 等待读者的基本形式:
- Removal 阶段,做出改动,比如更换链表中的一个元素
- 等待所有已存在的读端临界区完全完成(比如使用
synchronize_rcu()原语)- 后续的 RCU 读端临界区是没法访问到这个刚刚被移除的元素的
- 这段等待的时间叫宽限期(Grace Period)
- 注意,Grace Period 期间才进入的读端临界区是可以超过宽限期的,因为我们并不会去等待这些读者完成
- Reclamation 阶段,做清理工作,比如释放掉那个被置换的元素
struct foo {
struct list_head list;
int a;
int b;
int c;
};
LIST_HEAD(head);
/* . . . */
p = search(head, key);
if (p == NULL) {
/* Take appropriate action, unlock, and return. */
}
q = kmalloc(sizeof(*p), GFP_KERNEL);
*q = *p;
q->b = 2;
q->c = 3;
list_replace_rcu(&p->list, &q->list);
synchronize_rcu();
kfree(p);
当所有的已存在的 RCU 读端临界区都完成后,synchronize_rcu() 就会返回
之前我们说过,用来标识读端临界区范围的 rcu_read_lock() 和 rcu_read_unlock() 在没有配置 CONFIG_PREEMPT 的情况下甚至不会产生任何代码,那么 RCU 该怎么判断读者是否已经离开临界区了呢?
这里就有一个 trick,那就是读端临界区是不允许阻塞和休眠的,因此,当某个 CPU 执行上下文切换的时候,就保证之前的读端临界区已经完成了。这也就意味着,只要所有的 CPU 都做了一次上下文切换,之前的所有读端临界区肯定都完成了,synchronize_rcu() 也就可以返回了
从概念上来讲,我们可以认为 synchronize_rcu() 等价于
for_each_online_cpu(cpu)
run_on(cpu);
run_on() 将当前线程切换到指定 CPU 上去,该函数将导致这个 CPU 发生一次上下文切换,for_each_online_cpu() 遍历每个 CPU,因此循环结束后每个 CPU 都至少进行了一次上下文切换,这个方法适用于在读端临界区中禁用抢占的内核,不适用于配置了 CONFIG_PREEMPT_RT 选项的内核
当然 Linux 内核中真实的实现要比这复杂的多,因为它要处理中断、NMI、CPU 热插拔等复杂的情况,还要保持良好的性能和可拓展性
异步等待
除了使用 synchronize_rcu() 执行同步的等待,还可以调用基于回调的 call_rcu()
struct callback_head {
struct callback_head *next;
void (*func)(struct callback_head *head);
} __attribute__((aligned(sizeof(void *))));
#define rcu_head callback_head
typedef void (*rcu_callback_t)(struct rcu_head *head);
void call_rcu(struct rcu_head *head, rcu_callback_t func);
调用 call_rcu() 注册了回调函数后,就可以去做其他事情了,由于可能多次注册回调,因此需要将每次注册的回调函数用 next 指针串起来
head 是传递给回调函数 func 的参数,那回调函数该如何拿到需要被释放的结构体指针呢?以一个回调函数 kvfree_rcu 为例
static void kvfree_rcu(struct rcu_head *head)
{
struct list_lru_memcg *mlru;
mlru = container_of(head, struct list_lru_memcg, rcu);
kvfree(mlru);
}
可以看到 rcu_head 的用法是类似于 list_head,通过嵌入到某个结构体中,然后用 container_of 来获取该结构体的地址
调用 rcu_barrier() 等待所有 RCU 回调执行完毕
维持最近更新对象的多个版本
这章讲述 RCU 如何通过维持对象的多个版本,以保证读者能够不做任何同步地去访问正在被更新地对象,我们将用两个例子来做说明
例子1:在删除期间维持多版本
p = search(head, key);
if (p != NULL) {
list_del_rcu(&p->list);
synchronize_rcu();
kfree(p);
}
下面的示意图中,红色边框表示读者仍可能持有它们的引用,为了清晰起见,我们省略掉了 prev 指针

在 list_del_rcu() 完成后,元素 5,6,7 已经从链表中移除了,如上图的状态 2,由于读者不直接的与写者做同步,可能还有读者会访问到该元素,因此事实上现在是有两个版本的链表,一个有元素 5,6,7,而另一个没有
当 synchronize_rcu() 执行完毕后,说明所有已存在的读端临界区都完成了,因此没有读者再持有元素 5,6,7 的引用了,即上图的状态 3,当前状态下只存在单一版本的链表,此时元素 5,6,7 可以被安全的释放了
如果将这个删除的整个过程用锁互斥,那么最多只可能同时存在两个版本的链表,如果我们减小互斥的临界区,比如
spin_lock(&mylock);
p = search(head, key);
if (p == NULL)
spin_unlock(&mylock);
else {
list_del_rcu(&p->list);
spin_unlock(&mylock);
synchronize_rcu();
kfree(p);
}
能支持更多同时存在的链表版本,这意味着同时有多个写者在 synchronize_rcu() 上等待,但要注意,RCU 并不适合频繁更新的数据结构
例子2:在替换期间维持多版本
q = kmalloc(sizeof(*p), GFP_KERNEL);
*q = *p;
q->b = 2;
q->c = 3;
list_replace_rcu(&p->list, &q->list);
synchronize_rcu();
kfree(p);

- 先分配新节点并拷贝原节点的值
- 在新结点上做修改
list_replace_rcu()执行替换操作,然后后续的读者就能看到新结点了,然而仍有已存在的读者可能访问到老节点synchronize_rcu()返回后,所有持有老节点引用的读者就都退出临界区了,此时可以释放该节点
本文来自博客园,作者:路过的摸鱼侠,转载请注明原文链接:https://www.cnblogs.com/ljx-null/p/15933962.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号