Libco 源码分析
Libco 源码分析
设计目标
libco 的设计目标是对现有同步代码做异步化改造,但完全重写为异步的代码基本需要将所有代码重写,工作量太大
libco 的做法是采用 Linux 下的 hook 机制,将 glibc 的阻塞系统调用捕获,将它的底层逻辑改为异步的,以实现代码的无缝迁移
协程设计
什么是协程(Coroutine)
计算机科学中例程(routine)被定义为一个操作序列,例程的执行是有父子关系的,子例程执行结束后父例程才能执行
可以认为协程是加强版的例程,协程允许在执行过程中显式地挂起,并保存其执行状态,在稍后恢复执行
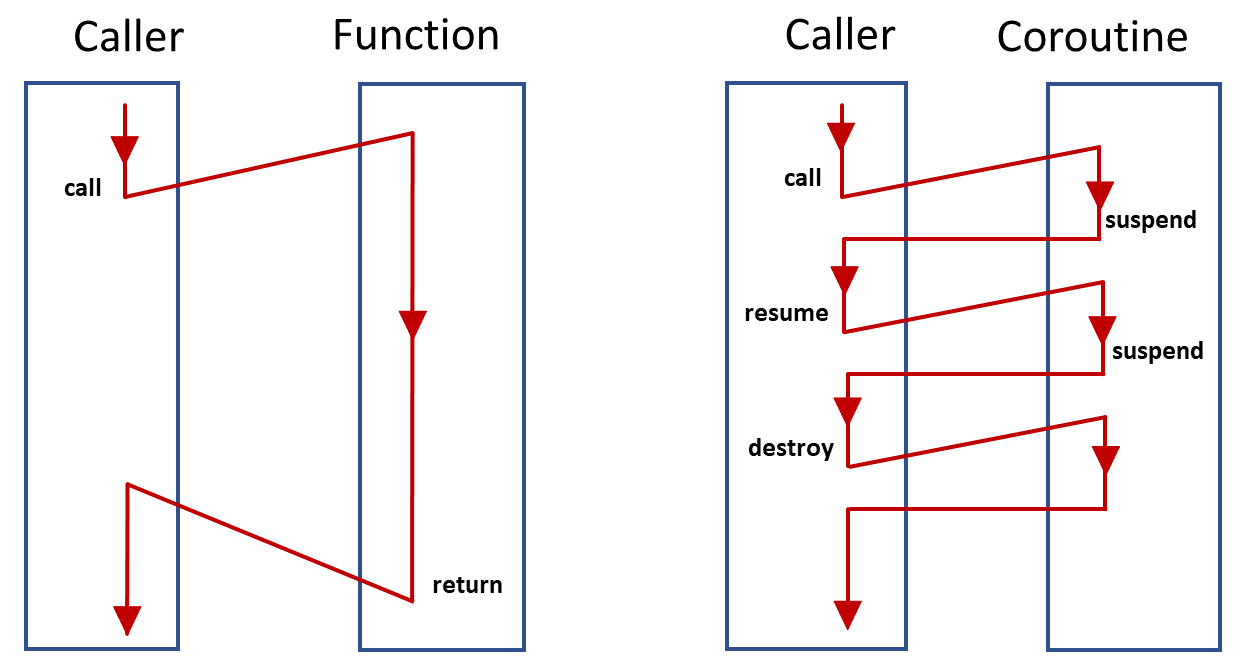
而操作系统提供给我们的系统级线程原语是不支持这种特性的,因此协程库一般会把协程调度的工作放到用户态来做,因此可以认为协程是用户态的线程
协程的优势
支持以同步的形式实现异步的执行逻辑,以解决事件驱动代码( 不管是使用 Reactor 还是 Proactor 模式 )中的回调地狱
比如在 asio 中,我们往往会写出这样形式的代码
func() {
socket_.async_read(read_buffer, read_callback);
}
read_callback() {
// 处理消息
socket_.async_write(write_buffer, write_callback);
}
write_callback() {
// ...
}
应用程序的整体逻辑散落在各种回调函数里,使得代码可读性很差
使用协程改造后的代码将看起来和使用同步阻塞 IO 的代码结构相同
func() {
read(read_buffer);
// 处理消息
write(write_buffer);
//...
}
对称和非对称
对称协程是指协程可以不受限制地将控制权交给其他任何协程
非对称协程中存在调用方和被调用方的关系,它的控制流转换是堆栈式的,调用方可以拉起被调用方并将控制权交给它,被调用方挂起的时候,控制权又交还给了调用方
Moura, A. L., Ierusalimschy R. 2004. Revisiting Coroutines. 证明了对称协程和非对称协程有等价的表达力,且一种类型可以转换为另外一种类型
libco 中的协程是非对称协程,通过 co_resume() 可以拉起一个协程,通过 co_yield_ct() 将控制权还给调用方
那么问题在于调用链头部的协程(它可能是我们在 main 函数里创建的第一个协程),它挂起的时候,执行权应该交给谁?
初始化协程的运行环境时,会隐式的创建一个协程,我们称它为主协程,我们一般会在主协程里运行 epoll 事件循环,调用链头部协程挂起时控制权就会交到主协程手里
协程栈
Libco 是有栈协程,有两种栈模式
- 独立栈
- 每个协程有自己的栈
- 共享栈
- 一组协程共享一个运行栈
- 栈由运行中的协程持有
- 当协程被换下时,将它使用掉的栈内存保存到一个缓冲区里
- 等再次换上它运行时,再把之前保存下来的栈拷贝到共享的栈空间里
共享栈的缺点
- 栈地址不可跨协程使用
- 每次协程切换都要拷贝,消耗 CPU
libco 默认使用独立栈,但也支持共享栈
对独立栈浪费内存的说法保持质疑,malloc 申请的是虚拟地址空间,只有读写时才会引发缺页中断,从而分配物理内存,因此内存申请不等于内存分配,内存只在实际用到的时候才会被分配
hook 机制
关于 Hook 机制的实现原理请看这篇
协程的最佳调度时机
协程调度的目标是为了解决 CPU 利用率与 I/O 利用率不平衡的问题,反映在同步代码中也就是阻塞等待 I/O 会导致 CPU 资源浪费
因此最佳协程切换时机就是执行阻塞系统调用操作之前
那么是否需要修改所有的阻塞调用,将它们改为带协程切换的协程库接口呢?
Libco 采取的方案是利用 Library Interpositioning 的原理,在执行阻塞系统调用前自动执行协程切换
typedef ssize_t (*read_pfn_t)(int fildes, void *buf, size_t nbyte);
static read_pfn_t g_sys_read_func = (read_pfn_t)dlsym(RTLD_NEXT, "read");
通过 dlsym,将系统的阻塞 api 接口符号名改变,并提供自己的实现,在执行阻塞 I/O 前,让出执行权,等到网络事件发生或超时,再恢复该协程的执行;当然,为了支持这种设计,协程库底层肯定是需要一个事件循环来处理 I /O 事件和超时的
在协程入口函数的开始,应该调用 co_enable_hook_sys() 表示要使用 libco 的系统调用实现
事实上,co_enable_hook_sys() 只是在代表当前协程的结构体中设置了一个布尔值,即 cEnableSysHook,每次调用前会检查这个布尔值,如果没有被设置,就直接调用 glibc 的实现
ssize_t read(int fd, void *buf, size_t nbyte) {
HOOK_SYS_FUNC(read);
if (!co_is_enable_sys_hook()) {
return g_sys_read_func(fd, buf, nbyte);
}
// ......
}
要注意的是,libco 只对套接字的 I/O 做了异步化改造,执行文件 I/O 仍然会阻塞当前线程
协程和线程
libco 中协程和线程是绑定的,也就是说不提供协程在线程间的迁移操作
线程中的所有协程是串行执行的,当某个协程主动挂起或,执行“阻塞”操作时,执行权会被交给其他协程
代表协程的实体是 stCoRoutine_t,可以称它为协程控制块
struct stCoRoutine_t {
stCoRoutineEnv_t *env;
pfn_co_routine_t pfn;
void *arg;
coctx_t ctx;
char cStart;
char cEnd;
char cIsMain;
char cEnableSysHook;
char cIsShareStack;
void *pvEnv;
stStackMem_t *stack_mem;
char *stack_sp;
unsigned int save_size;
char *save_buffer;
stCoSpec_t aSpec[1024];
};
各字段的含义
- env
- 表示协程运行的环境,都会指向当前线程的一个 tls 变量
gCoEnvPerThread,因此可以将它理解为 libco 中代表线程的实体
- 表示协程运行的环境,都会指向当前线程的一个 tls 变量
- pfn 和 arg
- 入口函数和参数
- ctx
- 保存栈指针和各种寄存器(rsp、rbp 和通用寄存器)
- pvEnv
- 保存环境变量
- stack_mem
- 协程栈
- aSpec
- 协程局部存储数据
- cIsMain
- 是否是主协程
- cEnableSysHook
- 是否启用系统调用 hook
- cIsShareStack
- 是否使用共享栈
- stack_sp、save_size、save_buffer
- 由共享栈使用
- cStart、cEnd
- 协程状态
协程运行环境
struct stCoRoutineEnv_t {
stCoRoutine_t *pCallStack[128];
int iCallStackSize;
stCoEpoll_t *pEpoll;
stCoRoutine_t *pending_co;
stCoRoutine_t *occupy_co;
};
在 pCallStack 数组中我们维护了一份协程的调用关系链,iCallStackSize 是当前正在运行的协程的下标+1
pEpoll 字段存放事件循环和定时器相关的信息
pending_co 和 occupy_co 由共享栈使用
之前说过,每个线程都有一份 stCoRoutineEnv_t 对象,在线程第一次创建协程时被自动创建,同时也会创建主协程,并将指向主协程的指针放到 pCallStack[0] 里
创建协程
调用 co_create 创建一个 stCoRoutine_t
int co_create(stCoRoutine_t **ppco,
const stCoRoutineAttr_t *attr,
pfn_co_routine_t pfn,
void *arg);
attr 可以指定新创建协程的属性,比如栈大小,是否使用共享栈
pfn 和 arg 是新创建协程的入口函数和参数
co_create 里会为协程分配栈,虽然叫栈,但其实是调用 malloc 在堆上分配的一块内存,默认的栈大小是 128kb
运行协程
co_create 只是创建了协程,要将控制权交给它,还需要调用 co_resume
void co_resume(stCoRoutine_t *co);
初始化上下文
协程第一次运行时,co_resume 会调用 coctx_make 为协程创建上下文,即初始化 stCoRoutine_t 中的 ctx 字段,将协程的入口函数放进去
//-------------
// 64 bit
// low | regs[0]: r15 |
// | regs[1]: r14 |
// | regs[2]: r13 |
// | regs[3]: r12 |
// | regs[4]: r9 |
// | regs[5]: r8 |
// | regs[6]: rbp |
// | regs[7]: rdi |
// | regs[8]: rsi |
// | regs[9]: ret | //ret func addr
// | regs[10]: rdx |
// | regs[11]: rcx |
// | regs[12]: rbx |
// hig | regs[13]: rsp |
enum {
kRDI = 7,
kRSI = 8,
kRETAddr = 9,
kRSP = 13,
};
struct coctx_t
{
#if defined(__i386__)
void *regs[ 8 ];
#else
void *regs[ 14 ];
#endif
size_t ss_size;
char *ss_sp;
};
64 位下,初始化就是将入口函数的地址放到 ctx->regs[kRETAddr] 中,协程切换的时候会用到它
协程切换
将新协程记录到协程调用栈,即 pCallStack 中后,会执行协程上下文切换,将执行权交给新协程,协程切换通过 co_swap 来进行
void co_swap(stCoRoutine_t *curr, stCoRoutine_t *pending_co);
curr 是现在正在运行的协程,pending_co 是要换上来运行的协程
真正的上下文切换是通过汇编函数 coctx_swap 来进行的
void coctx_swap(coctx_t *, coctx_t *) asm("coctx_swap");
这里我们看 64 位下的汇编
leaq (%rsp),%rax
movq %rax, 104(%rdi)
movq %rbx, 96(%rdi)
movq %rcx, 88(%rdi)
movq %rdx, 80(%rdi)
movq 0(%rax), %rax
movq %rax, 72(%rdi)
movq %rsi, 64(%rdi)
movq %rdi, 56(%rdi)
movq %rbp, 48(%rdi)
movq %r8, 40(%rdi)
movq %r9, 32(%rdi)
movq %r12, 24(%rdi)
movq %r13, 16(%rdi)
movq %r14, 8(%rdi)
movq %r15, (%rdi)
xorq %rax, %rax
movq 48(%rsi), %rbp
movq 104(%rsi), %rsp
movq (%rsi), %r15
movq 8(%rsi), %r14
movq 16(%rsi), %r13
movq 24(%rsi), %r12
movq 32(%rsi), %r9
movq 40(%rsi), %r8
movq 56(%rsi), %rdi
movq 80(%rsi), %rdx
movq 88(%rsi), %rcx
movq 96 (%rsi), %rbx
leaq 8 (%rsp), %rsp
pushq 72 (%rsi)
movq 64(%rsi), %rsi
ret
64 位的 Linux 中,第一个参数通过 rdi 来传,第二个参数通过 rsi 来传,这里可以看到我们先将当前的各种寄存器装到第一个参数中,再将第二个参数中的内容装到寄存器中
注意最后的 pushq 语句,我们会把调用栈里的返回地址改为之前保存的返回地址,这样 ret 后,控制流就跳到要换上来的协程去了
可以看到 Libco 是不保存浮点运算环境的,暂时我还不知道这样设计会造成什么后果,但 FPU(浮点运算器)和 MXCSR(控制状态寄存器) 事实上很少在服务器端编程中被使用,如果需要能保存浮点运算环境的用户态上下文切换实现,可以考虑 boost::context
协程挂起
协程调用 co_yield,可以把自己挂起,虽然 libco 提供了几种形式的 co_yield,但由于它是非对称协程,挂起后控制权总是会交给调用栈上一级的协程
co_yield 的工作非常简单,就是从 pCallStack 取出上一级的协程,然后调 co_swap 做上下文切换
共享栈
共享栈用 stShareStack_t 结构体表示,它其实是一组共享栈,每个栈由 stStackMem_t 结构体表示
struct stShareStack_t {
unsigned int alloc_idx;
int stack_size;
int count;
stStackMem_t **stack_array;
};
struct stStackMem_t {
stCoRoutine_t *occupy_co;
int stack_size;
char *stack_bp;
char *stack_buffer;
};
stack_array 表示 count 个栈大小为 stack_size 的共享栈
alloc_idx 由共享栈分配时使用
occupy_co 是当前正在使用该共享栈的进程,stack_buffer 是共享栈的内存,由于堆是由低地址向高地址增长,但栈是由高地址向低地址增长,因此要用一个 stack_bp 指向栈底
stack_mem->stack_bp = stack_mem->stack_buffer + stack_size;
分配共享栈
创建一个使用共享栈的协程前需要先分配共享栈
stShareStack_t *co_alloc_sharestack(int count, int stack_size);
这里面就是简单的动态内存分配,不再赘述了
如果在创建协程的时候,指定了 attr 参数中的 share_stack 字段,说明要使用共享栈
struct stCoRoutineAttr_t {
int stack_size;
stShareStack_t *share_stack;
stCoRoutineAttr_t() {
stack_size = 128 * 1024;
share_stack = NULL;
}
} __attribute__((packed));
使用共享栈
新创建的协程会从 share_stack 的一组栈里选择一个作为它的共享栈
static stStackMem_t *co_get_stackmem(stShareStack_t *share_stack) {
if (!share_stack) {
return NULL;
}
int idx = share_stack->alloc_idx % share_stack->count;
share_stack->alloc_idx++;
return share_stack->stack_array[idx];
}
可以看出来是使用轮询的方式来选择使用哪个栈,alloc_idx 记录目前轮询到的下标
保存共享栈
之前说过,共享栈在切换时,需要保存并恢复协程栈,具体的操作发生在 co_swap 中
env->pending_co = pending_co;
stCoRoutine_t *occupy_co = pending_co->stack_mem->occupy_co;
pending_co->stack_mem->occupy_co = pending_co;
env->occupy_co = occupy_co;
if (occupy_co && occupy_co != pending_co) {
save_stack_buffer(occupy_co);
}
判断协程所使用的共享栈是否在被其他协程使用,如果是,就需要保存共享栈里的内容,这里做的就是在协程控制块中的 save_buffer 分配一块内存,把共享栈里现在已经使用的内容拷贝到里面
void save_stack_buffer(stCoRoutine_t *occupy_co) {
/// copy out
stStackMem_t *stack_mem = occupy_co->stack_mem;
int len = stack_mem->stack_bp - occupy_co->stack_sp;
if (occupy_co->save_buffer) {
free(occupy_co->save_buffer), occupy_co->save_buffer = NULL;
}
occupy_co->save_buffer = (char *)malloc(len); // malloc buf;
occupy_co->save_size = len;
memcpy(occupy_co->save_buffer, occupy_co->stack_sp, len);
}
恢复共享栈
stCoRoutineEnv_t *curr_env = co_get_curr_thread_env();
stCoRoutine_t *update_occupy_co = curr_env->occupy_co;
stCoRoutine_t *update_pending_co = curr_env->pending_co;
if (update_occupy_co && update_pending_co &&
update_occupy_co != update_pending_co) {
if (update_pending_co->save_buffer &&
update_pending_co->save_size > 0) {
memcpy(update_pending_co->stack_sp,
update_pending_co->save_buffer,
update_pending_co->save_size);
}
}
等执行权交回协程后,它需要恢复自己栈里的内容,这时候也需要执行一次拷贝操作
epoll 事件循环
主协程一般创建完其他协程后就会进入 epoll 事件循环,即 co_eventloop()
void co_eventloop(stCoEpoll_t *ctx, pfn_co_eventloop_t pfn, void *arg)
事件循环相关的信息放在 stCoEpoll_t 结构体中
struct stCoEpoll_t {
int iEpollFd;
static const int _EPOLL_SIZE = 1024 * 10;
struct stTimeout_t *pTimeout;
struct stTimeoutItemLink_t *pstTimeoutList;
struct stTimeoutItemLink_t *pstActiveList;
co_epoll_res *result;
};
各字段的含义
iEpollFd- epoll 描述符
_EPOLL_SIZE- 被用作
epoll_wait的参数 - 即一次最多返回的就绪描述符数
- 被用作
pTimeout- 时间轮定时器
pstTimeoutList- 存放定时器超时事件的链表
pstActiveList- 存放已触发和已超时的 epoll 事件的链表
result- 由于要支持 kevent 调用,它的事件结构体和 epoll 是不同的
- 因此将事件循环的结果封装为了 co_epoll_res 结构体
- 事实上,libco 把所有的 kevent 接口都封装成了和 epoll 相同的接口
定时器设计
libco 通过 epoll 实现了一个时间轮定时器,因此该定时器的精度是 1ms
struct stTimeout_t {
stTimeoutItemLink_t *pItems;
int iItemSize;
unsigned long long ullStart;
long long llStartIdx;
};
struct stTimeoutItemLink_t {
stTimeoutItem_t *head;
stTimeoutItem_t *tail;
};
typedef void (*OnPreparePfn_t)(stTimeoutItem_t *,
struct epoll_event &ev,
stTimeoutItemLink_t *active);
typedef void (*OnProcessPfn_t)(stTimeoutItem_t *);
struct stTimeoutItem_t {
enum {
eMaxTimeout = 40 * 1000 // 40s
};
stTimeoutItem_t *pPrev;
stTimeoutItem_t *pNext;
stTimeoutItemLink_t *pLink;
unsigned long long ullExpireTime;
OnPreparePfn_t pfnPrepare;
OnProcessPfn_t pfnProcess;
void *pArg; // routine
bool bTimeout;
};
libco 的时间轮,事实上是长度为 iItemSize 的环形数组,即 pItems
- 数组的每个元素都是一个定时事件(
stTimeoutItem_t)双向链表 - iItemSize 的默认大小是
60 * 1000,也就是时间轮转一圈是一分钟 - ullStart 是最近超时时间的时间戳
- llStartIdx 是最近超时时间在时间轮数组中的 index
定时事件结构体 stTimeoutItem_t
- ullExpireTime
- 定时事件的超时时间
- pfnPrepare 和 pfnProcess
- 预处理和处理回调函数
插入事件到时间轮中
unsigned long long diff = apItem->ullExpireTime - apTimeout->ullStart;
if (diff >= (unsigned long long)apTimeout->iItemSize) {
diff = apTimeout->iItemSize - 1;
}
AddTail(apTimeout->pItems +
(apTimeout->llStartIdx + diff) % apTimeout->iItemSize,
apItem);
我们会计算事件超时时间和最近超时时间的时间差以确定它在时间轮中的插入位置
可以看到对于时间差超过一分钟的事件,我们直接将它插到了一分钟后超时的位置上,在 epoll 循环里检查到事件没超时,会把它再插回时间轮里
超时事件插入到时间轮里的复杂度是 O(1)
取出所有超时事件
int cnt = allNow - apTimeout->ullStart + 1;
if (cnt > apTimeout->iItemSize) {
cnt = apTimeout->iItemSize;
}
if (cnt < 0) {
return;
}
for (int i = 0; i < cnt; i++) {
int idx = (apTimeout->llStartIdx + i) % apTimeout->iItemSize;
Join<stTimeoutItem_t, stTimeoutItemLink_t>(apResult, apTimeout->pItems + idx);
}
apTimeout->ullStart = allNow;
apTimeout->llStartIdx += cnt - 1;
根据当前事件和最近超时时间的差值,可以取出全部的超时事件的链表,然后接到结果链表后面,最后需要更新最近超时时间和 index
取出超时事件的复杂度是 O(1)
epoll 主循环
在死循环里
- 调用
epoll_wait - 遍历
epoll_wait的结果- 通过
epoll_event中的 data 字段我们可以拿到超时事件(stTimeoutItem_t类型 )的指针 - 如果超时事件提供了预处理回调函数 pfnPrepare,就调用它
- 在预处理回调函数中,它可能会将自己从定时器中移除,因为事件已经发生了
- 否则插入 pstActiveList,稍后统一处理
- 通过
- 从时间轮中取出所有超时事件,放到 pstActiveList 中
- 需要比对当前时间和超时事件的 ullExpireTime 字段,对于那些尚未超时的,将它们再添加回定时器里
- 处理 pstActiveList 中的所有事件,调用它们的回调函数 pfnProcess
对阻塞系统调用的改造
libco 会利用 hook 机制改变阻塞系统 api 的实现,比如 libco 提供的 socket 实现,会将套接字变为非阻塞的
poll
libco 对系统 api 改造的中心是 poll,它会将 poll 改造成 epoll(Linux)或 kevent(APPLE 或 FreeBSD)
具体来说,协程中的 poll 调用都会被加到 epoll 主循环监听的事件列表中,然后协程就会让出执行权,等事件被触发或定时器超时,在回调函数中我们会唤起对应的协程运行,从 poll 调用中返回
由于 poll 和 epoll 在接口上存在差异,因此我们引用几个结构体来做接口转换
struct stPoll_t : public stTimeoutItem_t {
struct pollfd *fds;
nfds_t nfds; // typedef unsigned long int nfds_t;
stPollItem_t *pPollItems;
int iAllEventDetach;
int iEpollFd;
int iRaiseCnt;
};
struct stPollItem_t : public stTimeoutItem_t {
struct pollfd *pSelf;
stPoll_t *pPoll;
struct epoll_event stEvent;
};
stPoll_t 表示一次 poll 调用
- 包含一个长度为 nfds 的 stPollItem_t 数组,每个元素表示 poll 监听的一个 fd
- iRaiseCnt
- 作为 poll 的返回值,记录这次调用中触发的事件
stPollItem_t
- stEvent
- 用来存放转换后的 poll 事件
poll 的主要逻辑在 co_poll_inner() 中
- 构造一个 stPoll_t 对象
- 设置它的 pfnProcess 回调
- 事件被触发或超时发生时,会通过回调恢复该协程的运行
- 设置它的 pfnProcess 回调
- 遍历 poll 的 fds 参数
- 将 poll 事件转换为 epoll 事件
- 为每个 stPollItem_t 设置预处理回调函数
- 回调函数中会将 epoll 事件转换为 poll 事件
- 累加 iRaiseCnt
- 如果是 stPoll_t 中第一个被触发的事件(由 iAllEventDetach 字段来判别)
- 从定时器中删除该事件,并将事件加到 pstActiveList 中
- 调用
epoll_ctl使得主 epoll 监听该描述符
- 将 stPoll_t 对象挂到定时器上去
- 让出执行权
socket
libco 的 socket 会调用 fcntl 给套接字加上 O_NONBLOCK 标志,并创建一个 rpchook_t 对象,将套接字原始的 flag 存在它的 user_flag 字段里
有一个全局的 g_rpchook_socket_fd,将 fd 映射到它对应的 rpchook_t
对象上去,这样执行 api 前可以先判断套接字本身是不是原本就是非阻塞的,如果是,直接调用系统 api 即可,不用再走 libco 自己的封装
static rpchook_t *g_rpchook_socket_fd[102400] = {0};
struct rpchook_t {
int user_flag;
struct sockaddr_in dest; // maybe sockaddr_un;
int domain; // AF_LOCAL , AF_INET
struct timeval read_timeout;
struct timeval write_timeout;
};
read_timeout 和 write_timeout
- 会作为读写操作的超时值
- 默认情况下都是 1s
- 如果调用
setsockopt设置SO_RCVTIMEO或SO_SNDTIMEO,libco 实现的 setsockopt 会将参数的值拷贝给这两个字段
read、write
struct pollfd pf = {0};
pf.fd = fd;
pf.events = (POLLIN | POLLERR | POLLHUP);
int pollret = poll(&pf, 1, timeout);
ssize_t readret = g_sys_read_func(fd, (char *)buf, nbyte);
读操作就是将描述符可读事件注册进事件循环
ssize_t writeret =
g_sys_write_func(fd, (const char *)buf + wrotelen, nbyte - wrotelen);
if (writeret == 0) {
return writeret;
}
if (writeret > 0) {
wrotelen += writeret;
}
while (wrotelen < nbyte) {
struct pollfd pf = {0};
pf.fd = fd;
pf.events = (POLLOUT | POLLERR | POLLHUP);
poll(&pf, 1, timeout);
writeret =
g_sys_write_func(fd, (const char *)buf + wrotelen,
nbyte - wrotelen);
if (writeret <= 0) {
break;
}
wrotelen += writeret;
}
写操作在循环里执行
- 将描述符可写事件注册进事件循环
- 在描述符可写时执行非阻塞写
- 直到写够了 write 要求的字节
connect
在非阻塞的描述符上 connect,正常情况下会返回 EINPROGRESS 错误
将描述符的可写事件注册进事件循环,connect 成功和出错时,都会触发套接字可写事件,这时候就需要使用 getsockopt 来检查 SO_ERROR,确认是成功还是失败
文件 I/O
由于文件 I/O 不能通过 epoll 来管理,因此 Libco 并没有提供文件异步化的相关接口,自己实现文件 I/O 异步化有两类思路
- 异步文件线程池方式
- 工作协程把任务托管给异步线程池
- 然后自己 yield 让出执行权
- 异步线程池负责读写磁盘
- 读写完成后再唤醒发起读写操作的协程
- 工作协程把任务托管给异步线程池
- 通过 Direct I/O 的方式在本线程完成异步文件读写
- Linux AIO 接口只支持直接 IO
- 缺点
- 因 Direct I/O 要求页对齐,所以使用 Direct I/O 的方式会多读或多写数据
- Direct I/O 无 FileCache,需要业务实现缓存与预读策略
同步原语
条件变量
struct stCoCond_t;
struct stCoCondItem_t {
stCoCondItem_t *pPrev;
stCoCondItem_t *pNext;
stCoCond_t *pLink;
stTimeoutItem_t timeout;
};
struct stCoCond_t {
stCoCondItem_t *head;
stCoCondItem_t *tail;
};
int co_cond_timedwait(stCoCond_t *link, int ms);
int co_cond_signal(stCoCond_t *si);
int co_cond_broadcast(stCoCond_t *si);
libco 的条件变量事实上就是一个等待队列
co_cond_timedwait 就是创建一个超时事件,设置定时器,并将它加到条件变量的等待队列中,然后让出执行权
co_cond_broadcast 和 co_cond_signal 就是从等待队列中取出超时事件,将它加到主 epoll 的 pstActiveList 上
本文来自博客园,作者:路过的摸鱼侠,转载请注明原文链接:https://www.cnblogs.com/ljx-null/p/15928889.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号